动手学PaddlePaddle(5):迁移学习
本次练习,用迁移学习思想,结合paddle框架,来实现图像的分类。
相关理论:
1. 原有模型作为一个特征提取器:
使用一个用ImageNet数据集提前训练(pre-trained)好的CNN,再除去最后一层全连接层(fully-connected layer),即除去原有的分类器部分。然后再用剩下的神经网络作为特征提取器应用在新的数据集上。我们只需要用新的训练集训练一个嫁接到这个特征提取器上的分类器即可。
2.fine-turning原有模型
这种方法要求不仅仅除去原有模型的分类器,再用新的数据集训练新的分类器,还要求微调(fine-tune)本身神经网络的参数(weights)。和方式1的区别是:方式1要求固定原有神经网络的参数,而fine-tune允许训练新的数据集时对原有神经网络的参数进行更改。为了防止过拟合,有时可以要求固定某些层的参数,只微调剩下的一些层。
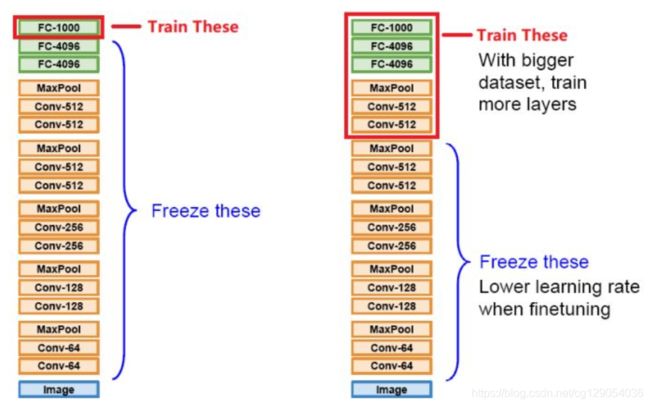
本次实验总共分两个steps;
- step-1: 在step-1中,加载在imagenet数据集上训练好的Resnet50模型,作为预训练模型,并且冻结除fc层之外的参数,只训练fc层。得到step_1_model;
拿到新数据集,想要用预训练模型处理的时候,通常都会先用step-1的方法看看预训练模型在新数据上的表现怎么样,摸个底。如果表现不错,还想看看能不能进一步提升,就可以试试Fine-tune(即解锁比较少的卷积层继续训练),但是不要期待会有什么质的飞跃。如果由于新数据集与原数据集(例如ImageNet数据集)的差别太大导致表现很糟,那么一方面可以考虑从头训练模型,另一方面也可以考虑解锁比较多层的训练,亦或干脆只用预训练模型的参数作为初始值,对模型进行完整训练。
- step-2: 在step-2中,把step_1_model作为预训练模型,并在此基础上重新训练,得到最终的模型step_2_model。
但是要注意:
事实上,step-2必须在已经进行过‘冻结特征提取器参数的训练之后再尝试训练模型,这时分类器的参数已经经过一次训练。如果从随机生成的分类器参数开始直接训练,在做参数更新迭代过程中梯度将很可能过大,而导致模型的崩溃,使模型忘记学到的所有东西。在finetune时,batch_size设置最好不要太大,以便于加速模型收敛。学习率也适当小一些。
目录
step-1:
1. 导入库
2. 定义ResNet网络
3.训练前准备
4.开始训练
step-2:
5. 导入库
6.定义ResNet网络
7.训练前准备
step-1:
在step-1中,加载在imagenet数据集上训练好的Resnet50模型,作为预训练模型,并且冻结除fc层之外的参数,只训练fc层。得到step_1_model。
1. 导入库
实验第一步,导入需要的库,本实验中专门定义了一个 reader.py文件,用来对数据集进行读取和预处理,所以也需要把reader.py文件import进来。
import os
import shutil
import paddle as paddle
import paddle.fluid as fluid
from paddle.fluid.param_attr import ParamAttr
import reader
# 获取flowers数据
train_reader = paddle.batch(reader.train(), batch_size=16)
test_reader = paddle.batch(reader.val(), batch_size=16)2. 定义ResNet网络
- 本次实验使用ResNet50这个残差神经网络,所以,接下来需要定义一个残差神经网络。
- PaddlePaddle官方已经提供了ResNet以及其他经典的网络模型。链接:https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/resnet.py
- 网络定义时,每一个层都由指定参数名字。
# 定义残差神经网络(ResNet)
def resnet50(input):
def conv_bn_layer(input, num_filters, filter_size, stride=1, groups=1, act=None, name=None):
conv = fluid.layers.conv2d(input=input,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
act=None,
param_attr=ParamAttr(name=name + "_weights"),
bias_attr=False,
name=name + '.conv2d.output.1')
if name == "conv1":
bn_name = "bn_" + name
else:
bn_name = "bn" + name[3:]
return fluid.layers.batch_norm(input=conv,
act=act,
name=bn_name + '.output.1',
param_attr=ParamAttr(name=bn_name + '_scale'),
bias_attr=ParamAttr(bn_name + '_offset'),
moving_mean_name=bn_name + '_mean',
moving_variance_name=bn_name + '_variance', )
def shortcut(input, ch_out, stride, name):
ch_in = input.shape[1]
if ch_in != ch_out or stride != 1:
return conv_bn_layer(input, ch_out, 1, stride, name=name)
else:
return input
def bottleneck_block(input, num_filters, stride, name):
conv0 = conv_bn_layer(input=input,
num_filters=num_filters,
filter_size=1,
act='relu',
name=name + "_branch2a")
conv1 = conv_bn_layer(input=conv0,
num_filters=num_filters,
filter_size=3,
stride=stride,
act='relu',
name=name + "_branch2b")
conv2 = conv_bn_layer(input=conv1,
num_filters=num_filters * 4,
filter_size=1,
act=None,
name=name + "_branch2c")
short = shortcut(input, num_filters * 4, stride, name=name + "_branch1")
return fluid.layers.elementwise_add(x=short, y=conv2, act='relu', name=name + ".add.output.5")
depth = [3, 4, 6, 3]
num_filters = [64, 128, 256, 512]
conv = conv_bn_layer(input=input, num_filters=64, filter_size=7, stride=2, act='relu', name="conv1")
conv = fluid.layers.pool2d(input=conv, pool_size=3, pool_stride=2, pool_padding=1, pool_type='max')
for block in range(len(depth)):
for i in range(depth[block]):
conv_name = "res" + str(block + 2) + chr(97 + i)
conv = bottleneck_block(input=conv,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
name=conv_name)
pool = fluid.layers.pool2d(input=conv, pool_size=7, pool_type='avg', global_pooling=True)
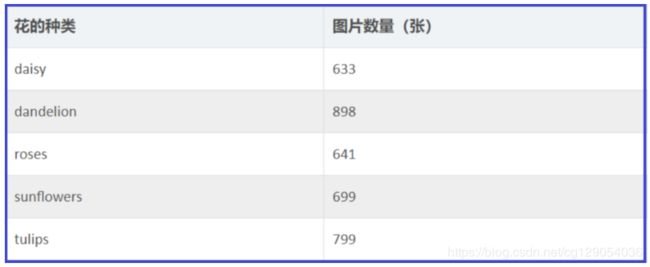
return pool本次实验,使用的图片数据集是flowers。图片是3通道宽高都是224的彩色图,总类别是5种,每一个种类大约有六百多张。

3.训练前准备
接下来,开始做训练前的准备工作。首先,定义图片数据和标签数据的输入层:
# 定义输入层
image = fluid.layers.data(name='image', shape=[3, 224, 224], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')利用stop_gradient,使得pool以上的层停止梯度传递,相当于keras中的freeze。这样就可以只训练最后的fc层,但是要注意:数据集是5分类,所以size要设为5.
# 获取分类器的上一层
pool = resnet50(image)
# 停止梯度下降
pool.stop_gradient = True
# 由这里创建一个基本的主程序
base_model_program = fluid.default_main_program().clone()
# 这里再重新加载网络的分类器,大小为本项目的分类大小
model = fluid.layers.fc(input=pool, size=5, act='softmax')接下来,要做的工作有:
- 定义损失函数;
- 求准确率;
- 定义优化器;
- 设定训练场所;
- 定义执行器,并且完成参数初始化;
# 获取损失函数和准确率函数
cost = fluid.layers.cross_entropy(input=model, label=label)
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=model, label=label)
# 定义优化方法
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=1e-3)
opts = optimizer.minimize(avg_cost)
# 定义训练场所
place = fluid.CUDAPlace(0)#用GPU训练
#place = fluid.CPUPlace() #用CPU训练
exe = fluid.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())
- 接下来加载预训练模型,使用paddle官网上训练好的ResNet50模型,这个模型存储在“./ResNet50_pretrained/”,也可以去官网上下载,链接:http://paddle-imagenet-models-name.bj.bcebos.com/ResNet50_pretrained.tar
- 通过if_exist函数判断网络所需的模型文件是否存在,然后再通过调用fluid.io.load_vars加载存在的模型文件。
# 官方提供的原预训练模型
src_pretrain_model_path = './ResNet50_pretrained/'
# 通过这个函数判断模型文件是否存在
def if_exist(var):
path = os.path.join(src_pretrain_model_path, var.name)
exist = os.path.exists(path)
return exist
# 加载模型文件,只加载存在模型的模型文件
fluid.io.load_vars(executor=exe, dirname=src_pretrain_model_path, predicate=if_exist, main_program=base_model_program)4.开始训练
接下来就定义一个双层循环来开始训练模型,并且还可以把训练过程中的cost值和acc值打印出来,以此来直观的感受训练效果。
# 优化内存
# optimized = fluid.transpiler.memory_optimize(input_program=fluid.default_main_program(), print_log=False)
# 定义输入数据维度
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
# 训练10次
for pass_id in range(10):
# 进行训练
for batch_id, data in enumerate(train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
# 每100个batch打印一次信息
if batch_id % 100 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))训练结束之后,使用fluid.io.save_param保存训练好的参数。
到这里为止,把从imagenet数据集上训练好的的原预训练模型,结合数据集,把最后一层fc进行了训练。接下来就是使用这个已经处理过的模型正式训练了。
# 保存参数模型
save_pretrain_model_path = 'models/step-1_model/'
# 删除旧的模型文件
shutil.rmtree(save_pretrain_model_path, ignore_errors=True)
# 创建保持模型文件目录
os.makedirs(save_pretrain_model_path)
# 保存参数模型
fluid.io.save_params(executor=exe, dirname=save_pretrain_model_path)step-2:
5. 导入库
import os
import shutil
import paddle as paddle
import paddle.dataset.flowers as flowers
import paddle.fluid as fluid
from paddle.fluid.param_attr import ParamAttr
import reader
# 获取flowers数据
train_reader = paddle.batch(reader.train(), batch_size=16)
test_reader = paddle.batch(reader.val(), batch_size=16)6.定义ResNet网络
仍然需要定义一个残差神经网络,这个残差神经网络跟第一步时的基本一样的,只是把分类器(也就是fc层)也加进去了,这是一个完整的神经网络。
# 定义残差神经网络(ResNet)
def resnet50(input, class_dim):
def conv_bn_layer(input, num_filters, filter_size, stride=1, groups=1, act=None, name=None):
conv = fluid.layers.conv2d(input=input,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
act=None,
param_attr=ParamAttr(name=name + "_weights"),
bias_attr=False,
name=name + '.conv2d.output.1')
if name == "conv1":
bn_name = "bn_" + name
else:
bn_name = "bn" + name[3:]
return fluid.layers.batch_norm(input=conv,
act=act,
name=bn_name + '.output.1',
param_attr=ParamAttr(name=bn_name + '_scale'),
bias_attr=ParamAttr(bn_name + '_offset'),
moving_mean_name=bn_name + '_mean',
moving_variance_name=bn_name + '_variance', )
def shortcut(input, ch_out, stride, name):
ch_in = input.shape[1]
if ch_in != ch_out or stride != 1:
return conv_bn_layer(input, ch_out, 1, stride, name=name)
else:
return input
def bottleneck_block(input, num_filters, stride, name):
conv0 = conv_bn_layer(input=input,
num_filters=num_filters,
filter_size=1,
act='relu',
name=name + "_branch2a")
conv1 = conv_bn_layer(input=conv0,
num_filters=num_filters,
filter_size=3,
stride=stride,
act='relu',
name=name + "_branch2b")
conv2 = conv_bn_layer(input=conv1,
num_filters=num_filters * 4,
filter_size=1,
act=None,
name=name + "_branch2c")
short = shortcut(input, num_filters * 4, stride, name=name + "_branch1")
return fluid.layers.elementwise_add(x=short, y=conv2, act='relu', name=name + ".add.output.5")
depth = [3, 4, 6, 3]
num_filters = [64, 128, 256, 512]
conv = conv_bn_layer(input=input, num_filters=64, filter_size=7, stride=2, act='relu', name="conv1")
conv = fluid.layers.pool2d(input=conv, pool_size=3, pool_stride=2, pool_padding=1, pool_type='max')
for block in range(len(depth)):
for i in range(depth[block]):
conv_name = "res" + str(block + 2) + chr(97 + i)
conv = bottleneck_block(input=conv,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
name=conv_name)
pool = fluid.layers.pool2d(input=conv, pool_size=7, pool_type='avg', global_pooling=True)
output = fluid.layers.fc(input=pool, size=class_dim, act='softmax')
return output7.训练前准备
接下来,开始做训练前的准备工作:
- 定义图片数据和标签数据的输入层;
- 定义损失函数;
- 求准确率;
- 定义优化器;
- 设定训练场所;
- 定义执行器,并且完成参数初始化;
# 定义输入层
image = fluid.layers.data(name='image', shape=[3, 224, 224], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
# 获取分类器
model = resnet50(image, 5)
# 获取损失函数和准确率函数
cost = fluid.layers.cross_entropy(input=model, label=label)
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=model, label=label)
# 获取训练和测试程序
test_program = fluid.default_main_program().clone(for_test=True)
# 定义优化方法
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=1e-3)
opts = optimizer.minimize(avg_cost)
# 定义一个使用GPU的执行器
place = fluid.CUDAPlace(0)
#place = fluid.CPUPlace()
exe = fluid.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())加载经过step-1训练好的模型,作为新的预训练模型。并在此基础上进行重新训练:
# 经过step-1处理后的的预训练模型
pretrained_model_path = 'models/step-1_model/'
# 加载经过处理的模型
fluid.io.load_params(executor=exe, dirname=pretrained_model_path)接下来就定义一个双层循环来开始训练模型,并且还可以把训练过程中的cost值和acc值打印出来,以此来直观的感受训练效果。
# 定义输入数据维度
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
# 训练10次
for pass_id in range(10):
# 进行训练
for batch_id, data in enumerate(train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
# 每100个batch打印一次信息
if batch_id % 100 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
# 进行测试
test_accs = []
test_costs = []
for batch_id, data in enumerate(test_reader()):
test_cost, test_acc = exe.run(program=test_program,
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
test_accs.append(test_acc[0])
test_costs.append(test_cost[0])
# 求测试结果的平均值
test_cost = (sum(test_costs) / len(test_costs))
test_acc = (sum(test_accs) / len(test_accs))
print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (pass_id, test_cost, test_acc))训练结束之后,可以保存预测模型用于之后的预测使用。
# 保存预测模型
save_path = 'models/step_2_model/'
# 删除旧的模型文件
shutil.rmtree(save_path, ignore_errors=True)
# 创建保持模型文件目录
os.makedirs(save_path)
# 保存预测模型
fluid.io.save_inference_model(save_path, feeded_var_names=[image.name], target_vars=[model], executor=exe)