DL4J中文文档/模型/计算图
用计算图构建复杂网络架构
本页描述了如何使用 DL4J的计算图功能来构建更复杂的网络。
内容
- 计算图概述
- 计算图:一些用例
- 配置一个计算图网络
- 图顶点类型
- 示例1:具有跳过连接的循环网络
- 示例2:多个输入和合并顶点
- 例3:多任务学习
- 自动添加预处理器和计算nIns
- 用于计算图的训练数据
- RecordReaderMultiDataSetIterator 示例 1: 回归数据
- RecordReaderMultiDataSetIterator 示例 2: 分类和多任务学习
计算图概述
DL4J有两种类型的包括多个层的网络:
- MultiLayerNetwork(多层网络),是神经网络层栈必不可少的(具有单个输入层和单个输出层)。
- ComputationGraph (计算图), 它允许在网络架构中获得更大的自由度。
具体而言,计算图允许构建具有以下特征的网络:
- 多网络输入数组
- 多个网络输出(包括混合分类/回归加构)
- 使用有向无环图连接结构连接到其他层的层(而不是一个层栈)
一般说来,当构建具有单个输入层、单个输出层和 输入->a->b->c->输出 类型连接结构的网络时:多层网络通常是首选网络。然而,MultiLayerNetwork所能做的一切,ComputationGraph也可以做到——尽管配置可能稍微复杂一些。
从深度学习开始
计算图: 一些用例
可以使用计算图构建的一些架构的示例包括:
- 多作务学习架构
- 具有跳跃连接的循环神经网络
- GoogLeNet,一种用于图像分类的复杂卷积网络
- 图像标注创建
- 卷积网络在句子分类中的应用
- 残差学习卷积神经网络
配置一个计算图
顶点的类型
其基本思想是,在计算图中,核心构建块是图形顶点,而不是层。层(或者,更准确地说,是层顶点对象),只是图中的一种顶点。其他类型的顶点包括:
- 输入顶点
- 元素运算顶点
- 合并顶点
- 子集顶点
- 预处理器顶点
下面简要描述这些类型的图形顶点。
LayerVertex: 层顶点(具有神经网络层的图形顶点)用.addLayer(String,Layer,String...)方法被添加。第一个参数是层的标签,最后的参数是该层的输入。如果需要手动添加InputPreProcessor(通常不需要,请参阅下一节),可以使用.addLayer(String、Layer、InputPreProcessor、String...)方法。
InputVertex: 输入顶点由你配置中的addInputs(String...)方法指定。用作输入的字符串可以是任意的——它们是用户定义的标签,并且可以在以后的配置中引用。提供的字符串数量定义了输入的数量;输入的顺序还在fit方法(或DataSet/MultiDataSet对象)中定义了相应的INDArray的顺序。
ElementWiseVertex: 元素操作顶点执行例如从一个或多个其他顶点对激活进行元素式加法或减法。因此,用作ElementWiseVertex的输入的激活必须都具有相同的大小,并且元素顶点的输出大小与输入相同。
MergeVertex: 合并顶点 联接/合并输入激活。例如,如果一个合并顶点分别具有2个大小为5和10的输入,则输出大小将是5 + 10=15激活。对于卷积网络激活,示例沿着深度合并:因此假设来自一个层的激活具有4个特征,而另一个具有5个特征(都具有(4或5)x宽度x高度激活),那么输出将具有(4+5)x宽度x高度激活。
SubsetVertex: 子集顶点允许你只从另一个顶点获得激活的一部分。例如,为了从标签为“layer1”的另一个顶点获得前5个激活,可以使用.addVertex("subset1", new SubsetVertex(0,4), "layer1"):这意味着“layer1”顶点中的第0至第4(包含)个激活将被用作子集顶点的输出。
PreProcessorVertex: 有时,你可能希望InputPreProcessor的功能不与层相关联。PreProcessorVertex顶点允许你这样做。
最后,也可以为你自定义的图顶点通过实现一个configuration 和 implementation 类实现自定义图顶点。
示例1:具有跳过连接的循环网络
假设我们希望建立以下循环神经网络体系架构:

为了这个例子,假设我们的输入数据的大小是5。我们的配置如下:
ComputationGraphConfiguration conf = new NeuralNetConfiguration.Builder()
.updater(new Sgd(0.01))
.graphBuilder()
.addInputs("input") //这里可以使用任意的标签
.addLayer("L1", new GravesLSTM.Builder().nIn(5).nOut(5).build(), "input")
.addLayer("L2",new RnnOutputLayer.Builder().nIn(5+5).nOut(5).build(), "input", "L1")
.setOutputs("L2") //我们需要指定网络输出和它们的顺序。
.build();
ComputationGraph net = new ComputationGraph(conf);
net.init();
注意,在.addLayer(...)方法中,第一个字符串("L1"、"L2")是该层的名称,而结尾的字符串(["input"]、["input"、"L1"])是该层的输入。
示例2:多个输入和合并顶点
考虑下面的架构:

这里,合并顶点从层L1和L2取出激活,并合并(连接)它们:因此,如果层L1和L2都具有4个输出激活(.nOut(4)),则合并顶点的输出大小是4+4=8个激活。
为了构建上述网络,我们使用以下配置:
ComputationGraphConfiguration conf = new NeuralNetConfiguration.Builder()
.updater(new Sgd(0.01))
.graphBuilder()
.addInputs("input1", "input2")
.addLayer("L1", new DenseLayer.Builder().nIn(3).nOut(4).build(), "input1")
.addLayer("L2", new DenseLayer.Builder().nIn(3).nOut(4).build(), "input2")
.addVertex("merge", new MergeVertex(), "L1", "L2")
.addLayer("out", new OutputLayer.Builder().nIn(4+4).nOut(3).build(), "merge")
.setOutputs("out")
.build();
例3:多任务学习
在多任务学习中,使用神经网络进行多个独立的预测。例如,考虑同时用于分类和回归的简单网络。在这种情况下,我们有两个输出层,“out1”用于分类,和“out2”回归。
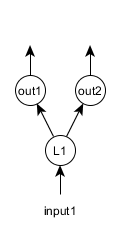
在这种情况下,网络配置是:
ComputationGraphConfiguration conf = new NeuralNetConfiguration.Builder()
.updater(new Sgd(0.01))
.graphBuilder()
.addInputs("input")
.addLayer("L1", new DenseLayer.Builder().nIn(3).nOut(4).build(), "input")
.addLayer("out1", new OutputLayer.Builder()
.lossFunction(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nIn(4).nOut(3).build(), "L1")
.addLayer("out2", new OutputLayer.Builder()
.lossFunction(LossFunctions.LossFunction.MSE)
.nIn(4).nOut(2).build(), "L1")
.setOutputs("out1","out2")
.build();
自动添加预处理器和计算nIns
ComputationGraphConfiguration的一个特性是,你可以使用配置中的.setInputTypes(InputType...)方法来指定网络的输入类型。
setInputType 有两个作用:
- 它将根据需要自动添加任何输入预处理器。输入预处理器对于处理例如全连接(密连)层和卷积层,或者循环和全连接层之间的交互是必需的。
- 它将自动计算一个层的输入数(.nin(x)配置)。因此,如果你使用的是setInputTypes(InputType...)功能,则无需手动指定配置中的.nIn(x)选项。这可以简化构建一些架构(例如具有完全连接层的卷积网络)。如果为层指定了.nIn(x),则当使用InputType功能时,网络将不覆盖此。
例如,如果你的网络有2个输入,一个是卷积输入,另一个是前馈输入,那么你将使用.setInputTypes(InputType.convolutional(depth,width,height), InputType.feedForward(feedForwardInputSize))。
为计算图训练数据
有两种类型的数据可以与计算图一起使用。
DataSet 与 DataSetIterator
DataSet类最初是为与MultiLayerNetwork一起使用而设计的,但是也可以与ComputationGraph一起使用,但前提是该计算图具有单个输入和输出数组。对于具有多个输入数组或多个输出数组的计算图架构,不能使用DataSet和DataSetIterator(相反,使用MultiDataSet/MultiDataSetIterator)。
DataSet对象基本上是一对容纳你的训练数据的INDArray 。在RNNs的情况下,它也可以包括掩蔽阵列(参见这个详细信息)。DataSetIterator本质上是DataSet对象上的迭代器。
MultiDataSet 与 MultiDataSetIterator
MultiDataSet是DataSet的多输入和/或多输出版本。在神经网络的情况下,它还可以包括多个掩模阵列(对于每个输入/输出阵列)。作为一般规则,除非使用多个输入和/或多个输出,否则应使用DataSet/DataSetIterator。
当前有两种方式使用MultiDataSetIterator:
- 通过直接实现 MultiDataSetIterator 接口
- 与DataVec记录读取器结合使用RecordReaderMultiDataSetIterator
RecordReaderMultiDataSetIterator提供了多个加载数据的选项。特别地,RecordReaderMultiDataSetIterator提供以下功能:
- 可以同时使用多个DataVec记录读取器
- 记录读取器不必是相同的模式:例如,可以把CSV记录读取器与图像记录读取器一起使用。
- 可以出于不同的目的使用RecordReader中的列的子集——例如,CSV中的前10列可以是你的输入,而后5列可以是你的输出。
- 将单个列从类索引转换为one-hot表示是可能的。
如下是如何使用 RecordReaderMultiDataSetIterator 的示例。你可能也能找到这些有用的单元测试。
RecordReaderMultiDataSetIterator 示例1:回归数据
Suppose we have a CSV file with 5 columns, and we want to use the first 3 as our input, and the last 2 columns as our output (for regression). We can build a MultiDataSetIterator to do this as follows:
int numLinesToSkip = 0;
String fileDelimiter = ",";
RecordReader rr = new CSVRecordReader(numLinesToSkip,fileDelimiter);
String csvPath = "/path/to/my/file.csv";
rr.initialize(new FileSplit(new File(csvPath)));
int batchSize = 4;
MultiDataSetIterator iterator = new RecordReaderMultiDataSetIterator.Builder(batchSize)
.addReader("myReader",rr)
.addInput("myReader",0,2) //Input: columns 0 to 2 inclusive
.addOutput("myReader",3,4) //Output: columns 3 to 4 inclusive
.build();
RecordReaderMultiDataSetIterator 例2:分类和多任务学习
假设我们有两个单独的CSV文件,一个用于我们的输入,一个用于我们的输出。进一步假设我们正在构建一个多任务学习架构,其中有两个输出-一个用于分类。对于这个例子,假设数据如下:
- 输入文件:myInput.csv,我们希望使用所有列作为输入(没有修改)
- 输出文件: myOutput.csv.
- 网络输入1 - 回归: 列 0 到 3
- 网络输出 2 - 分类: 列 4是分类索引,有3个类。因此,列4只包含整数值[0,1,2],我们希望将这些索引转换为one-hot表示以进行分类。
在这种情况下,我们可以构建如下的迭代器:
int numLinesToSkip = 0;
String fileDelimiter = ",";
RecordReader featuresReader = new CSVRecordReader(numLinesToSkip,fileDelimiter);
String featuresCsvPath = "/path/to/my/myInput.csv";
featuresReader.initialize(new FileSplit(new File(featuresCsvPath)));
RecordReader labelsReader = new CSVRecordReader(numLinesToSkip,fileDelimiter);
String labelsCsvPath = "/path/to/my/myOutput.csv";
labelsReader.initialize(new FileSplit(new File(labelsCsvPath)));
int batchSize = 4;
int numClasses = 3;
MultiDataSetIterator iterator = new RecordReaderMultiDataSetIterator.Builder(batchSize)
.addReader("csvInput", featuresReader)
.addReader("csvLabels", labelsReader)
.addInput("csvInput") //输入: 来自读取器的所有列
.addOutput("csvLabels", 0, 3) //输出 1: 列 0 到 3 包括3
.addOutputOneHot("csvLabels", 4, numClasses) //输出 2: 列4 -> 为分类转换为one-hot
.build();