【算法比赛baseline】Kaggle泰坦尼克之灾
前言
这个系列是我新开的一个专辑,目的嘛,也很明确:最近在实习,然后无所事事,所以打算剩余的时间敲敲代码练手,正好多积累一些特征工程的经验,多撸几个baseline,到时候开学后就有经验可以打比赛了,据我所知现在比较有名的比赛除了Kaggle、天池、科赛还有就是各大互联网公司举办的算法比赛,很多,几乎每个月份都有,只要你想参加,就有机会,有的人选择了直接上手比赛高压之下快速成长,我觉得我离比赛还有一定距离,所以比较倾向于多学习学习,把基础打牢固秋天再说比赛的事情。
大神推荐
这个baseline也是参照他的这篇博文:
寒小阳
准备好好看看他写的专栏了,明光村出来的技术有保障,黑一波北邮。
我的实现
github代码请戳这里。
- 数据探索,这是必不可少的一步,这个比赛数据还算整齐的,有的比赛缺失值异常值多的让人疯狂
- 数据清洗和特征工程,这部分没怎么做,就简单处理了一下数据,没有挖掘更多的交叉特征,如果是真正的比赛的话,还需要在这块多下功夫
- 训练模型,前期做好了,这块也就不用发愁了
- 模型融合,这是必须要做的。
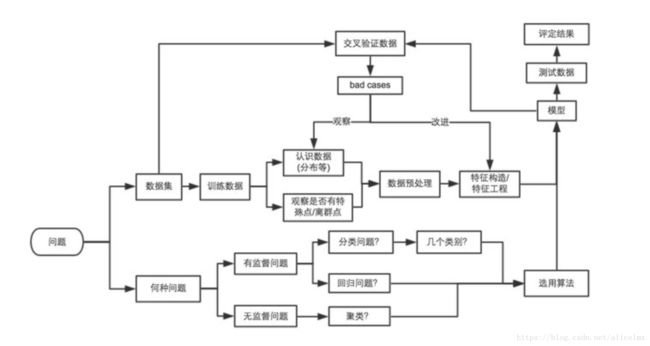
打比赛的思路框架
- 拿到数据后怎么了解数据(可视化)
- 选择最贴切的机器学习算法
- 定位模型状态(过/欠拟合)以及解决方法
- 大量极的数据的特征分析与可视化
- 各种损失函数(loss function)的优缺点及如何选择
人生经验
- 应用机器学习,千万不要一上来就试图做到完美,先撸一个baseline的model出来,再进行后续的分析步骤,一步步提高,所谓后续步骤可能包括『分析model现在的状态(欠/过拟合),分析我们使用的feature的作用大小,进行feature selection,以及我们模型下的bad case和产生的原因』等等。
- 重视对数据的认识!
- 数据中的特殊点、离群点分析和处理真的太重要了!
- 特征工程太重要了,有些时候甚至比模型本身还要重要!
- 要做模型融合啊!
上面这些都是口头上的,具体怎么做,真的得在比赛中去探索,我也是新手,在碰到形形色色的问题的时候就会很烦躁,多做多练!
工具上的不足
现在我喜欢把之前学过的matplotlib包称为工具而非知识,这个东西以前学过,可是感觉在画图的时候还是感觉很吃力,还是的**多查官方文档!多查官方文档!多查官方文档!**查着查着就熟练了,所以摆脱原来一本书从头看到尾的想法吧,边动手边学习,把知识当成工具才是最高效的学习方法。
还有就是变量名啊,真的要仔细点,调错半天发现变量名写错了,多么心痛,IDE是个好东西,想念~