tensorflow2.0_数据预处理+VGG16迁移学习(不使用API给模型输入数据)
数据预处理+VGG16迁移学习
- 1、加载数据库
- 2、参数设置
- 3、读取文件中的图片
- 4、对数据进行预处理
- 4.1、查看数据及标签的数量
- 5、对数据集进行划分
- 5.1、查看切分后的数据集
- 6、训练分类模型
- 7、训练并保存模型
- 8、模型训练效果
- 8.1、曲线平滑处理
- 8.2、测试集测试效果
- 9、将模型保存为pb文件
- 10、tensorboard可视化
- 11、模型评估
- 11.1、分类报告&混淆矩阵
- 11.2、绘制ROC和AUC曲线
开发环境jupyter、tensorflow2.0
1、加载数据库
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import sklearn
import sys
import tensorflow as tf
#import time
import cv2
#import glob
# from PIL import Image
# import matplotlib.patches as patch
# import json
from tensorflow import keras
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.applications import VGG16, VGG19
from tensorflow.keras.models import load_model
from tensorflow.keras import layers, models
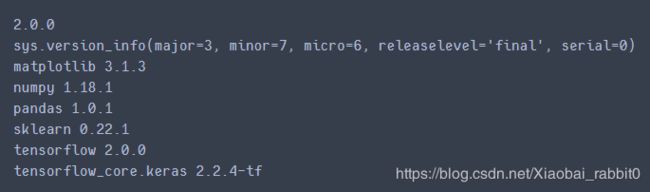
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__,module.__version__)
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.applications import VGG16, VGG19
from tensorflow.keras.models import load_model
from tensorflow.keras import layers, models
from tensorflow.compat.v1 import graph_util
from tensorflow.python.keras import backend as K
tf.compat.v1.disable_eager_execution()
K.set_learning_phase(0)
2、参数设置
preprocessedFolder = 'H:\\jupyter_project1\\模式识别作业\\ClassificationData\\'
outModelFileName = 'H:\\jupyter_project1\\模式识别作业\\'
ImageWidth = 512
ImageHeight = 320
ImageNumChannels = 3
TrainingPercent = 70
ValidationPercent = 15
3、读取文件中的图片
def read_dl_classifier_data_set(preprocessedFolder):
img_list = []
label_list = []
cnt_class = 0 #存放每个图像的label
cnt_img = 0
for directory in os.listdir(preprocessedFolder):
cnt_class += 1
tmp_dir = preprocessedFolder + directory
for image in os.listdir(tmp_dir):
cnt_img += 1
tmp_img_filepath = tmp_dir + '\\'+image
tmp_img = cv2.imread(tmp_img_filepath)
tmp_img = cv2.resize(tmp_img,(ImageWidth, ImageHeight))
img_list.append(tmp_img)
label_list.append(cnt_class)
if cnt_img % 50 ==0:
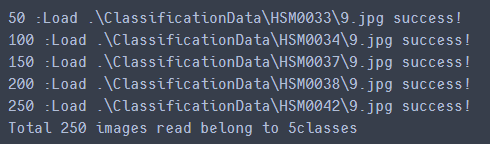
print(str(cnt_img) + " :Load " + tmp_img_filepath + " success!")
print("Total " + str(cnt_img) + " images read belong to " + str(cnt_class) + "classes" )
return np.array(img_list),np.array(label_list)
if __name__ == "__main__":
#使用相对路径,改为绝对路径后,也可直接运行
preprocessedFolder = '.\\ClassificationData\\'
outModelFileName = '.\\ClassificationData\\'
ImageWidth = 512
ImageHeight = 320
ImageNumChannels = 3
TrainingPercent = 70
ValidationPercent = 15
all_data,all_label = read_dl_classifier_data_set(preprocessedFolder)
4、对数据进行预处理
1、将图像数据像素值压缩至0.0-1.0之间
2、对label使用one-hot编码
def preprocess_dl_Image(all_data, all_label):
all_data = all_data.astype('float32') / 255.
all_label = to_categorical(all_label)
return all_data, all_label
all_data, all_label = preprocess_dl_Image(all_data, all_label)
4.1、查看数据及标签的数量
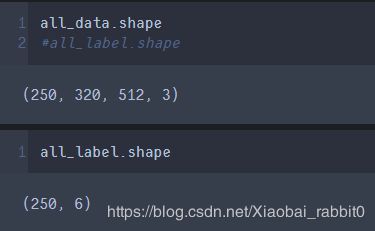
5、对数据集进行划分
1、原始数据为有序数据,将数据随机打乱
2、训练集:175,验证集:37,测试集=38
def split_dl_classifier_data_set(all_data, all_label, TrainingPercent, ValidationPercent):
#打乱索引
index = [i for i in range(all_data.shape[0])]
np.random.shuffle(index) #打乱索引
all_data = all_data[index]
all_label = all_label[index]
all_len = all_data.shape[0]
train_len = int(all_len * TrainingPercent / 100.)
validation_len = train_len + int(all_len * ValidationPercent / 100.)
#切分数据集
train_data,train_label = all_data[0:train_len, :, :, :], all_label[0:train_len, :]
val_data, val_label = all_data[train_len:validation_len, :, :, :], all_label[train_len:validation_len, :]
test_data, test_label = all_data[validation_len:, :, :, :],all_label[validation_len:, :]
return train_data, train_label, val_data, val_label, test_data, test_label
train_data, train_label, val_data, val_label, test_data, test_label = split_dl_classifier_data_set(
all_data, all_label, TrainingPercent, ValidationPercent)
5.1、查看切分后的数据集

6、训练分类模型
1、使用tensorflow2.0自带的VGG19迁移学习
2、epochs = 60
3、batch_size = 32
4、使用验证集验证模型
5、使用tensorflow回调函数callbacks实现:保存模型(h5格式)、提前终止模型、tensorboard显示
def train_classifier(train_data, train_label, val_data, val_label, outModelFileName):
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(ImageHeight, ImageWidth, 3))
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(6, activation='softmax'))
conv_base.trainable = False
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
return model
model = train_classifier(train_data, train_label, val_data, val_label, outModelFileName)
model.summary()

7、训练并保存模型
# Tensorboard, earlystopping, ModelCheckpoint
logdir = os.path.join('graph_def_and_weights')
if not os.path.exists(logdir):
os.mkdir(logdir)
#保存模型
output_model_file = os.path.join(logdir,
"fashion_mnist_model.h5")
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(output_model_file,
save_best_only = True,
save_weights_only = False),
keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3),
]
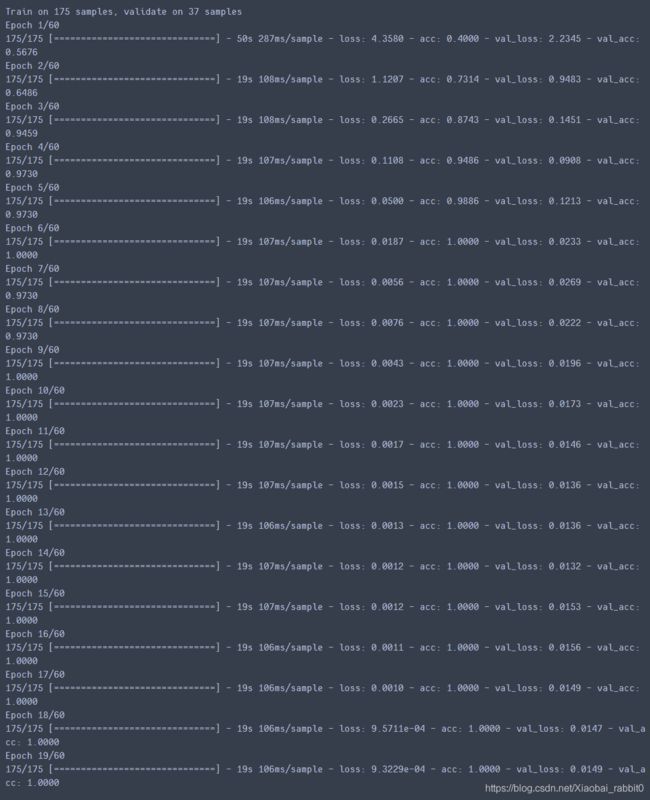
history = model.fit(train_data, train_label, epochs=60,
validation_data=(val_data, val_label),
callbacks = callbacks)
8、模型训练效果
1、画loss与acc变化曲线
2、在测试集上测试模型训练效果
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(-0.1,1.2)
plt.show()
plot_learning_curves(history)

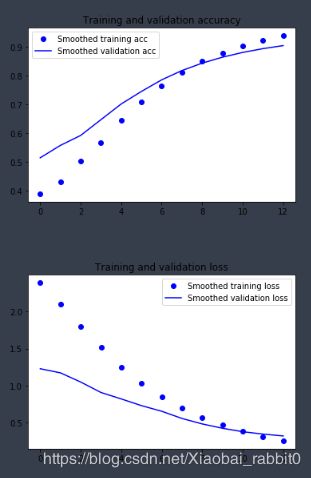
8.1、曲线平滑处理
def smooth_curve(points, factor=0.8):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
def plot_history(history):
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs,
smooth_curve(acc), 'bo', label='Smoothed training acc')
plt.plot(epochs,
smooth_curve(val_acc), 'b', label='Smoothed validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs,
smooth_curve(loss), 'bo', label='Smoothed training loss')
plt.plot(epochs,
smooth_curve(val_loss), 'b', label='Smoothed validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
plot_history(history)
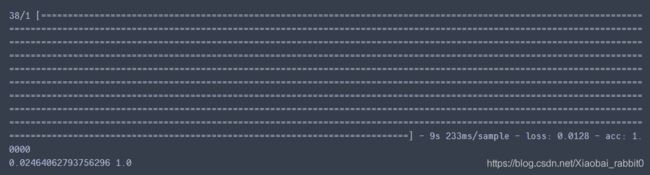
8.2、测试集测试效果
test_loss, test_acc = model.evaluate(test_data, test_label)
print(test_loss,test_acc)
9、将模型保存为pb文件
1、tf.keras默认使用h5格式保存模型,使用load_model加载后,可正常使用
2、未测试pb格式保存的模型的正确性
def freeze_session(session, keep_var_names=None, output_names=None, clear_devices=True):
from tensorflow.python.framework.graph_util import convert_variables_to_constants
graph = session.graph
with graph.as_default():
freeze_var_names = list(set(v.op.name for v in tf.compat.v1.global_variables(
)).difference(keep_var_names or []))
output_names = output_names or []
output_names += [v.op.name for v in tf.compat.v1.global_variables()]
# Graph -> GraphDef ProtoBuf
input_graph_def = graph.as_graph_def()
if clear_devices:
for node in input_graph_def.node:
node.device = ""
frozen_graph = convert_variables_to_constants(session, input_graph_def,
output_names, freeze_var_names)
return frozen_graph
def WriteDlClassifier(model, outModelFileName):
# save keras model as *.pb(convert *.h5 to *.pb)
from tensorflow.compat.v1 import graph_util
from tensorflow.python.keras import backend as K
tf.compat.v1.disable_eager_execution()
K.set_learning_phase(0)
frozen_graph = freeze_session(tf.compat.v1.keras.backend.get_session(),
output_names=[out.op.name for out in model.outputs],
clear_devices=True)
tf.io.write_graph(frozen_graph, outModelFileName,
'BLclassifier.pb', as_text=False)
print("save pb successfully! ")
WriteDlClassifier(model, outModelFileName)

10、tensorboard可视化
模型生成文件中有一个 tensorboard 可视化文件,这里简单看一下效果
1、打开 Anaconda Powershell Prompt
2、在命令行中输入: tensorboard --logdir=graph_def_and_weights,会得到一个网址。(其中
graph_def_and_weights 是文件名)

3、用浏览器打开网址,就打开 tensorboard 了
11、模型评估
1.使用测试集进行评估
2.输出分类报告和混淆矩阵
3.绘制ROC和AUC曲线
11.1、分类报告&混淆矩阵
'''输出验证集分类报告和混淆矩阵'''
# Y_pred_tta=model.predict_classes(test_data)
# Y_test = [np.argmax(one_hot)for one_hot in test_label]# 由one-hot转换为普通np数组
from sklearn.metrics import classification_report #分类报告
from sklearn.metrics import confusion_matrix #混淆矩阵
from sklearn.metrics import accuracy_score #模型精度
import seaborn as sns
Y_pred_tta=model.predict_classes(test_data) #模型对测试集进行预测
Y_test = [np.argmax(one_hot)for one_hot in test_label]# 由one-hot转换为普通np数组
print('验证集分类报告:\n',classification_report(Y_test,Y_pred_tta))
confusion_mc = confusion_matrix(Y_test,Y_pred_tta)#混淆矩阵
df_cm = pd.DataFrame(confusion_mc)
plt.figure(figsize = (10,7))
sns.heatmap(df_cm, annot=True, cmap="BuPu",linewidths=1.0,fmt="d")
plt.title('PipeLine accuracy:{0:.3f}'.format(accuracy_score(Y_test,Y_pred_tta)),fontsize=20)
plt.ylabel('True label',fontsize=20)
plt.xlabel('Predicted label',fontsize=20)

11.2、绘制ROC和AUC曲线
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.metrics import roc_curve
from sklearn import metrics
import matplotlib as mpl
# 计算属于各个类别的概率,返回值的shape = [n_samples, n_classes]
y_score = model.predict_proba(test_data)
# 1、调用函数计算验证集的AUC
print ('调用函数auc:', metrics.roc_auc_score(test_label, y_score, average='micro'))
# 2、手动计算验证集的AUC
#首先将矩阵test_label和y_score展开,然后计算假正例率FPR和真正例率TPR
fpr, tpr, thresholds = metrics.roc_curve(test_label.ravel(),y_score.ravel())
auc = metrics.auc(fpr, tpr)
print('手动计算auc:', auc)
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
#FPR就是横坐标,TPR就是纵坐标
plt.figure(figsize = (10,7))
plt.plot(fpr, tpr, c = 'r', lw = 2, alpha = 0.7, label = u'AUC=%.3f' % auc)
plt.plot((0, 1), (0, 1), c = '#808080', lw = 1, ls = '--', alpha = 0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=16)
plt.ylabel('True Positive Rate', fontsize=16)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
plt.title('37个验证集分类后的ROC和AUC', fontsize=18)
plt.show()
