spring-data-jpa基础
引入
一方面,现在大多数公司使用微服务,微服务将项目拆分开了,很少用到联查。另一方面,虽然现在我们使用的mybatis也很好用,但是配置文件太多,并且会额外生成一个example和一个mapper,还是很复杂。这种情况下就可以使用spring data jpa,因为spring data jpa零配置,他的接口api中也封装了很多方法,并且sql使用也很灵活。
Spring-data-jpa官网
Spring-data-jpa的优点
零配置,使用简单。
Spring-data-jpa是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展,大大降低了持久层的工作量。我们只需要定义接口并集成springdatajpa中所提供的接口就可以了,不需要编写接口实现类。
1、简化了我们的持久层开发工作,可以让我们持久层不用去书写具体实现代码,直接写一个继承Repository接口的Dao层接口,然后开启JPA的注解扫描就可以进行持久层开发了(开启注解后,会自动扫描所有继承了Repository接口的子接口或者子实现,并自动将它交给Spring去进行管理,可以说是很好的与Spring整合)。
2、SpringDataJPA提供了一些常用的ACID抽象方法,我们可以直接拿来使用,此外,还提供了属性表达式、命名查询、Query注解等方式供我们使用。
3、SptingDataJPA简化了分页的业务处理,他的Repository接口实现了
PagingAndSortingRepository接口,我们要做的只是将相关数据封装到接口
PagingAndSortingRepository中的findAll()方法中,它自动给我们返回Page对象,我们可以针对返回的Page对象根据我们的需求自动解析并封装成我们想要的JSON数据。
JPA、Hiberate、Spring-data-jpa三者之间的关系
JPA是ORM规范,jpa是对Hibernate、TopLink的封装(mybatis是半自动的orm框架,spring data jpa不对其封装),这样的好处是开发者可以面向JPA规范进行持久层的开发,而底层的实现(Hibernate对数据库进行操作)则是可以切换的。Spring Data Jpa则是在JPA之上添加另一层抽象(Repository层的实现),极大地简化持久层开发及ORM框架切换的成本。
知识点
JPA自带的几种主键生成策略
1、TABLE:JPA提供的一种机制,通过一张数据库表的形式帮助我们完成主键自增。
生成主键时,不在借助数据库,而是JPA程序来做,维护一张表,表中有主键的值。也就是说,当生成策略为TABLE时,会生成两张表,一张是用户表,一张为存放主键的表,存放的为下一个主键的值。
2、SEQUENCE:根据底层数据库的序列化来生成主键,条件是数据库支持序列(如oracle)。这个值要与generator一起使用,generator指定生成主键使用的生成器。
3、IDENTITY:主键由数据库自动生成(主要是支持自动增长的数据库,如mysql)
4、AUTO:主键由程序帮助选择,也是GenerationType的默认值。
TABLE和AUTO只要理解就可以了,mysql的话用IDENTITY,orcale用SEQUENCE。
Spring data jpa的常用注解
1、@Entity 声明一个实体类。
2、@Table 指定这个类对应数据库中的表名。如果这个类名的命名方式符合数据库的命名方式,可以省略这个注解。如FlowType类名对应表名flow_type。
3、@Id 指定这个字段为表的主键
4、@GeneratedValue(strategy=GenerationType.IDENTITY) 指定主键的生成方式,一般主键为自增的话,就采用GenerationType.IDENTITY的生成方式。
5、@Column() 声明实体类属性名对应的表字段名称。有很多参数,name表示对应数据表中的字段名。insertable 表示插入式是否更新。updateable,表示update的时候是否更新;columnDefinition表示字段类型,当使用jpa自动生成表的时候比较有用。
6、@MappedSuperclass 表示一个这是一个父类,不会被当成一个实体类。在这里定义一些表中的通用字段。然后其他实体类继承这个类就可以了,避免写重复代码。
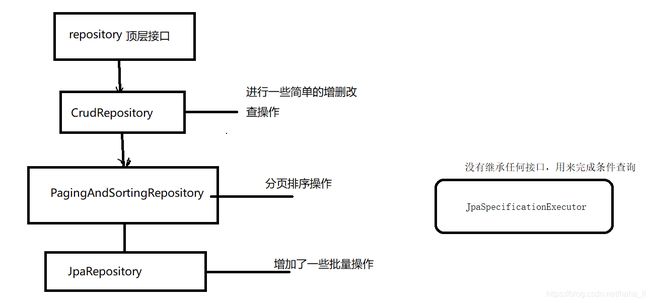
Spring Data JPA提供的接口类(Spring Data JPA的核心API)
1、Repository:最顶层的接口,是一个空的接口,目的是为了统一所有Repository的类型,且能让组件扫描的时候自动识别。Repository
3、PagingAndSortingRepository:是CrudRepository的子接口,添加分页和排序的功能。
4、JpaRepository:是PagingAndSortingRepository的子接口,增加了一些实用的功能,比如:批量操作等。对父接口中的方法,对返回值做适配处理。如果有分页操作,一般继承这个类。
5、JpaSpecificationExecutor:没有继承任何接口,用来完成条件查询。
Specification:是Spring Data JPA提供的一个查询规范,要做复杂的查询,只需围绕这个规范来设置查询条件即可。
创建JPA接口类
创建一个接口,需要继承spring data jpa提供的接口类。
public interface SpringdataJpaRepository extends JpaRepository
}
第一个参数为实体类,第二个参数为实体类的主键ID。
Spring-boot整合Spring-data-jpa 依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--引入pageHelper分页插件 PageInfo -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.5</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<!--导入静态资源webjars-->
<dependency>
<groupId>org.webjars</groupId>
<artifactId>jquery</artifactId>
<version>3.4.1</version>
</dependency>
<!--引入bootstrap-->
<dependency>
<groupId>org.webjars</groupId>
<artifactId>bootstrap</artifactId>
<version>4.3.1</version>
</dependency>
<!--mysql的驱动包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.0.5</version>
</dependency>
<!-- 阿里巴巴 数据源 druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
</dependencies>
Application.yml
server:
port: 8080
spring:
thymeleaf:
cache: false
#加载数据源
datasource:
username: root
password: 1234
url: jdbc:mysql://localhost:3306/spring_data_jpa?useUnicode=true&characterEncoding=utf8
driver-class-name: com.mysql.jdbc.Driver
#使用druid数据源
type: com.alibaba.druid.pool.DruidDataSource
#配置jpa
jpa:
database: MySQL
#hibernate方言
database-platform: org.hibernate.dialect.MySQL5InnoDBDialect
show-sql: true
hibernate:
# 指定ddl语句的形式,自动根据实体创建表。有四个属性可配置
# create—-每次运行该程序,没有表格会新建表格,表内有数据会清空
# create-drop—-每次程序结束的时候会清空表
# update—-每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新
# validate—-运行程序会校验数据与数据库的字段类型是否相同,不同会报错
ddl-auto: update
naming:
# 是否在日志里打印出sql语句,默认为false
show-sql: true
properties:
# 是否格式化生成的sql语句,默认为false。
hibernate.format_sql: true
# 建表的命名规则,生成的数据库字段名带有下划线分隔
physical-strategy: org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
# 配置初始化大小、最小、最大
maxActive: 20
initialSize: 5
minIdle: 5
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
#时间转换
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
配置数据源
@Configuration
public class DataSourceConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource getDataSource(){
return new DruidDataSource();
}
}
创建实体类
这里我使用的Spring data jpa整合的hibernate。因为hibernate是对数据表的完整性控制,创建好实体类后,就会自动生成数据表。
时间转换
1.jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
2.@JsonFormat(timezone = “GMT+8”, pattern = “yyyyMMddHHmmss”)
package com.dk.pojo;
import org.springframework.format.annotation.DateTimeFormat;
import javax.persistence.*;
import java.util.Date;
@Entity//声明实体类
@Table(name="tab_user")//实体类和表的映射关系,name为是数据表的名称,如TabUser类名对应表名tab_user,这种可以省略不写
public class TabUser {
@Id//声明主键
@GeneratedValue(strategy = GenerationType.IDENTITY)//配置主键生成策略
@Column(name="user_id")//属性和数据表字段的对应关系,如userId属性名对应表字段名user_id,这种也可以省略不写
private Integer userId;
@Column(name="user_name")
private String userName;
@Column(name="user_birth")
//@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss",timezone = "GMT+8")//时间转换
private Date userBirth;
@Column(name="user_sex")
private String userSex;
@Column(name="user_class")
private String userClass;
public Integer getUserId() {
return userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public Date getUserBirth() {
return userBirth;
}
public void setUserBirth(Date userBirth) {
this.userBirth = userBirth;
}
public String getUserSex() {
return userSex;
}
public void setUserSex(String userSex) {
this.userSex = userSex;
}
public String getUserClass() {
return userClass;
}
public void setUserClass(String userClass) {
this.userClass = userClass;
}
}
Controller层
@Controller
@RequestMapping("tabUserController")
public class TabUserController {
@Resource
private TabUserService tabUserService;
// 查询所有
@RequestMapping("getInfo")
@ResponseBody
public List<TabUser> getInfo(){
List<TabUser> list = tabUserService.findAll();
return list;
}
// 增加
@RequestMapping("addUser")
@ResponseBody
public boolean addUser(TabUser tabUser) {
tabUserService.saveInfo(tabUser);
return true;
}
// 根据id查询
@RequestMapping("findById")
public String findById(Integer id, Model model) throws Exception{
TabUser tbUser = tabUserService.findById(id);
model.addAttribute("tbUser",tbUser);
System.out.println(tbUser);
return "update";
}
//修改
@RequestMapping("updateUser")
@ResponseBody
public boolean updateUser(TabUser tabUser){
tabUserService.updateTabUser(tabUser);
return true;
}
@RequestMapping("deleteUser/{userId}")
@ResponseBody
public boolean deleteUser(@PathVariable("userId")Integer userId){
tabUserService.deleteById(userId);
return true;
}
}
ServiceImpl层
@Service
public class TabUserServiceImpl implements TabUserService {
@Autowired
private TabUserJPARepository tabUserJPARepository;
@Override
public List<TabUser> findAll() {
return tabUserJPARepository.findAll();
}
@Override
public void saveInfo(TabUser tabUser) {
tabUserJPARepository.save(tabUser);
}
@Override
public void deleteById(Integer userId) {
tabUserJPARepository.deleteById(userId);
}
@Override
public void updateTabUser(TabUser tabUser) {
tabUserJPARepository.saveAndFlush(tabUser);
}
@Override
public TabUser findById(Integer id) {
// springdatajpa底层会调用两种方式查询:
//一种为getReference查询方式:获取的是代理对象,延时加载不会立即发送sql语句,当调用查询对象时,才发送sql语句。好处是不会造成浪费。
// 另一种为find方式,立即加载。当调用find方法时,会立即发送sql语句。
// findOne调用的是find方法
// getOne调用的是getReference方法。
// 直接调用findById返回的是一个代理对象,调用get()返回实体对象。
return tabUserJPARepository.findById(id).get();
}
}
查询方式
1、方法名规则查询
精确查询:findBy+属性名称
TabUser findByUserName(String 李四);
模糊查询:findBy+属性名称+查询方式(like/isnull/…)
用Containing代替Like
findByUserNameContaining(参数)
List<TbUser> findByUserNameContaining(String 小);
用jpql语句用concat()
@Query(value = "from TbUser where userName like CONCAT('%',?1,'%')")
List<TbUser> findByUserNameLike(String 小);
多条件查询:findBy+属性名称+查询方式+多条件连接符(and/or/…)+其他属性名+其他属性名的查询方式。(默认情况下不加查询方式为精确查询)
// 多条件查询时,一定要注意方法名和参数到的顺序一定要保持一致
List<TabUser> findByUserNameLikeAndUserSex(String r, String 女);
| 关键词 | SQL符号 | 样例 | 对应JPQL 语句片段 |
|---|---|---|---|
| And | and | findByLastnameAndFirstname | where x.lastname = ?1 and x.firstname = ?2 |
| Or | or | findByLastnameOrFirstname | where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | = | findByFirstname,findByFirstnameIs,findByFirstnameEquals | where x.firstname = ?1 |
| Between | between a and b | findByStartDateBetween | where x.startDate between ? 1 and ?2 |
| LessThan | < | findByAgeLessThan | where x.age < ?1 |
| LessThanEqual | <= | findByAgeLessThanEqual | where x.age <= ?1 |
| GreaterThan | > | findByAgeGreaterThan | where x.age > ?1 |
| GreaterThanEqual | >= | findByAgeGreaterThanEqual | where x.age >= ?1 |
| After | > | findByStartDateAfter | where x.startDate > ?1 |
| Before | < | findByStartDateBefore | where x.startDate < ?1 |
| IsNull | is null | findByAgeIsNull | where x.age is null |
| IsNotNull,NotNull | is not null | findByAge(Is)NotNull | where x.age not null |
| Like | like | findByFirstnameLike | where x.firstname like ?1 |
| NotLike | not like | findByFirstnameNotLike | where x.firstname not like ?1 |
| StartingWith | like ‘xxx%’ | findByFirstnameStartingWith | where name like ?(%xxx) |
| EndingWith | like ‘xxx%’ | findByFirstnameEndingWith | where name like ?( xxx%) |
| Containing | like ‘%xxx%’ | findByFirstnameContaining | where name like ?(%xxx %) |
| OrderBy | order by | findByAgeOrderByLastnameDesc | where age = ?1 order by grade desc |
| Not | <> | findByLastnameNot | where x.lastname <> ?1 |
| In | in() | findByAgeIn(Collection ages) | where x.age in ?1 |
| NotIn | not in() | findByAgeNotIn(Collection ages) | where x.age not in ?1 |
| TRUE | =true | findByActiveTrue() | where x.active = true |
| FALSE | =false | findByActiveFalse() | where x.active = false |
| IgnoreCase | upper(xxx)=upper(yyyy) | findByFirstnameIgnoreCase |
2、基于@Query注解的查询
① Jpql查询(jpa查询语句)
特点:语法中关键字为类和类中的属性(和hql语句类似)。Jpql语句通过在jpa接口上通过注解的方式配置@Query
1)根据名称查询
// springboot低版本时,不加索引,idea中会有警告,但不影响代码运行
// springboot高版本中必须加上索引
@Query(value = "from TabUser where userName=?1")
TabUser findByName(String reyi);
2)根据指定名称和id查询。
//参数的顺序和索引一致
@Query(value = "from TabUser where userName=?1 and userId=?2")
TabUser findByNameAndId(String reyi, int i);
3)Jpql语句执行更新操作
再加上@Modifying(代表更新操作),还需要手动加上事物相关的支持@Transactional。
// 更新数据时必须加上@Modifying
@Modifying
@Query(value = "update TabUser set userName=?1 where userId=?2")
void updateUserInfo(String lisi, int i);
注意事项:
1、在@Query注解中编写JPQL实现DELETE和UPDATE操作的时候必须加上@modifying注解,以通知Spring Data 这是一个DELETE或UPDATE操作。
2、UPDATE或者DELETE操作需要使用事务,此时需要 定义Service层,在Service层的方法上添加事务操作。
3、注意JPQL不支持INSERT操作。
4、Jpql语句也不支持*。
② Sql语句查询
//sql语句查询,需要加上nativeQuery = true
// nativeQuery是否使用本地查询
// true为使用本地配置,及使用sql语句
// false不开启本地配置,及使用的是jpql语句
@Query(value = "select * from tab_user where user_name=?1",nativeQuery = true)
TabUser findByNameSql(String reyi);
//注意参数顺序要和索引一致
@Query(value = "select * from tab_user where user_name=?1 and user_id=?2",nativeQuery = true)
TabUser findByNameAndIdSql(String reyi, int i);
分页和排序(jpa页码从0开始)
1、继承分页接口PagingAndSortingRepository.(适用于简单的分页)
使用分页接口类提供的方法findAll(Pageable pageable)。
参数pageable为分页参数,将分页条数和开始位置放在分页参数中。
参数sort为排序参数。
@Override
public Page<TabUser> testPage() {
// Pageable pageable = new PageRequest(pageNum,pagesize,sort);
// 参数1:当前页数。参数2:每页条数。参数3:排序
// 分页
Page<TabUser> page =tabUserJPARepository.findAll(new PageRequest(0,5));
// 分页排序
Sort sort = new Sort(Sort.Direction.DESC,"userBirth");
tabUserJPARepository.findAll(PageRequest.of(0,5,sort));
return page;
}
2、使用jpql/sql语句分页(比较灵活)
由于Pageable参数支持排序功能,如果在sql语句中同时使用了ORDER进行排序,就会产生冲突。所以只能二选一。
ServiceImpl:
/// 分页
// Pageable pageable = PageRequest.of(0,5);
// Page page = tabUserJPARepository.getPageInfo(pageable);
// 排序字段为数据库字段值,不是实体类属性
Sort sort = new Sort(Sort.Direction.DESC,"user_birth");
// 分页排序
Pageable pageable = PageRequest.of(0,5,sort);
Page<TabUser> page = tabUserJPARepository.getPageInfo(pageable);
return page;
Repository:
// sql分页
@Query(value = "select * from tab_user",countQuery = "select count(*) from tab_user" ,nativeQuery = true)
Page<TabUser> getPageInfo(Pageable pageable);
// jpql分页
@Query(value = "from TabUser",countQuery = "select count(userId) from TabUser")
Page<TabUser> getPageInfo(Pageable pageable);
批量增加、修改
调用saveAll().这个方法时循环操作的。一般来说对数据库的操作不建议使用循环操作,浪费内存空间。
@Override
public void saveAll(List<TabUser> list) {
// 该方法底层为循环操作,在进行数据库操作时,不建议循环添加或修改。
tabUserJPARepository.saveAll(list);
}
批量删除
删除和修改时必须加上事物
1、fpql/sql实现批量删除
// 删除和修改操作时,必须加上@Modifying注解,service层加上事物@Transactional
@Modifying
@Query(value = "delete from tab_user where user_id in (?1)",nativeQuery = true)
void deleteUserById(List<Integer> list);
// 批量删除
@Modifying
@Query(value = "delete from TabUser where userId in (?1)")
void deleteUserById(List<Integer> list);
2、方法命名规则删除
@Override
@Transactional
public void deleteUserById(List<Integer> list) {
tabUserJPARepository.deleteByUserIdIn(list);
}
@Modifying
void deleteByUserIdIn(List<Integer> list);
3、自带的deleteAll()
@Override
@Transactional
public void deleteUserAll(List<TabUser> list) {
// 批量删除
tabUserJPARepository.deleteAll(list);
}
多表联查
接收多表关联返回结集,新建Vo类:该类中放你返回的数据,需要什么放什么。
Vo类:中放两个表中需要查的字段,生成相应的有参构造,set、get方法。不要加@Entity注解
package com.dk.pojo;
import java.util.Date;
public class TbUserClass {
private String userName;
private Date userBirth;
private String classRoom;
public TbUserClass(String userName, Date userBirth, String classRoom) {
this.userName = userName;
this.userBirth = userBirth;
this.classRoom = classRoom;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public Date getUserBirth() {
return userBirth;
}
public void setUserBirth(Date userBirth) {
this.userBirth = userBirth;
}
public String getClassRoom() {
return classRoom;
}
public void setClassRoom(String classRoom) {
this.classRoom = classRoom;
}
}
Repository接口
@Query(value = "select new com.dk.pojo.TbUserClass(tu.userName,tu.userBirth,tc.classRoom) from TbUser tu left join TbClass tc on tu.cid=tc.cid")
List<TbUserClass> getUserClass();
**注意:**写sql时
@Query(value = "SELECT new com.dk.pojo.XXXVo( a.xxx,b.xxx)FROM XXX a inner JOIN YYY b on a.id=b.xxid WHERE XXXX= :XXX")
再次强调 new 绝对不能少,后面最好跟全限定类名(不写有可能找不到这个类),还有new com.dk.pojo.XXXVo( )括号里面写你查得东西,注意这里面返回数据顺序要和你实体类中构造方法参数顺序一致,否则会出错。