Redis深度历险 读书笔记
Redis基础数据结构
String(字符串)、 list(列表)、 hash(字典)、set(集合)、zset(有序集合)
String
Redis的字符串是动态字符串,可以进行修改,内部结构实现类似于ArrayList,采用预分配冗余空间 的方式减少内存的频繁分配。字符串的最大长度为512MB
- 添加一个字符串 set name value
- 获取一个字符串 get name
- 判断是否存在 exists name
- 删除 del name
- 添加多个字符串 mset name1 value1 name2 value2
- 获取多个字符串 mget name1 name2
- 设置过期时间(秒) expire name 5
- 自增 incr name 10 自增存在范围, 范围在signed long的最大值最小值之间,超出会报错。
字符串由多个字节组成,每个字节由8个bit组成。
List
Redis的list类似于LinkedList,由链表组成。插入和删除很快,时间复杂度为O(1)。定位较慢,时间复杂度为O(n)。
通常用来做异步队列使用
- 先进先出(队列)
- push操作 rpush listname value1 value2 value3
- pop操作 lpop listname
- 先进后出(栈)
- push操作 rpush listname value1 value2 value3
- pop操作 rpop listname
- 通过下标获取 lindex listname 1
- 获取范围内元素 lrange listname 0 1
- 截取范围内元素 ltrim listname 0 1
Hash
Redis的Hash类似于HashMap,是一个无序字典,内部存储键值对。
- 添加 hset hash key value
- 添加多个 hmset hash key1 value1 key2 value2
- 获取单个 hget hash key
- 获取全部 hgetall hash
- 长度 hlen hash
Set
Redis的set类似于Java的HashSet,具有去重功能。
- 添加 sadd set value1
- 获取一个 spop set
- 获取全部 smembers set
- 判断是否存在 sismember set value1
- 获取长度 scard set
zset
Redis的zset类似于SortedSet和HashSet的结合体,一方面是一个set,另外给每一个value赋予一个score,代表排序权重。
- 添加 zadd zset 9.0 value1
- 按照score列出 zrange zset 0 -1
- 倒序列出 zrevrange zset 0 -1
- 获取value的score zscore zset value
- 排名 zrange zset value1
- 根据分值区间遍历 zrangebyscore zset 0 9.0
- 删除 zrem zset value1
zset内部排序通过“跳跃列表”实现。
list,set,hash,zset 四种数据结构是容器型数据结构。
- create if not exists: 如果不存在就会新建一个进行操作。
- drop if no elements: 容器中没有元素就会删除。
过期时间:Redis所有的数据结构都可以设置过期时间,时间到了会自动删除。过期以对象为单位,会删除整个数据结构,而不是删除其中的元素。如果一个字符串已经设置了过期时间,再调用set,过期时间会消失。
Redis应用
分布式锁
分布式应用在进行逻辑处理时,存在竞争,会出现并发问题。需要使用分布式锁来限制程序。
使用setnx(set if not exists)指令,只允许被一个客户端使用,使用后再调用del指令移除。当程序运行中出现异常或导致del指令不会执行,陷入死锁。因此可以加入一个过期时间,使用expire指令。
如果服务器在setnx和expire中间崩溃,expire不会执行,也会造成死锁。因此需要其他方法保证其原子性。
在Redis 2.8版本加入了set指令,使setnx和expire指令可以一起执行。set key value ex 5 nx
超时问题: 如果某一段程序运行过慢,在expire期间并没有执行完,第二个线程就会提前获取锁。因此,Redis尽量不要用于较长时间的任务。
可重入性:如果一个锁支持同一个线程多次加锁,那么这个锁就是可重入的。Redis分布式锁如果想支持可重入,需要对客户端的set方法进行包装,使用线程安全类Threadlocal变量存储当前持有锁的计数。
集群问题: 在集群中,当主节点挂掉时,从节点会取而代之。但是客户端对此并没有感知。比如客户端先从主节点获取到了锁,然后主节点挂掉,从节点取代。而新的主节点内部没有这个锁,当另一个客户端请求加锁,立即就批准了。这样会导致同一个锁会被多个客户端获取。
Redlock算法: 该算法会向过半节点发送set(key, value, nx=true, ex=xxx)指令, 只要过半节点set成功,就认为加锁成功。释放锁会向所有的节点发送del指令。Redlock算法会向多个节点进行读写,意味性能会下降。如果很在乎高可用性,可以考虑使用。代价就是丧失了性能。
延时队列
Redis可用list实现一个异步消息队列,使用rpush和lpush入队,lpop和rpop出队。但是没有ack确认,不能保证消息的可靠性。
如果队列空了,pop操作会陷入死循环,会造成提高客户端CPU消耗。可以使用blpop或brpop指令,字符b代表的是blocking,也就是 阻塞读。阻塞读在队列没有数据的时候立即进入休眠状态,数据到来继续操作。
当线程一直阻塞,Redis连接会变成闲置连接。闲置过久会与服务器断开连接,这个时候blpop或brpop会抛出异常。编写代码需要捕获异常进行处理。
延时队列的实现: 可以通过zset实现,消息为value,到期处理时间为score,然后使用多个线程轮询zset获取到期任务进行处理。多个线程保障可用性,也会带来并发问题。
位图
位图不是特殊的数据结构,内容就是普通的字符串,也就是byte数组。可以使用普通的get\set方法获取和设置。也可以使用getbit\setbit将byte数组看成“位数组”处理。
- Redis的位数组是自动填充的,如果某个偏移量超出了现有的内容范围,将会用0填充。
- 设置字符串时只需要设置值为的位。
- 可以进行按单个位或者整体set或get。
- 可以通过bitfield操作多个位。并且可以混合执行多个set/get/incrby指令。
- Redis提供了位图统计指令bitcount,用于统计指定位置范围1的个数。
HyperLogLog
HyperLogLog是Redis的高级数据结构,用来解决统计问题(不精确的去重计数),需要Redis版本>=2.8.9。例如,网站的浏览量、商品的销量。
HyperLogLog提供两个指令pfadd(增加计数)、pfcount(获取计数)、pfmerge(合并计数)。
HyperLogLog在计数比较少时,采用稀疏矩阵存储,空间占用很少。当占用空间超过阈值,就会转变成稠密矩阵,会占用12kb空间。
布隆过滤器
布隆过滤器用来解决去重问题(有一定的误判概率),需要Redis版本>=4.0。适用于大量用户的门户网站,可以判断出用户已经看过的内容。
布隆过滤器有两个基本指令,bf.add(添加单个元素) bf.madd(添加多个元素) bf.exists(查询单个元素是否存在) bf.mexists(查询多个元素是否存在)
布隆过滤器的误判率大概为1%,可以使用bf.reserver指令进行配置,降低误判率。
布隆过滤器原理:数据结构为一个大型的位数组和几个不一样的无偏hash函数(能够把元素的hash值计算的比较均匀,位置更加随机)。
添加值时,会用多个hash函数对key进行hash,然后对数组长度取模得到位置,每个hash函数会算的一个不同的位置。然后把位数组的这几个位置都置1,就完成了添加。
查询是否存在时,也是这么计算位置,看看位数组中这几个位置是否都为1,如果有一个为0,就不存在。
存在hash冲突问题,当查询是否存在的位置时,可能是别的key存在导致的。 这也是存在误判的原因。
Redis-Cell
Redis4.0提供的一个限流模块,使用了漏斗算法,提供了原子的限流指令。
scan指令
2.8版本加入,通过游标分步进行,不会阻塞线程。提供limit参数,不会一次返回过多的数据。返回的结果可能会有重复,需要进行去重。
Redis原理篇
Redis是一个高并发的 单线程 中间件。通过 非阻塞IO,多路复用 处理多客户端的连接。它所有的数据都在内存中所有操作都是内存级别
阻塞 I/O: 当使用 read 或者 write 对某一个文件描述符(File Descriptor)进行读写时,如果当前文件描述符不可读写,整个 Redis 服务就不会对其它操作作出响应。
非阻塞IO: 意味线程在对 文件描述符 读写时可以不必阻塞,读写可以瞬间完成。
多路复用: 最重要的API是 select 函数,该方法的能够同时监控多个文件描述符的可读可写情况,当其中的某些文件描述符可读或者可写时,select 方法就会返回可读以及可写的文件描述符个数。同时提供了一个timeout参数,如果没有任何事件到来,最多等待timeout的时间。一旦期间有任何时间到来,就可以立即返回。
现代操作系统的多路复用API已经不使用select调用,改用 epoll(linux) 和 kqueue
epoll(linux) 和 kqueue 需要继续深入了解 IO 多路复用
持久化
Redis的持久化有两种, RDB(快照)和AOF日志,两者各有优缺点。
RDB: 在指定的时间间隔能对数据进行全量备份。
优点:
1. 适用于数据集的备份。假如每天备份前一个月的数据, 出现问题后可回退到不同时间线的版本
2. RDB是一个紧凑的单一文件, 可以直接进行文件传输,解决问题
3. 与AOF相比,在恢复大的数据集的时候, RDB 方式会更快一些
缺点:
5. 会隔指定的时间才会进行备份, 因此在时间间隔内会丢失部分数据
6. RDB需要使用fork子进程进行快照。当数据集比较大时, fork非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求
fork(多进程): Redis在持久化时会调用glibc的函数fork产生一个子进程,快照持久化给予子进程处理,父进程处理客户端请求。父进程中对数据的修改,不会影响到子进程持久化,子进程的数据在产生进程的一瞬间就凝固了,不会改变。父进程修改时会将数据复制分离出来。
AOF: 是连续的增量备份, 存储的是Redis服务器的顺序指令序列, 只记录对内存修改的操作。当服务器重启的时候会重新执行这些命令来恢复原始的数据。
优点:
1. AOF是一个只进行追加的文件, 更容易维护
2. AOF文件有序地保存了对数据库执行的所有写入操作,这些写入操作以Redis协议的格式保存,更易读。
缺点:
1. 与RDB相比,AOF生成的文件更大。文件较大时, 可以人工维护。提供了bgrewriteaof用于对AOF日志的瘦身.
2. 因为fsync的原因, 速度相比RDB也会较慢
fsync: 当程序对AOF进行写操作时,如果机器突然故障,那么AOF日志可能没完全刷到磁盘中,,会出现日志丢失。因此, Liunx的glibc提供了fsync函数, 可以指定文件内容强制刷到磁盘。但是fsync是一个IO操作,速度很慢。通常Redis每个1s左右执行一次fsync操作,1s的周期可以进行配置, 也可以用不调用fsync.
RDB 保存结果是单一紧凑文件,可以将文件备份,并且在恢复大量数据的时候,RDB方式的速度会比 AOF 方式的回复速度要快。但是由于备份频率不高,所以在回复数据的时候有可能丢失一段时间的数据,而且在数据集比较大的时候有可能对毫秒级的请求产生影响。
AOF 以顺序追加的方式记录操作日志,文件内容易读。fsync保证了AOF的可靠性, 默认每秒钟备份1次。当日志文件较大时, 速度会稍慢。
当然 如果你的数据只是在服务器运行的时候存在,你也可以不使用任何持久化方式。
Redis4.0 混合持久化: 将RDB和AOF日志存在一起。AOF不再是全量的日志,而是自持久化开始到持久化结束这段时间发生的增量AOF日志。这样在Redis重启时,先加载RDB再加载AOF,效率大幅度的提高。
Redis集群
CAP原理
- C: Consistent 一致性
- A: Availability 可用性
- P: Partition tolerance 分区容忍性
分布式系统节点分布于不同的机器上, 会有网络断开的风险,该场景称为网络分区
当网络分区发生时,两个节点无法通信,节点之间无法同步,因此一致性无法满足。当牺牲可用性,暂停节点后才可以满足一致性。
当网络分区发生时,一致性和可用性两难全
Redis 最终一致
Redis的主从同步是异步的,所以分布式的Redis不能满足一致性。当主节点修改数据,主从网络断开,主节点也会继续提供服务,因此满足了可用性
Redis保证最终一致性,从节点会努力追赶主节点,最终保持一致。
增量同步: Redis同步的是指令流,主节点将修改指令记录在本地的buffer中,然后将buffer中的指令同步到从节点。从节点一边执行指令,一边返回同步的位置(偏移量)。
buffer: buffer是一个定长的环形数组,当数组内容满了,会覆盖前面的数据。
如果网络不好,buffer中没有同步的指令可能被覆盖,从节点无法通过增量同步进行同步。需要使用快照同步
快照同步 : 首先需要在主节点上进行一次bgsave,将当前内存的数据快照到磁盘文件中,然后发送给从节点。从节点立即执行一次全量加载,加载之前先要将当前内存清空,加载完毕通知主节点继续进行增量同步。
快照同步进行时,主节点的buffer在不停的移动,如果同步时间过长或者buffer过小,导致buffer内存再次覆盖,极有可能陷入快照同步的死循环。需要配置合理的buffer大小,避免这种情况。
Redis Sentinel(哨兵)
Sentinel负责持续监控主从节点的健康,当主节点挂掉,自动选择一个最优的从节点切换成主节点。客户端连接集群时,会首先连接到Sentinel,通过Sentinel查询主节点的地址,然后连接主节点进行数据交互。
消息丢失: Redis采用主从复制,当主节点挂点,从节点没有收到全部的同步信息,这部分未同步的消息就会丢失。Sentinel无法保证信息完全不丢失,只能尽量保证消息少丢失。
Codis
Redis Cluster
Reids Cluster是Redis作者自己提供的Redis集群化解决方案。
Reids Cluster将所有数据划分为16384个槽位,每个节点负责其中一部分槽位。当客户端连接到集群时,也会得到一份集群的槽位配置信息。当客户客户端查找某一个Key时,可以直接定位到目标节点。
槽位定位算法:Reids Cluster默认会使用crc16算法进行hash,得到一个整数值,然后对16384进行取模来得到具体位置。也允许用户强制将某个key挂到特定槽位上。
Reids Cluster可以给每个主节点设置若干个从节点,当主节点故障后,集群会自动将某个从节点升级为主节点。
Reids Cluster是去中心化的,一个节点认为某个节点失联并不代表所有节点都认为它失联,集群有一次协商过程,当大部分节点认定某个节点失联,集群才会认为该节点失联。
Reids Cluster有两个特殊的error指令,一个是MOVED,一个是ASKING
- MOVED: 用于纠正槽位,当客户端向一个错误的节点发送指令后,该节点发现指令的key所在槽位不归自己管理,就会将目标节点的地址随同MOVED指令回复给客户端,让客户端连接这个节点获取数据。
- ASKING: 它用于临时纠正槽位。当槽位处于迁移中,指令首先会去旧节点访问。如果不存在,可能在迁移目标节点上,会通知客户端去新的节点尝试获取数据。这时就会返回一个ASKING ERROR携带上目标节点的地址。
Redis 拓展
Stream
Redis5.0增加了许多特色功能,多出了一个数据结构Stream,它是一个支持多播的可持久化消息队列。
Redis Stream有一个消息链表,将所有加入的消息串起来,每一个消息都有一个唯一的ID和对应内容,消息是持久化的。每一个Stream都有唯一的名称,他就是Key。可以挂多个消费者,每一个消费者会有个游标last_delivered_id
在Stream数组之上往前移动,表示当前消费者已经消费到哪条消息。每一个消费者都有一个Stream内唯一名称,消费者不会自动创建,需要单独使用指令创建。
消息的唯一ID的形式是 timestampInMillis-sequence,也就是时间戳-序列号,也可以由服务器自动生成,也可以由客户端指定,但是形式必须是“整数-整数”,而且后加入的消息ID必须大于前面的消息ID
每一个消费者是独立的,相互不影响,Stream内部的消息会被每一个消费者消费
消费者内部有一个状态变量pending_ids(PEL),它记录了当前已经被客户端读取,但是还没有ack的消息。如果客户端没有ack,就会在该变量里记录消息ID,一旦被ack,就会删除。、
可以不定义消费者的情况下进行Stream消费,xread指令可以将Stream当成普通的消息队列(list)使用。
Stream消息过多时,在xadd指令中提供了一个定长长度参数maxlen,可以清除旧消息,确保链表不超过指定长度。
Info指令
Redis诊断功能,Info:
- Server: 服务器运行的环境参数
- Clients: 客户端相关信息
- Memory: 服务器运行内存统计数据
- Persistence: 持久化信息
- Stats: 通用统计数据
- Replication: 持久化信息
- CPU: CPU使用情况
- Cluster: 集群信息
- KeySpace: 键值对统计数量信息
过期策略
Redis会将每个设置了过期时间放入一个独立的字典中,会定时遍历字典删除到期的Key。另外还会使用惰性策略来删除过期Key,就是客户端每次访问Key,先对其进行过期时间检查,过期了就立即删除。
定时扫描策略: Redis默认每秒进行10次扫描,过期扫描不会遍历整个字典,使用了贪心策略:
- 从过期字典中随机选出20个Key
- 删除这20个Key中已经过期的Key
- 如果过期的Key比例超过1/4,那就重复步骤1
防止循环过度,避免线程卡死,算法增加了扫描时间的上限,默认不会超过25ms
假设一个大型的Redis实例中所有的Key同时过期,那么Redis会持续循环扫描字典,直到过期Key变得稀疏才会停止,这就会导致线上服务出现卡顿。因此存在这样的场景时,需要注意一下,给这种Key的过期时间设置一个范围,不能一起同时处理。
从节点过期策略: 从节点不会进行过期扫描,从节点对过期的处理时被动的。主节点的Key到期时,会在AOF文件里增加一条del指令,同步到所有的从节点,从节点通过执行del指令进行删除,
Redis的LRU算法
当Redis内存超过物理内存限制时,内存的数据会开始和磁盘产生频繁的交换,会让Redis的性能急剧下降。
当内存超过最大内存限制后,Redis提供几种可选策略(maxmemory-policy)让用户自己决定:
- noeviction: 不会继续服务写请求,读请求与删除请求继续执行。默认淘汰策略
- volatile-lru: 尝试淘汰设置了过期时间的Key,最少使用的Key优先淘汰。没有设置过期时间的Key不会被淘汰。保证持久化的数据不会消失
- volatile-ttl: 与上类似,比较Key的剩余寿命的ttl值,越小越优先淘汰
- volatile-random: 与上类似,淘汰的Key是过期Key集合中随机的
- allkeys-lru: 淘汰集体的的Key对象
- allkeys-random: 淘汰随机的Key
volatile-xxx 策略针对过期时间的Key淘汰,allkeys-xxx 策略针对所有Key淘汰。如果只是拿Redis做缓存,建议使用allkeys-xxx策略。
LRU算法:该算法出了需要key/value字典外,还需要附加一个链表。当空间满的时候,会删除链表尾部元素。当字典的某个元素被访问,它的位置会移动到链表头部。因此链表的排列顺序就是元素最近被访问的时间顺序。
Redis的LRU算法:Redis使用的是一种近似LRU算法,LRU算法需要消耗大量的额外内存,因此没有使用。Redis给每一个Key增加了一个额外的小字段,该字段长度是24个bit,也就是最后一次被访问的时间戳。采用了懒惰处理,当Redis执行写操作,发现内存超出maxmemory,就会执行一次LRU淘汰算法,随机取样5个Key(该数字可以设置),然后淘汰掉最旧的Key,如果淘汰后内存还是超过maxmemory,就继续采样淘汰,直到内存低于maxmemory为止。
Redis的LRU淘汰算法,如何采样要看maxmemory-policy的设置。如果是allKeys,就从所有的Key字典中随机采样,如果是volatile,就从带过期时间的Key字典中采样。采样的数量取决于maxmemory-samples的设置,默认为5
LFU & LRU 详解
当采用LRU时,如果一个Key长时间不被访问,知识刚刚偶然被用户访问了一下,在LRU算法中,它是不容易被淘汰的。
LFU算法表示按最新的访问频率进行淘汰,比LRU更加精确地表示Key被访问的热度
通过下侧的源码分析,可以知道Redis每个对象都有的一个数据结构RedisObject,里面都有一个24bit的字段为lru,用来记录对象的热度。
LRU模式: lru字段存储的是Redis时钟的值,用于判断对象更新时间,在进行LRU淘汰时,通过此值进行判断。对象被访问时就会更新lru字段。
LFU模式: lru字段24bit用于存储两个值,分别为ldt (last decrement time) 和 logc (logistic counter)
logc占用8bit, 用于存储访问频次, 因为最大只能表示255,所以存储的为频率的对数值. 并且会随着时间减少,值越少越容易被回收。
为了确保新建对象不被回收,会被初始化一个大于零的值 LFU_INIT_VAL 默认为5
ldt占用16bit,用于存储上一次logc的更新时间. 长度短了,精度也会下降为分钟级别
ldt与LRU模式的lru字段是不同的,ldt不是在对象被访问的时候更新,而是在Redis的淘汰逻辑进行的时候更新. 淘汰都是使用随机策略
Redis4.0给淘汰策略配置参数 maxmemory-policy 增加了2个选项,分别为volatile-lfu和allkeys-lfu,分别为对带过期时间对象执行LFU以及对所有对象执行LFU
Redis的惰性删除
Redis虽然是单线程的,但是内部实际上并不是只有一个主线程,它还有几个异步线程专门用来处理一些耗时操作。
删除指令del, 当删除一个非常的对象,就会造成单线程的明显卡顿。在4.0版本 引入unlink指令,它能对删除进行懒处理,丢给后台线程来异步回收内存。
unlink指令在多线程或是集群环境不会出现并发问题,当unlink指令生效时就会使该键无效,其他客户端就无法访问了。
当使用unlink指令时,会将这个Key的内存回收操作包装成一个任务,塞进异步任务队列,后台线程会从这个异步队列(这是一个线程安全的队列)中取任务。如果Key所占用的内存很小,就不会延后处理了,会直接将Key的内存回收,跟del指令一样。
Redis 源码
字符串
Redis中的字符串是可以修改的字符串,在内存中它是以字节数组的形式存在。为了效率,Redis的String结构是一个带长度信息的字节数组
struct SDS {
T capacity; // 1bytes 数组容量 表示所分配的容量
T len; // 1bytes 数组长度 实际长度
byte flags; // 1bytes 特殊标志位
byte[] content; // 长度为capacity 数组内容
}
**两种存储方式: embstr & raw:**Redis字符串有两种存储方式,长度短时使用embstr存储,当长度超过44字节时,使用raw形式存储。
一个Redis对象头需要占据16bytes的存储空间
struct RedisObject {
int4 type; // 4bits 不同的对象有不同的类型
int4 encoding; // 4bits 同一类型会有不同的存储方式
int24 lru; // 24bits 记录对象LRU信息
int32 refcount; // 4bytes 引用计数,当为0,就会销毁
void *ptr; // 8bytes 指向对象内容
}
当SDS结构比较小时,SDS对象头结构大小是capacity+3,最小是3bytes,意味分配一个字符串的最小空间占用为19(对象头 + 最小SDS)
embstr将RedisObject和SDS对象连续存在一起,使用malloc方法一次分配,而raw需要使用两次分配。而内存分配器每次的单位为 2的指数次。当分配内存超过64bytes时Redis则会认为是一个大字符串,不适合使用embstr。使用embstr分配64bytes空间时,减去固定大小 19bytes(Redis对象头 + SDS)就是 45bytes,SDS结构体中content中的字符串是以字节NULL结尾,占用1bytes,所以embstr最大容纳的字符串长度就是44bytes
扩容策略:当字符串小于1MB之前,扩容采取加倍策略,保留100%的冗余空间。当字符串超过1MB之后,为了避免冗余空间过大而浪费,每次扩容只会多分配1MB大小的冗余空间
字典
字典是Redis中出现最频繁的复合数据结构,除了hash结构数据会用到字典,整个Redis中所有的key和value也组成了一个全局字典,还有带过期时间的key集合也是一个字典。zset集合中存储value和score值的映射关系也是通过字典实现。
字典结构: 字典结构内部包含两个hashtable,当进行扩容缩容,需要分配新的hashtable,然后进行渐进式搬迁,两个hashtable存储的分别是旧的hashtable和新的hashtable。搬迁结束后,旧的删除
hashtable是字典结构的核心,它的结构与Java的HashMap几乎一样,在hash冲突时采用分桶的方式解决,Java8中已经在此基础上会在冲突元素大于8的时候进化成红黑树。第一维是数组,第二维是链表。
渐进式 rehash: 大字典的扩容比较耗费时间,需要重新申请新的数组,然后将旧字典所有元素移到新字典,单线程的Redis很难承受这样的耗时过程,所以采用了渐进式rehash小步搬迁。
渐进式rehash的步骤
- 为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表
- 维持索引计数器变量rehashidx,并将它的值设置为0,表示rehash开始
- 每次对字典执行增删改查时,将ht[0]的rehashidx索引上的所有键值对rehash到ht[1],将rehashidx值+1。(从索引0到末尾)
- 当ht[0]的所有键值对全部被rehash到ht[1]中,程序将rehashidx的值设置为-1,表示rehash操作完成
在此过程中,字典的增删改查操作会同时在ht[0],ht[1]两个表上进行,比如:
- 查找一个键,会先在ht[0]中查找,没找到再到ht[1]中找。
- 新添加到字典的键值对一律会被保存到ht[1]中而不是ht[0].
渐进式rehash的好处在于它采取分而治之的方式,将rehash键值对的计算均摊到每个字典的增删改查操作上,避免了集中式rehash的庞大计算量。
扩容条件: 当hash表中的元素的个数等于第一维数组的长度时,就会开始扩容。扩容的新数组是原数组大小的2倍。如果Redis正在bgsave,尽量不去扩容。但是如果hash元素已经非常满了,元素的个数已经到达了第一维数组长度的5倍,将会强制扩容。
缩容条件: 当元素个数低于数组长度的10%。缩容不会考虑Redis是否正在进行bgsave
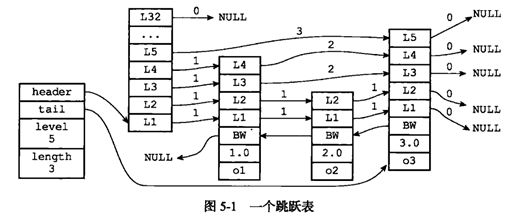
跳跃表
zset是一个复合结构,需要一个Hash结构存储value和score的对应关系,另一方面需要按照score进行排序,就有了另外一个结构“跳跃表”
跳跃表(skipList)是一种有序数据结构,他通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳跃表支持评价O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树来得更简单,所以有不少程序都是用跳跃表来代替平衡树。
Redis在两个地方用到了跳跃表,一个是实现有序集合键,另一个是在集群节点中用作内部数据结构。
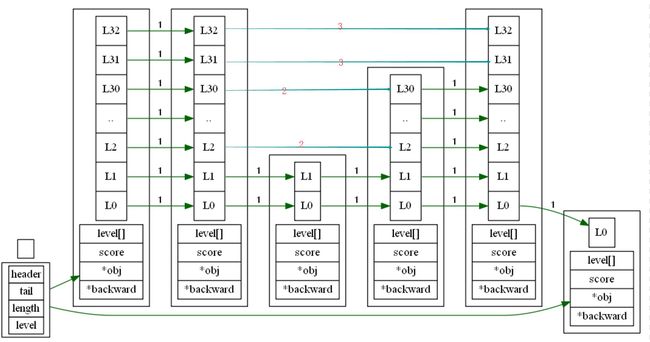

// 跳跃表节点
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
struct zskiplistNode *forward; //前进指针
unsigned int span; //跨度
} level[];
} zskiplistNode;
// 跳跃表
struct zskiplist {
// 头节点,尾节点
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 目前表内节点的最大层数
int level;
}
注意:表头节点和其他节点的构造是一样的, 只不过值为NULL,score为Double.MIN_VALUE,用来垫底
层: 跳跃表节点的level数组可以包含多个元素,每个元素都包含一个指向其他节点的指针,程序可以通过这些层来加快访问其他节点的速度,一般来说,层的数量越多,访问其他节点的速度就越快。
前进指针 forward: 当前节点沿着当前层指向的后一个节点。每个层都有一个指向表尾方向的前进指针,用于从表头向表尾方向访问节点。
后退指针 backward: 节点的后退指针用于从表尾向表头方向访问节点,每个节点只有一个后退指针,所以每次只能后退至前一个节点。
跨度 span:记录了前进指针所指向节点和当前节点的距离也就是从前一个节点沿着当前层的前进指针跳到当前节点中间会跳过多少个节点,每次新增、删除都会更新span的大小
查找过程: 首先会从最高层开始遍历找到最后一个比目标元素小的开始降一层,一直降低到找到目标元素
跳跃表进行查找过程中,如果score相同会对值进行比较
插入过程: 逐步降级寻找到目标节点, 找到搜索路径. 然后对于每层的相关节点填充跨度并重排前向后向指针并更新最高层数
删除过程与插入过程类似
更新过程: 更新值时先删除在插入,需要经过两次路径搜索