【今日CV 视觉论文速览】03 Dec 2018
今日CS.CV计算机视觉论文速览
Mon, 3 Dec 2018
Totally 41 papers

Interesting:
- Semantic Sub-style Transfer提出了一种新的风格迁移方法,将风格分为多个子模块,更好地描述风格的细节(或使用不同的细节及其组合)。其优势在于:可以在一副图像中得到广泛的风格表示,自动化的为内容图像不同区域匹配不同的子风格,检测并使用现存方法的子风格。(from Aristotle University)
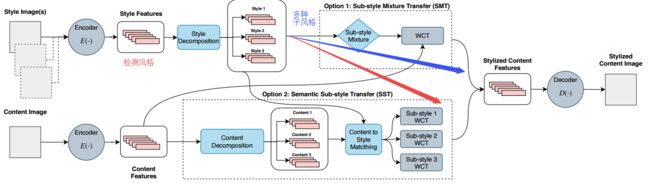
内容和风格的解构:

结果:




-
L3C,提出了第一个实用化的学习无损图像压缩系统,其核心在于应用了完全并行化的分层概率模型,自适应熵编码,优化了端到端的压缩任务。图像分布于辅助表示联合,只需要三个前向通道来预测所有像素。(from 苏黎世理工)

其中E为抽取器、Q为量化器、z为层级特征表示,其与图像的联合概率分布利用了D来描述。f总结slevel上的了信息。详细如下图所示:

-
基于图像自适应CNN去噪器的超分辨, 在test时利用了内部学习和泛化训练数据的方法来解决训练数据和真实数据不匹配的问题。Plug-and-play方法是一种解决的手段,另一种方法是训练单张图片中的回归信息来实现,这篇文章结合了p&P方法以及图像自适应的方法来实现超分辨(from 特拉维夫大学)

-
从单张图片中学习出多种光照情况,这以工作可以分离出单张图像中不同光谱情况下的场景,并生成两幅新的在不同光照下的图(实现了shading和shadow)。
通过训练DNN对每一个像素预测场景的反射色度,并结合前述的基于图像的算法来生成最后的输出。通过ChromNet预测反射色度、shadingNet预测阴影,分离网络实现最后输出。(from CMU 华盛顿大学 Adobe)
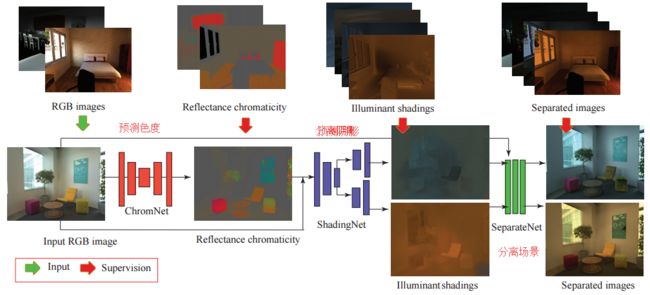
反射色度神经网络结合了成像过程中的物理原理。
-
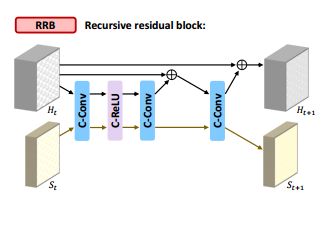
[轻量级图像超分辨],基于块状态的回归网络最大化回归结构的作用来减少网络参数。通过block stack可以追踪当前特征的状态,在模型大小、效率和速度上 都有了明显提升。(from 延世大学)
code
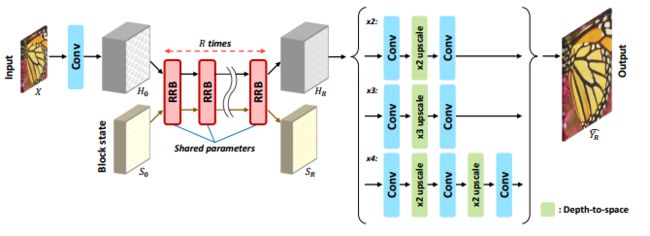
RRB的结构和网络表现,其中包含了status层记录状态。:
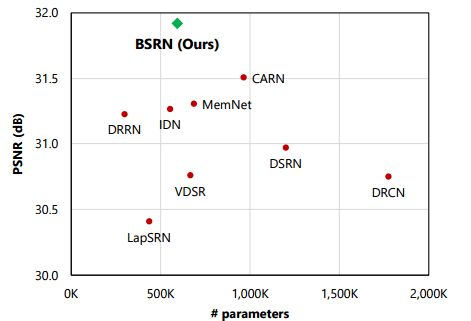
-
PressNET ,利用视频中抽取的人体姿态25关节点来预测足底压力分布(from 宾大)

基于足底压力的稳定分析:
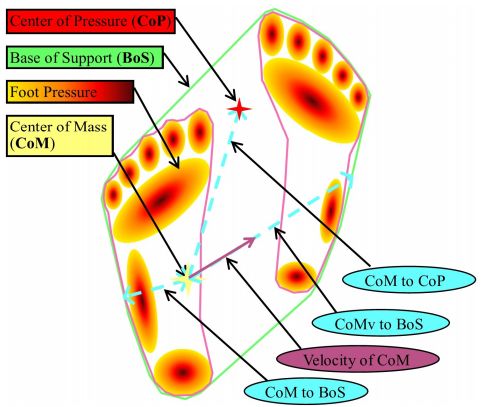
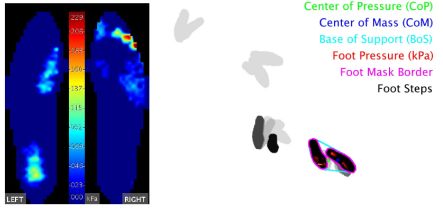
-
利用转导深度迁移学习架构实现跨数据集的非正脸表情识别(from 东南大学)
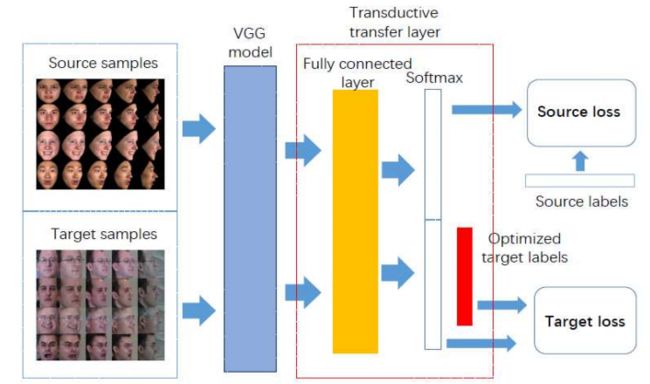
-
提出了一种获取全局rank配置的高效神经网络压缩方法(SVD-Based),并提出了新的度量神经网络精度和复杂度相关性的方式 (from KAIST)。
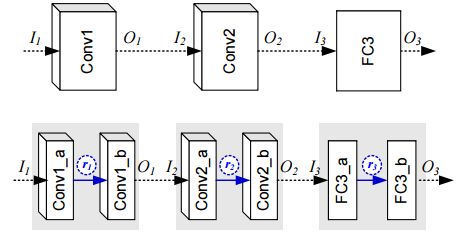
结合空间生成和目标复杂度:
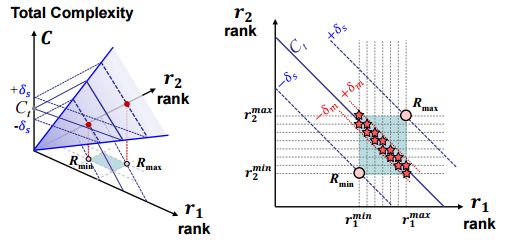
-
基于Faster R-CNN的手语识别 (from 阿赫萨努拉科技大学)
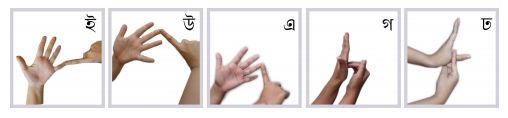
-
卷积层隐含层滤波器的稀疏性,实验主要发现了以下观点:正则化时没有稀疏性、随着L2或者权重衰减稀疏性增加;自适应方法(Adam,Adagrad,Adadelta)比SGD学习更稀疏的表示;对于Adam,L2比权重衰减的稀疏性更高。(from MPI, 巴斯大学 Saarland Informatics Campus)

-
Projection Convolutional Neural Networks (PCNNs),通过投射离散的方向传播来改善二进制网络的性能。利用投影函数解决离散bp问题,探索了多种投影过程,学习了一系列量化核压缩。(from 北航)
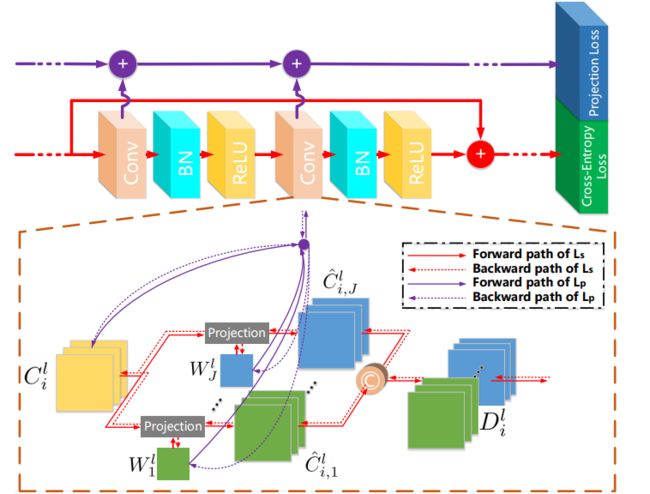
lab:http://mpl.buaa.edu.cn/people.htm -
DeepFlux,提出了一种基于流的骨架检测方法,通过训练CNN 预测二维矢量场,并映射到对应的骨架像素上,具有编码清晰、语义信息明确和region-based的优点。(from 华中科技 多伦多大学 & McGill U)
网络模型如下所示:
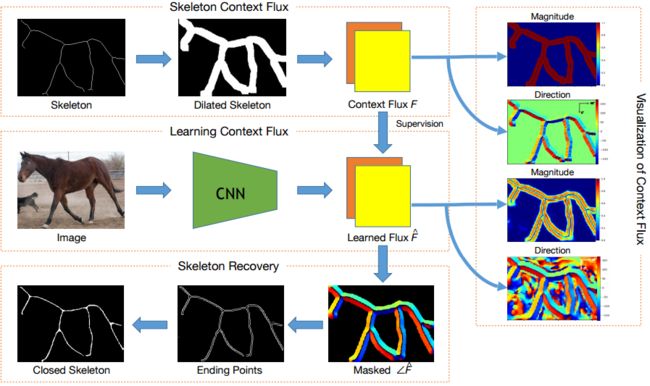

结果:

Daily Computer Vision Papers
[1] Title: Super-Resolution based on Image-Adapted CNN Denoisers: Incorporating Generalization of Training Data and Internal Learning in Test Time
Authors:Tom Tirer, Raja Giryes
[2] Title: ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation
Authors:Tuan-Hung Vu, Himalaya Jain, Maxime Bucher, Mathieu Cord, Patrick Pérez
[3] Title: Practical Full Resolution Learned Lossless Image Compression
Authors:Fabian Mentzer, Eirikur Agustsson, Michael Tschannen, Radu Timofte, Luc Van Gool
[4] Title: Graph-Based Global Reasoning Networks
Authors:Yunpeng Chen, Marcus Rohrbach, Zhicheng Yan, Shuicheng Yan, Jiashi Feng, Yannis Kalantidis
[5] Title: Real Time Bangladeshi Sign Language Detection using Faster R-CNN
Authors:Oishee Bintey Hoque, Mohammad Imrul Jubair, Md. Saiful Islam, Al-Farabi Akash, Alvin Sachie Paulson
[6] Title: Structure and Motion from Multiframes
Authors:Mieczysław A. Kłopotek
[7] Title: iW-Net: an automatic and minimalistic interactive lung nodule segmentation deep network
Authors:Guilherme Aresta, Colin Jacobs, Teresa Araújo, António Cunha, Isabel Ramos, Bram van Ginneken, Aurélio Campilho
[8] Title: TextMountain: Accurate Scene Text Detection via Instance Segmentation
Authors:Yixing Zhu, Jun Du
[9] Title: The GAN that Warped: Semantic Attribute Editing with Unpaired Data
Authors:Garoe Dorta, Sara Vicente, Neill D.F. Campbell, Ivor Simpson
[10] Title: A Framework for Fast and Efficient Neural Network Compression
Authors:Hyeji Kim, Muhammad Umar Karim, Chong-Min Kyung
[11] Title: Cross-database non-frontal facial expression recognition based on transductive deep transfer learning
Authors:Keyu Yan (1 and 2)Wenming Zheng (1 and 2), Tong Zhang (1 and 2), Yuan Zong (1), Zhen Cui (3) ((1) the Key Laboratory of Child Development and Learning Science of Ministry of Education, and the Department of Information Science and Engineering, Southeast University, China. (2) the Key Laboratory of Child Development and Learning Science of Ministry of Education, Research Center for Learning Science, Southeast University, Nanjing, Jiangsu, China. (3) School of Computer Science and Engineering, Nanjing University of Science and Technology, Nanjing, Jiangsu, China)
[12] Title: From Known to the Unknown: Transferring Knowledge to Answer Questions about Novel Visual and Semantic Concepts
Authors:Moshiur R Farazi, Salman H Khan, Nick Barnes
[13] Title: Model-blind Video Denoising Via Frame-to-frame Training
Authors:Thibaud Ehret, Axel Davy, Gabriele Facciolo, Jean-Michel Morel, Pablo Arias
[14] Title: Non-Local Video Denoising by CNN
Authors:Axel Davy, Thibaud Ehret, Gabriele Facciolo, Jean-Michel Morel, Pablo Arias
[15] Title: Projection Convolutional Neural Networks for 1-bit CNNs via Discrete Back Propagation
Authors:Jiaxin Gu, Ce Li, Baochang Zhang, Jungong Han, Xianbin Cao, Jianzhuang Liu, David Doermann
[16] Title: Domain-Invariant Adversarial Learning for Unsupervised Domain Adaption
Authors:Yexun Zhang, Ya Zhang, Yanfeng Wang, Qi Tian
[17] Title: Improving Landmark Recognition using Saliency detection and Feature classification
Authors:Akash Kumar, Sagnik Bhowmick, N. Jayanthi, S. Indu
[18] Title: Evaluating Bayesian Deep Learning Methods for Semantic Segmentation
Authors:Jishnu Mukhoti, Yarin Gal
[19] Title: Style Decomposition for Improved Neural Style Transfer
Authors:Paraskevas Pegios, Nikolaos Passalis, Anastasios Tefas
[20] Title: An Efficient Image Retrieval Based on Fusion of Low-Level Visual Features
Authors:Atif Nazir, Kashif Nazir
[21] Title: ComDefend: An Efficient Image Compression Model to Defend Adversarial Examples
Authors:Xiaojun Jia, Xingxing Wei, Xiaochun Cao, Hassan Foroosh
[22] Title: Instance-level Facial Attributes Transfer with Geometry-Aware Flow
Authors:Weidong Yin, Ziwei Liu, Chen Change Loy
[23] Title: FSNet: An Identity-Aware Generative Model for Image-based Face Swapping
Authors:Ryota Natsume, Tatsuya Yatagawa, Shigeo Morishima
[24] Title: Making Classification Competitive for Deep Metric Learning
Authors:Andrew Zhai, Hao-Yu Wu
[25] Title: Transferable Adversarial Attacks for Image and Video Object Detection
Authors:Xingxing Wei, Siyuan Liang, Xiaochun Cao, Jun Zhu
[26] Title: Towards Robust Lung Segmentation in Chest Radiographs with Deep Learning
Authors:Jyoti Islam, Yanqing Zhang
[27] Title: Virtual Class Enhanced Discriminative Embedding Learning
Authors:Binghui Chen, Weihong Deng, Haifeng Shen
[28] Title: DeepFlux for Skeletons in the Wild
Authors:Yukang Wang, Yongchao Xu, Stavros Tsogkas, Xiang Bai, Sven Dickinson, Kaleem Siddiqi
[29] Title: Foot Pressure from Video: A Deep Learning Approach to Predict Dynamics from Kinematics
Authors:Savinay Nagendra, Christopher Funk, Robert T. Collins, Yanxi Liu
[30] Title: Parsing R-CNN for Instance-Level Human Analysis
Authors:Lu Yang, Qing Song, Zhihui Wang, Ming Jiang
[31] Title: Deep Multimodal Learning: An Effective Method for Video Classification
Authors:Tianqi Zhao
[32] Title: Lightweight and Efficient Image Super-Resolution with Block State-based Recursive Network
Authors:Jun-Ho Choi, Jun-Hyuk Kim, Manri Cheon, Jong-Seok Lee
[33] Title: 3D Semi-Supervised Learning with Uncertainty-Aware Multi-View Co-Training
Authors:Yingda Xia, Fengze Liu, Dong Yang, Jinzheng Cai, Lequan Yu, Zhuotun Zhu, Daguang Xu, Alan Yuille, Holger Roth
[34] Title: Playing Soccer without Colors in the SPL: A Convolutional Neural Network Approach
Authors:Francisco Leiva, Nicolás Cruz, Ignacio Bugueño, Javier Ruiz-del-Solar
[35] Title: Leveraging Deep Stein’s Unbiased Risk Estimator for Unsupervised X-ray Denoising
Authors:Fahad Shamshad, Muhammad Awais, Muhammad Asim, Zain ul Aabidin Lodhi, Muhammad Umair, Ali Ahmed
[36] Title: Learning to Separate Multiple Illuminants in a Single Image
Authors:Zhuo Hui, Ayan Chakrabarti, Kalyan Sunkavalli, Aswin C. Sankaranarayanan
[37] Title: Fast and Flexible Indoor Scene Synthesis via Deep Convolutional Generative Models
Authors:Daniel Ritchie, Kai Wang, Yu-an Lin
[38] Title: AdaFrame: Adaptive Frame Selection for Fast Video Recognition
Authors:Zuxuan Wu, Caiming Xiong, Chih-Yao Ma, Richard Socher, Larry S. Davis
[39] Title: Void Filling of Digital Elevation Models with Deep Generative Models
Authors:Konstantinos Gavriil, Georg Muntingh, Oliver J. D. Barrowclough
[40] Title: Are All Training Examples Created Equal? An Empirical Study
Authors:Kailas Vodrahalli, Ke Li, Jitendra Malik
[41] Title: On Implicit Filter Level Sparsity in Convolutional Neural Networks
Authors:Dushyant Mehta, Kwang In Kim, Christian Theobalt
Papers from arxiv.org

pic from pixels.com