03.1跟雨痕看go源码- go routine(未完待续)
1.概述
golang本质就是GPM三个实体实现的调度。
G对应每个任务,P对应每个processor概念(就是会包含一堆的G,比如先执行G1,在执行G2)M对应系统线程,M(还包含系统栈之类的概念)绑定一个P之后就开始逐个运行P里面的G。
最基本的流程图就是雨痕给的
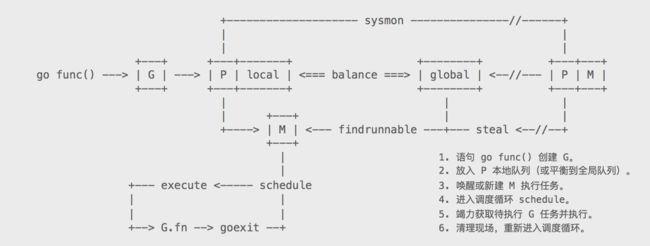
后面雨痕对于GPM三者的解释也很到位。我这里不抄袭了。
2.初始化
首先介绍的就是schedinit()里面主要是procresize函数。
这个procresize()就是调整系统里面P的数量。一般就是系统的cpu内核的数量,初始化时也实行多退少补的原则,只是退的时候要注意是否退出的P包含了当前P,如果是就需要一大堆的细节上的处理。
这里还有个所有P的管理结构
var allp [_MaxGomaxprocs + 1]*p
type schedt struct {
pidle puintptr // P
npidle uint32 // P
}还有个提示,如果调用手动调用并修改runtime.GOMAXPROCS就会引发stopTheWorld以及startTheWorld,这两个动作本身是比较好耗时的,之后在startTheWorld执行的procresize()也是比较耗时的。
3.任务 G/P
先举了个栗子,通过
go build -o test test.go
go tool objdump -s "main\.main" test
go add(x, y)会被汇编成类似
CALL runtime.newproc(SB)
这种代码然后就去runtime找了。
newproc(获取pc/ip地址以及入参等重要信息后)->newproc1
之后登场的G的数据结构
type g struct {
stack stack //执行栈
sched gobuf //用于保存执行现场
goid int64 //唯一序号
gopc uintptr //调用者 PC/IP
startpc uintptr //任务函数
}newproc1一开始就处理各种处理创建G,测试G,对齐地址,拷贝栈,保存现场的各种杂活儿。然后一个runqput(p, newg, true),被put进去了。
runqput有可能把g作为P.runnext,也可能放在末尾,也有可能丢到全局队列。
稍微介绍了g通过p然后进行二级缓存复用的逻辑,类似cache/object,central的做法。分别对应gfget, gfput两个函数。
所有的g 还有个全局应用allgs/allg,用来索引所有的G方便回收和shrinkstack。

补充了个细节只有本地的P队列堆满了才会丢到全局队列,而且一次会丢本地队列长度的一半,保证效率和多核均匀调度。
4.线程 M
当结束runqput之后,开始wakep了,
wake->startm->newm创建/或者notewakeup(&mp.park)

newm->newosproc->linux调用
clone(cloneFlags,stk,unsafe.Pointer(mp),unsafe.Pointer(mp.g0),unsafe.Pointer(funcPC(mstart))) 开启系统线程,并且入口函数是mstart
所有m会被添加到allm链表,不会被释放,超过10000崩溃。最后补充了两个细节1:m也是有复用的,mput&mget使用1级缓存。
然后说不要创建太多m啊,time.Sleep比C.sleep(1)要好,之类的。
5.执行
上面说到newm的时候会注册系统线程并把mstart作为入口函数。
然后这里就讲mstart
mstart ->
mstart1 aquirep绑定p ->
schedule()兼顾帮助垃圾回收标记之类的各种杂活,findrunable,->
调用execute->
各种准备好栈JMP入函数入口地址PC->
各种调用结束后RET指令把预先压入的goexit地址恢复到PC/IP->
将G返回服用链表->
重新schedule()然后介绍了一下findrunable的主干:
1.通过runqget拿本地的P的东西,
2.globrunqget
3.检查netpoll任务
4.尝试偷取其他P的任务。(基于CAS和atomicset弄的Work-Stealing算法)
…
5.这后还会进行各种尝试,如果实在没有就stopm了。
Lockedg
这是cgo的一个特定调用方式,会把当前的g和m绑定,而且只有在结束调用的时候才会松开。
一个m在调用schedule() 如果发现它是被某个G绑定的则会暂时休息。如果发现自己将要调用的G,是被别的m绑定的,则会将它唤醒,然后自己休眠。
所以每个cgo routine在调用完成之前都会有自己专属的一个G调用。cgo因此会产生大量的m。
6.监控
…