导包
org.apache.hadoop
hadoop-common
2.6.4
org.apache.hadoop
hadoop-hdfs
2.6.4
org.apache.hadoop
hadoop-client
2.6.4
模板代码
以单词统计为例
1map
/**
* @Description:Mapper
* keyin valuein 在inputformat下,key是一行文本的偏移量long,value一行文本的内容String
* keyout valueout 由业务逻辑决定,如单词统计中的单词String和出现次数int
* hadoop为了提高序列化效率,自定义序列化
* java - hadoop
* Long - LongWritable
* String - Test
* Integer - IntWriteable
* null - nullWriteable
*/
public class WordCountMap extends Mapper {
/*napreduce程序中,MapTask会通过InputFormat读取数据,
*每读取一行调用一次map
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将读取到的一行内容转为String
String line = value.toString();
//根据具体情况切割,此处用空格
String[] words = line.split(" ");
for (String word:words
) {
//遍历,每一个单词计数为1,写到reduce去聚合
context.write(new Text(word),new IntWritable(1));
}
}
}
2reduce
public class WordCountReduce extends Reducer {
/**
* @Description reduce会自动将map分组计算出values 即聚合
* @param key map中写的word
* @param values 相同word的所有val
* @param context
* @return void
*/
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable v:values
) {
//将v叠加
count+=v.get();
}
//每次计算写一行
context.write(key,new IntWritable(count));
}
}
3启动
public class WorldCountDriver {
public static void main(String[] args) throws Exception {
//系统(如果没有,默认当前系统)
final Configuration conf = new Configuration();
//如果想在本机跑hdfs需要设置conf.set()
//在系统上加载任务
final Job job = Job.getInstance(conf);
//设置jar包位置(linux下执行路径非hdfs)
job.setJar("/root/wordCount.jar");
//设置map类
job.setMapperClass(WordCountMap.class);
//设置reduce类
job.setReducerClass(WordCountReduce.class);
//设置map输出的形式
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置最终输入形式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置数据读取组件
job.setInputFormatClass(TextInputFormat.class);
//设置数据输出组件
job.setOutputFormatClass(TextOutputFormat.class);
//设置读取数据的位置
FileInputFormat.setInputPaths(job,new Path("/wordCount/input"));
//设置输出数据位置
FileOutputFormat.setOutputPath(job,new Path("/wordCount/output"));
//提交
boolean result = job.waitForCompletion(true);
//成功返回0失败返回1
System.exit(result?0:1);
}
}
注:上面介绍的方法需要将文件达成jar包上传到linux上用hadoop jar xx.har pathmain执行 其实也可以在本地运行做测试,只要设置conf以及读取和输入路径即可
本机运行hadoop
1.下载hadoop压缩包,解压
2.将hadoop下bin配到系统环境Path中
本机实现几个常用案例
1倒排索引
已知:文件1,文件2,文件3中有单词,用空格隔开
求:单词在每个文件中出现的次数 即单词a 分别1,2,3中出现次数
代码:
//首先将k单词+文件名,v出现次数 输出
public class IndexOne {
//将单词+文件名作为key ,出现次数作为v输出
private static class IndexMapper extends Mapper{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
//获取文件名
final FileSplit split = (FileSplit) context.getInputSplit();
final String fileName = split.getPath().getName();
for (String word: words
) {
k.set(word+"--"+fileName);
context.write(k,v);
}
}
}
//聚合单词-文件名出现次数
private static class IndexReduce extends Reducer{
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable val:values) {
count+=val.get();
}
context.write(key,new IntWritable(count));
}
}
public static void main(String[] args) throws Exception {
//hdfs系统(如果没有,系统会自建目录)
Configuration conf = new Configuration();
/*conf.set("fs.defaultFS","hdfs://192.168.2.231:9000");*/
//在hdfs系统上配置
Job job = Job.getInstance(conf);
//设置jar包位置(linux下执行路径非hdfs)
job.setJarByClass(IndexOne.class);
//设置map类
job.setMapperClass(IndexMapper.class);
//设置reduce类
job.setReducerClass(IndexReduce.class);
//设置map输出的形式
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置最终输入形式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置数据读取组件
job.setInputFormatClass(TextInputFormat.class);
//设置数据输出组件
job.setOutputFormatClass(TextOutputFormat.class);
//局部聚合提高效率
job.setCombinerClass(IndexReduce.class);
//设置读取数据的位置
FileInputFormat.setInputPaths(job,new Path("E:\\mapReduce\\1\\input"));
//设置输出数据位置
FileOutputFormat.setOutputPath(job,new Path("E:\\mapReduce\\1\\inputoutput1"));
//提交
boolean result = job.waitForCompletion(true);
//成功返回0失败返回1
System.exit(result?0:1);
}
}
获取上次输出结果,拆分key后再聚合,输出最终结果
public class IndexTwo {
//将单词作为key,文件名+出现次数作为v输出
private static class IndexTwoMapper extends Mapper {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
final String line = value.toString();
//reduce输出用\t分割
final String[] fields = line.split("\t");
final String[] splits = fields[0].split("--");
k.set(splits[0]);
v.set(splits[1]+"-->"+fields[1]);
context.write(k,v);
}
}
//拼接单词的文件名及次数
private static class IndexTwoReduce extends Reducer{
Text v = new Text();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
StringBuffer stringBuffer = new StringBuffer();
for (Text val:values
) {
stringBuffer.append(val.toString()).append(" ");
}
v.set(stringBuffer.toString());
context.write(key,v);
}
}
public static void main(String[] args) throws Exception {
//hdfs系统(如果没有,系统会自建目录)
Configuration conf = new Configuration();
/*conf.set("fs.defaultFS","hdfs://192.168.2.231:9000");*/
//在hdfs系统上配置
Job job = Job.getInstance(conf);
//设置jar包位置(linux下执行路径非hdfs)
job.setJarByClass(IndexTwo.class);
//设置map类
job.setMapperClass(IndexTwoMapper.class);
//设置reduce类
job.setReducerClass(IndexTwoReduce.class);
//设置map输出的形式
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置最终输入形式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置数据读取组件
job.setInputFormatClass(TextInputFormat.class);
//设置数据输出组件
job.setOutputFormatClass(TextOutputFormat.class);
//局部聚合提高效率
job.setCombinerClass(IndexTwoReduce.class);
//设置读取数据的位置
FileInputFormat.setInputPaths(job,new Path("E:\\mapReduce\\1\\inputoutput1"));
//设置输出数据位置
FileOutputFormat.setOutputPath(job,new Path("E:\\mapReduce\\1\\output2"));
//提交
boolean result = job.waitForCompletion(true);
//成功返回0失败返回1
System.exit(result?0:1);
}
}
2共同好友
 需求.png
需求.png
需求.png
public class ComFriOne {
//先将用户好友全部分组
private static class ComFriMapper extends Mapper{
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split(":");
String people = fields[0];
String[] friends = fields[1].split(",");
for (String fri:friends
) {
k.set(fri);
v.set(people);
context.write(k,v);
}
}
}
//聚合相同好友下用户
private static class ComFriReduce extends Reducer{
Text v = new Text();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
final StringBuffer stringBuffer = new StringBuffer();
for (Text val:values) {
stringBuffer.append(val).append(" ");
}
v.set(stringBuffer.toString());
context.write(key,v);
}
}
public static void main(String[] args) throws Exception {
//hdfs系统(如果没有,系统会自建目录)
Configuration conf = new Configuration();
/*conf.set("fs.defaultFS","hdfs://192.168.2.231:9000");*/
//在hdfs系统上配置
Job job = Job.getInstance(conf);
//设置jar包位置(linux下执行路径非hdfs)
job.setJarByClass(ComFriOne.class);
//设置map类
job.setMapperClass(ComFriMapper.class);
//设置reduce类
job.setReducerClass(ComFriReduce.class);
//设置map输出的形式
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置最终输入形式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置数据读取组件
job.setInputFormatClass(TextInputFormat.class);
//设置数据输出组件
job.setOutputFormatClass(TextOutputFormat.class);
//局部聚合提高效率
job.setCombinerClass(ComFriReduce.class);
//设置读取数据的位置
FileInputFormat.setInputPaths(job,new Path("E:\\mapReduce\\common-freiends\\input"));
//设置输出数据位置
FileOutputFormat.setOutputPath(job,new Path("E:\\mapReduce\\common-freiends\\output1"));
//提交
boolean result = job.waitForCompletion(true);
//成功返回0失败返回1
System.exit(result?0:1);
}
}
public class ComFriTwo {
//将所有好友下的用户22组合
public static class ComFriTwoMapper extends Mapper{
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
final String[] split = line.split("\t");
String fri = split[0];
String[] peoples = split[1].split(" ");
Arrays.sort(peoples);
for (int i=0;i{
Text v = new Text();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
StringBuffer stringBuffer = new StringBuffer();
for (Text val : values) {
stringBuffer.append(val).append(" ");
}
v.set(stringBuffer.toString());
context.write(key,v);
}
}
public static void main(String[] args) throws Exception {
//hdfs系统(如果没有,系统会自建目录)
Configuration conf = new Configuration();
/*conf.set("fs.defaultFS","hdfs://192.168.2.231:9000");*/
//在hdfs系统上配置
Job job = Job.getInstance(conf);
//设置jar包位置(linux下执行路径非hdfs)
job.setJarByClass(ComFriTwo.class);
//设置map类
job.setMapperClass(ComFriTwoMapper.class);
//设置reduce类
job.setReducerClass(ComFriTwoReduce.class);
//设置map输出的形式
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置最终输入形式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置数据读取组件
job.setInputFormatClass(TextInputFormat.class);
//设置数据输出组件
job.setOutputFormatClass(TextOutputFormat.class);
//局部聚合提高效率
job.setCombinerClass(ComFriTwoReduce.class);
//设置读取数据的位置
FileInputFormat.setInputPaths(job,new Path("E:\\mapReduce\\common-freiends\\output1"));
//设置输出数据位置
FileOutputFormat.setOutputPath(job,new Path("E:\\mapReduce\\common-freiends\\output2"));
//提交
boolean result = job.waitForCompletion(true);
//成功返回0失败返回1
System.exit(result?0:1);
}
}
join实现
将2个数据组合输出
public class MyJoin {
public static class MyJoinMapper extends Mapper {
Text k = new Text();
FileReader in = null;
BufferedReader reader = null;
HashMap b_tab = new HashMap();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//初始化导入文件
in = new FileReader("E:\\mapReduce\\3\\pdts.txt");
reader = new BufferedReader(in);
String line = null;
while (StringUtils.isNotBlank((line = reader.readLine() ))){
String[] spilt = line.split(",");
String[] products = {spilt[0],spilt[1]};
b_tab.put(spilt[0],products);
}
IOUtils.closeStream(reader);
IOUtils.closeStream(in);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] orderFileds = line.split(",");
String pdt_id = orderFileds[1];
String[] pdt_field = b_tab.get(pdt_id);
k.set(orderFileds[0]+"\t"+pdt_field[1]+"\t"+orderFileds[1]+"\t"+orderFileds[2]);
context.write(k,NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
//hdfs系统(如果没有,系统会自建目录)
Configuration conf = new Configuration();
/*conf.set("fs.defaultFS","hdfs://192.168.2.231:9000");*/
//在hdfs系统上配置
Job job = Job.getInstance(conf);
//设置map类
job.setMapperClass(MyJoinMapper.class);
//设置map输出的形式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置为没有Reduce
job.setNumReduceTasks(0);
//设置读取数据的位置
FileInputFormat.setInputPaths(job,new Path("E:\\mapReduce\\3\\input"));
//设置输出数据位置
FileOutputFormat.setOutputPath(job,new Path("E:\\mapReduce\\3\\output"));
//提交
boolean result = job.waitForCompletion(true);
//成功返回0失败返回1
System.exit(result?0:1);
}
}
topN
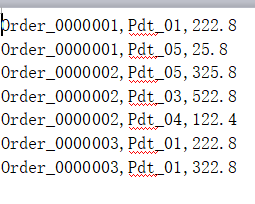
求同组TopN
自定义对象
public class OrderBean implements WritableComparable {
private Text itemId;
private DoubleWritable amount;
public OrderBean() {
}
public OrderBean(Text itemId, DoubleWritable amount) {
this.itemId = itemId;
this.amount = amount;
}
public void set(Text itemId, DoubleWritable amount) {
this.itemId = itemId;
this.amount = amount;
}
public Text getItemId() {
return itemId;
}
public DoubleWritable getAmount() {
return amount;
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(itemId.toString());
dataOutput.writeDouble(amount.get());
}
public void readFields(DataInput dataInput) throws IOException {
this.itemId = new Text(dataInput.readUTF());
this.amount = new DoubleWritable(dataInput.readDouble());
}
public int compareTo(OrderBean o) {
//对比id
int cmp = this.itemId.compareTo(o.getItemId());
//如果id一样比较价格
if (cmp == 0) {
//将金额大的放在前面
cmp = -this.amount.compareTo(o.getAmount());
}
return cmp;
}
@Override
public String toString() {
return this.itemId.toString()+"\t"+this.amount.get();
}
}
//自定义组件
public class ItemIdGroupingComparator extends WritableComparator {
public ItemIdGroupingComparator() {
super(OrderBean.class,true);
}
//如果a,bid相同则分成一组
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean aBean = (OrderBean) a;
OrderBean bBean = (OrderBean) b;
return aBean.getItemId().compareTo(bBean.getItemId());
}
}
public class ItemIdPartitioner extends Partitioner {
//如果orderBeanid相同则分在同区
public int getPartition(OrderBean orderBean, NullWritable nullWritable, int i) {
return (orderBean.getItemId().hashCode() & Integer.MAX_VALUE) % i;
}
}
//topN
public class TopN {
private static class TopNMapper extends Mapper{
OrderBean orderBean = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
final String[] fields = line.split(",");
Text id = new Text(fields[0]);
DoubleWritable amount = new DoubleWritable(Double.parseDouble(fields[2]));
orderBean.set(id,amount);
context.write(orderBean,orderBean);
}
}
private static class TopNReduce extends Reducer{
int topN = 1;
int cout = 0;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
topN = Integer.parseInt(conf.get("topN"));
}
@Override
protected void reduce(OrderBean key, Iterable values, Context context) throws IOException, InterruptedException {
for (OrderBean val:values
) {
if ((cout++) == topN){
cout=0;
return;
}
context.write(NullWritable.get(),val);
}
cout=0;
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("topN","2");
/*conf.set("fs.defaultFS","hdfs://192.168.2.231:9000");*/
//在hdfs系统上配置
Job job = Job.getInstance(conf);
//设置jar包位置(linux下执行路径非hdfs)
job.setJarByClass(TopN.class);
//设置map类
job.setMapperClass(TopN.TopNMapper.class);
//设置reduce类
job.setReducerClass(TopN.TopNReduce.class);
//设置map输出的形式
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(OrderBean.class);
//设置最终输入形式
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(OrderBean.class);
//设置数据读取组件
job.setInputFormatClass(TextInputFormat.class);
//设置数据输出组件
job.setOutputFormatClass(TextOutputFormat.class);
//设置读取数据的位置
FileInputFormat.setInputPaths(job,new Path("E:\\mapReduce\\2\\input"));
//设置输出数据位置
FileOutputFormat.setOutputPath(job,new Path("E:\\mapReduce\\2\\output2"));
//使用自定义组件
job.setGroupingComparatorClass(ItemIdGroupingComparator.class);
job.setPartitionerClass(ItemIdPartitioner.class);
//提交
boolean result = job.waitForCompletion(true);
//成功返回0失败返回1
System.exit(result?0:1);
}
}