视频推荐ALS算法使用总结说明
ALS算法使用总结说明
一、算法流程
最近终于把ALS算法上线了,前前后后整了一个半月,现在把这个经历记录下。我的目的是利用ALS算法做视频推荐,当然这只是作为其中一个算法。为了达到这个目的,我经过分析之后,使用下面的流程。
1、接收视频的请求
2、获取用户的历史记录(包括用户观看历史、点赞的视频、分享的视频、评论的视频)
3、根据历史记录中的视频获取相似视频
4、权重排序
5、返回结果
(推荐架构参见)
其中ALS算法的作用就是在第三步,我们利用ALS算法计算出所有视频的相似视频供推荐使用。
为了用ALS算法计算相似视频,我参考资料后,使用下面的流程。
1、获取所有用户每天的视频历史记录(包括用户观看、点赞、分享、评论的日志)
2、整理日志,规范化如下形式(用户id,视频id,动作,时长,动作发生时的时间戳)
3、形成用户对视频的打分表,不同的行为分配不同的权重。
4、调用spark的ML库中ALS函数进行训练,调试参数。
5、获取每个视频的特征向量。
6、根据视频的特征向量计算视频两两间的相似性。
都说整理数据是脏活累活,此言非虚啊。上面的第1、2、3步花费了我一个月的空闲时间(当然其中有间歇),有几次因为太麻烦都想放弃了。所幸最终搞定,经验就是
1、我们要确定我们需要的历史日志,如今在哪里(公司的是存放在hdfs或者hive表中)。
2、我们要写SQL把它提取出来。提取的时候不要贪心,求大求全,需要什么数据就写什么样的SQL。目前不需要的数据先放一放。(放一放,一般都凉凉了)。
(ALS算法原理参见)
二、ALS算法调试参数过程
1、参数说明
我使用spark自带的隐性行为als算法函数,里面涉及三个重要的参数,分别是
rank:代表视频的特征向量的维度,默认值10
iterations: 代表训练的轮次,默认值5
lambda:代表正则化系数,默认值0.01
其中rank的值越大,代表视频被描述的越详细,计算出来的视频相似列表两两之间的差异也越大。我刚开始把rank的值设置的很小(默认值10),结果计算出的相似视频列表中,两个视频之间区分不开,差值在0.00001这个级别,使用时效果较差。
iterations的值越大,我们训练的次数就越多,训练就越耗时。
lambad是为了降低过拟合现象而设置的,当你运行算法时发现在训练集上准确率很高,在测试集上准确率较低的话,有可能发生了过拟合。需要把这个值设置大一点。
MSE:目标函数,这是预测值和实际值的平方差的和的均值。
2、调试过程
我的方法比较简单粗暴,首先确定三个参数的范围,然后再微调。
Rank 可选值[10,30,50,80,100]
iterations 可选值[10,20,30,50]
lambda 可选值[0.001,0.01,0.1,1,10]
我将这些可选值进行组合,可以得到100个(rank, iterations, lambda)的组合。然后将程序运行100次,分别得到MSE,观察规律。结果如下
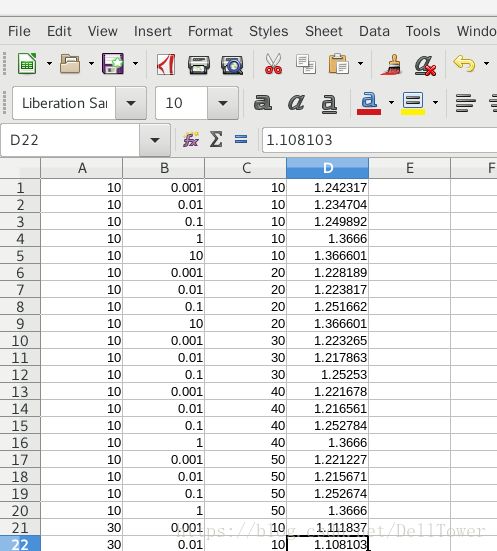
(从左到右分别是,rank,lambda,iterations,MSE)
我的实验次数很少,但是也发现一些现象
1、以rank=50为分界点,rank越大,需要设置lambda的值越大,才能保持MSE不增加。
2、iteration对结果的影响不是很大,可能是我的数据集的关系,我得到的iterations优值是在[20,30]这个范围内。
在调试参数的时候,也遇到一些问题。
1、程序运行的时候日志显示和集群联系中断的情况发生。这是由于训练时间过长,spark的rdd断片了。Google后,使用检查点机制得以解决。
2、每次运行都需要耗费很多时间,迫使我精简程序。把评分数据存储在hdfs上,这样不用每次重新计算评分矩阵,节省了一些时间。