文本分类:cnews_loader.py模块详解
在学习文本分类过程中,以下笔记为对文本分类 cnews_loader.py 模块的解释说明
代码块说明
- 1.导入模块
- 2.python版本控制代码块
- 3.读取文件数据
- 4.建立词汇表
- 5.读取词汇表
- 6.读取目录
- 7.将文件转为id
- 8.生成批次数据
1.导入模块
导入必要的库
# coding: utf-8
import sys
from collections import Counter
import numpy as np
import tensorflow.keras as kr
2.python版本控制代码块
该代码块使整个程序可以在python 2.x 和 python 3.x的版本下运行
# 判断电脑中python的版本,从而执行不同的环境下的代码
if sys.version_info[0] > 2:
is_py3 = True
else:
imp.reload(sys)
# sys.setdefaultencoding("utf-8")
is_py3 = False
# native_word和native_content为转换字符编码
def native_word(word, encoding='utf-8-sig'):
"""如果在python2下面使用python3训练的模型,可考虑调用此函数转化一下字符编码"""
if not is_py3:
return word.encode(encoding)
else:
return word
def native_content(content):
if not is_py3:
return content.decode('utf-8')
else:
return content
# 在python 3.x版本下打开txt文件时,需要加上encoding='utf-8-sig',否则要报错'/ufeff'
def open_file(filename, mode='r'):
"""
常用文件操作,可在python2和python3间切换.
mode: 'r' or 'w' for read or write
"""
if is_py3:
return open(filename, mode, encoding='utf-8-sig', errors='ignore')
else:
return open(filename, mode)
3.读取文件数据
读取txt文件中的内容,并对其进行内容、标签的分类
def read_file(filename):
"""读取文件数据"""
contents, labels = [], []
with open_file(filename) as f:
for line in f:
try:
label, content = line.strip().split('\t')
if content:
contents.append(list(native_content(content)))
labels.append(native_content(label))
except:
pass
return contents, labels
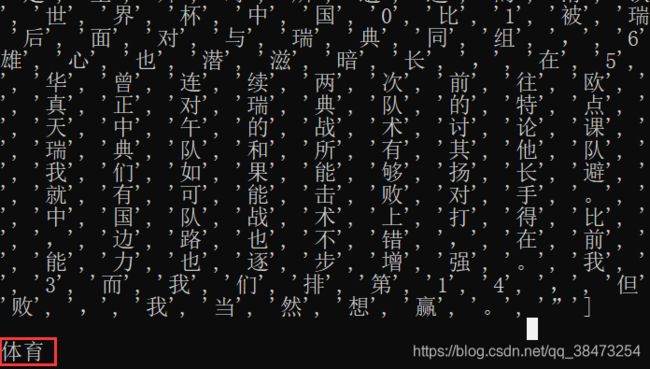
我们来看看进行到这一步,contents和labels里面的内容(由于训练集较大,我只选取了列表的第一行输出)
data_train, _ = read_file('data/cnews.train.txt')
print(data_train[1])
_, data_label = read_file('data/cnews.train.txt')
print(data_label[1])
data_train, _ 这个写法是参照下一函数的写法,可以只提取其中的一列进行输出或保存,我们来看一下输出结果,上面为内容(content)列表,下面为标签(label)
4.建立词汇表
根据训练集构建词汇表,并保存在vocab_dir目录
def build_vocab(train_dir, vocab_dir, vocab_size=5000):
"""根据训练集构建词汇表,存储"""
data_train, _ = read_file(train_dir) # 只提取内容部分
all_data = []
for content in data_train:
all_data.extend(content) # extend列表末尾追加多个值
counter = Counter(all_data)
count_pairs = counter.most_common(vocab_size - 1) # 显示前(vocab_size - 1)个元素
words, _ = list(zip(*count_pairs))
# 添加一个 <PAD> 来将所有文本pad为同一长度
words = ['' ] + list(words)
open(vocab_dir, mode='w', encoding='utf-8-sig').write('\n'.join(words) + '\n')
通过调用build_vocab()函数,我们来看一下输出结果
if __name__ == "__main__":
test_dir = 'data/cnews.test.txt'
train_dir = 'data/cnews.train.txt'
vocab_dir = 'data/cnews.vocab.txt'
contents, labels = read_file(train_dir)
build_vocab(train_dir, vocab_dir,vocab_size=5000)
到保存的目录中打开cnew.vocab.txt即可看到以下内容,代码中 ‘\n’ 使得每个词汇都换行显示
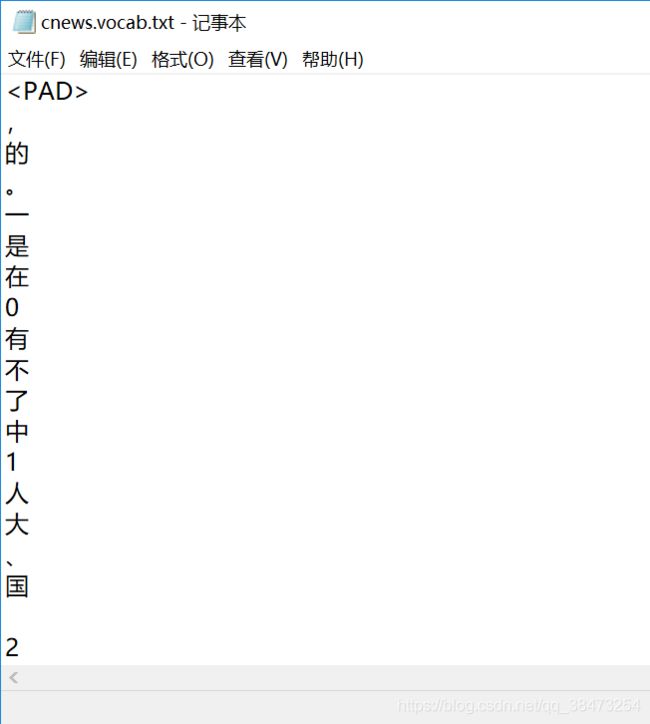
5.读取词汇表
读取保存的词汇表,保存为 words 和 word_to_id
def read_vocab(vocab_dir):
"""读取词汇表"""
# words = open_file(vocab_dir).read().strip().split('\n')
with open(vocab_dir, encoding='utf-8-sig') as fp:
words = [(_.strip()) for _ in fp.readlines] # in从而达到去重的目的
word_to_id = dict(zip(words, range(len(words))))
return words, word_to_id
在这里我想直接print()直接输出,但由于’\u2022’编译不出,所以我将其保存在txt文件中以便观察结果
![]()
列表不能直接存储到txt文件中去,所以需要将列表转为str再将其保存

这只是为了输出中间结果达到可视化而写的代码,实际过程中直接进行引用
# words为list格式,需要将其转为str格式
def ListToStr(listInfo, new_filename):
file_handle = open(new_filename, mode='a', encoding='utf-8-sig')
for idx in range(len(listInfo)):
str = listInfo[idx] # 列表指针
str_Result = str
file_handle.write(str_Result)
file_handle.close()
print('写入 %s 文件成功' % new_filename)
# word_to_id为dict,将字典转为str字符串
def DictToStr(dictInfo, new_filename):
file_handle = open(new_filename, mode='a', encoding='utf-8-sig')
file_handle.write(str(dictInfo))
file_handle.close()
print('写入 %s 文件成功' % new_filename)
if __name__ == "__main__":
vocab_dir = 'data/cnews.vocab.txt'
words_dir = 'data/read_vocab_words.txt'
word_to_id_dir = 'data/read_vocab_word_to_id.txt'
if not os.path.exists(vocab_dir):
build_vocab(train_dir, vocab_dir, vocab_size=5000)
# 转换为str格式保存到txt文件中去
words, word_to_id = read_vocab(vocab_dir)
ListToStr(words, words_dir)
DictToStr(word_to_id,word_to_id_dir)
word_to_id 使用上述 str = listInfo[idx] 办法不行,调用DictToStr()可以达到我们想要的结果

命令行显示成功,我们进入保存的目录打开txt文件,可看到下面的内容

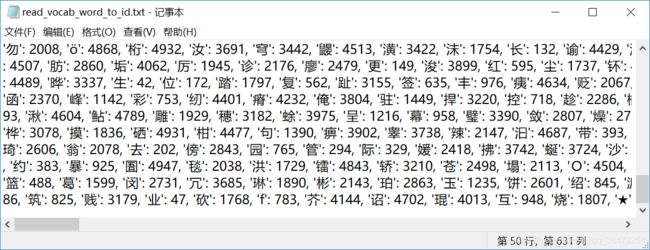
这里读取的词汇表read_vocab_words.txt和cnews数据集解压出来 cnews.vocab.txt是一样的
而read_vocab_word_to_id.txt可以看到每一个字都对应了唯一一个id
6.读取目录
设置分类的目录,去重返回 categories 和 cat_to_id
def read_category():
"""读取分类目录,固定"""
categories = ['体育', '财经', '房产', '家居', '教育',
'科技', '时尚', '时政', '游戏', '娱乐']
# categories = [x for x in categories]
cat_to_id = dict(zip(categories, range(len(categories))))
return categories, cat_to_id
我们来输出 categories 和 cat_to_id 看看
if __name__ == "__main__":
categories, cat_to_id = read_category()
print(categories)
print('\n')
print(cat_to_id)

categories为目录输入,cat_to_id可以看出每一个目录也有唯一一个id与之对应
7.将文件转为id
通过读取 train_dir 获取内容和标签,调用keras提供的pad_sequences来将文本pad为固定长度,将标签转换为one-hot表示
def to_words(content, words):
"""将id表示的内容转换为文字"""
return ''.join(words[x] for x in content)
def process_file(filename, word_to_id, cat_to_id, max_length=600):
"""将文件转换为id表示"""
contents, labels = read_file(filename)
data_id, label_id = [], []
for i in range(len(contents)):
data_id.append([word_to_id[x] for x in contents[i] if x in word_to_id])
label_id.append(cat_to_id[labels[i]])
# 使用keras提供的pad_sequences来将文本pad为固定长度
x_pad = kr.preprocessing.sequence.pad_sequences(data_id, max_length)
# 将标签转换为one-hot表示
y_pad = kr.utils.to_categorical(label_id, num_classes=len(cat_to_id))
return x_pad, y_pad
单独输出出现以下报错,因为x_pad, y_pad为数组形式,不能使用write()函数
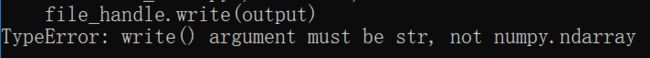
这里先将x_pad, y_pad转为list格式,再调用列表转为str的 ListToStr_new() 函数
# 另一种将列表转为str字符串的方法
def ListToStr_new(listInfo, new_filename):
file_handle = open(new_filename, mode='a', encoding='utf-8-sig')
# 先将列表的单个元素全部转为str型
listInfo_str = [str(i) for i in listInfo]
str_Result = ''.join(listInfo_str)
file_handle.write(str_Result)
file_handle.close()
print('写入 %s 文件成功' % new_filename)
if __name__ == "__main__":
# 自定义输出目录
x_pad_dir = 'data/x_pad.txt'
y_pad_dir = 'data/y_pad.txt'
# contents, labels = read_file(train_dir)
words, word_to_id = read_vocab(vocab_dir)
categories, cat_to_id = read_category()
x_pad, y_pad = process_file(train_dir, word_to_id, cat_to_id, max_length=600)
x_pad_list = x_pad.tolist()
y_pad_list = y_pad.tolist()
# x_pad, y_pad为数组,先将其转为list(列表),再调用ListToStr_new()
ListToStr_new(x_pad_list, x_pad_dir)
ListToStr_new(y_pad_list, y_pad_dir)
进入保存的目录,打开我们保存的txt文件,结果如下
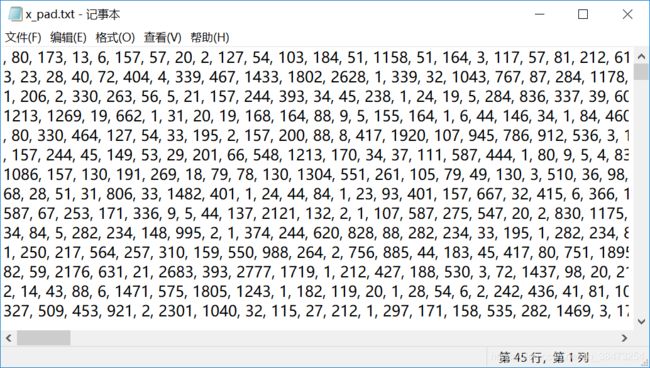

通过上图可以发现,x_pad将文本转为id格式,并且每个数组的长度相等为max_length=600,y_pad将标签转为one-hot编码格式
8.生成批次数据
生成批次数据,每个批次为 batch_size=64,打乱顺序返回每个批次的数据
def batch_iter(x, y, batch_size=64):
"""生成批次数据"""
data_len = len(x)
# + 1是防止data_len最后不足64的批次
num_batch = int((data_len - 1) / batch_size) + 1
# np.random.permutation 不在原数组上进行,返回新的数组,不改变自身数组
# np.arange()函数返回一个有终点和起点的固定步长的排列,一个参数时,参数值为终点
indices = np.random.permutation(np.arange(data_len))
x_shuffle = x[indices]
y_shuffle = y[indices]
for i in range(num_batch):
start_id = i * batch_size
end_id = min((i + 1) * batch_size, data_len) # 在批次中选最小的批次数据
yield x_shuffle[start_id:end_id], y_shuffle[start_id:end_id]