零基础入门NLP- 新闻⽂文本分类
零基础入门NLP- 新闻⽂文本分类
比赛地址https://tianchi.aliyun.com/competition/entrance/531810/introduction
Task1 赛题理理解
赛题数据为新闻文本,并按照字符级别进行匿名处理,整合划分出14个候选分类:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。
评测指标为类别f1_score的均值。
解题思路
思路1:TF-IDF+机器学习分类器
TF-IDF算法介绍
思路2:FastText
FastText介绍
思路3:word2vec+深度学习分类器
word2vec是一款进阶的词向量,深度学习分类器可以选用TextCNN、TextRNN或BiLSTM
思路4:Bert词向量
Task2 数据读取与数据分析
数据读取
import pandas as pd
train_df=pd.read_csv('./train_set.csv/train_set.csv',sep='\t')
train_df.head()

%pylab inline
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))#统计每一条文本的字符数量
print(train_df['text_len'].describe())

#绘制字符数量的直方图
_ = plt.hist(train_df['text_len'], bins=200)
plt.xlabel('Text char count')
plt.title("Histogram of char count")

#统计每个类别的文本数量
train_df['label'].value_counts().plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")

#统计每个单词出现的个数
from collections import Counter
all_lines = ' '.join(list(train_df['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print(len(word_count))
# 6869
print(word_count[0])
# ('3750', 7482224)
print(word_count[-1])
# ('3133', 1)
假设3750、900、648是标点符号,试统计每篇新闻平均由多少个句子组成?
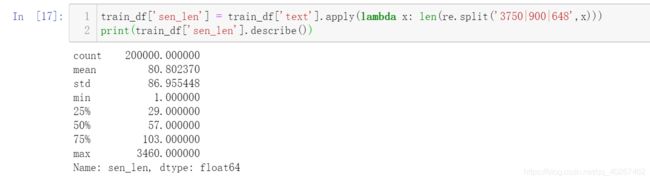
python内建的split()函数只能使用单个分隔符,re模块的split()函数可以使用多个分隔符对句子进行分割,其中不同的分隔符要用 “|” 隔开。
统计每类新闻中出现次数最多的字符
for i in range(14):
all_lines = ' '.join(list( train_df[train_df['label']==i]['text']))
word_count = Counter(all_lines.split(" "))
print(i,word_count.most_common(1))

most_common([n]),返回一个列表,其中包含 n 个最常见的元素及出现次数,按常见程度由高到低排序。 如果 n 被省略或为 None,most_common() 将返回计数器中的所有元素。计数值相等的元素按首次出现的顺序排序:
Task3 基于机器器学习的文本分类
3.1文本表示方法 Part1
文本表示分为离散表示和分布式表示。
离散表示的代表就是词袋模型,one-hot(也叫独热编码)、TF-IDF、n-gram都可以看作是词袋模型。
分布式表示也叫做词嵌入(word embedding),经典模型是word2vec,还包括后来的Glove、ELMO、GPT和最近很火的BERT。
3.1.1文本的离散表示
- OneHot
- Bag of words
直接用每个词在文档中出现的次数来表示
sklearn实现方式:
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
vectorizer.fit_transform(corpus).toarray()
- N-grams
n-gram是从一个句子中提取n个连续的字的集合,可以获取到字的前后信息。一般2-gram或者3-gram比较常见。 - TF-IDF
文本的离散表示存在着数据稀疏、向量维度过高、字词之间的关系无法度量的问题,适用于浅层的机器学习模型,不适用于深度学习模型。
3.1.2文本的分布式表示
3.2基于机器器学习的文本分类
接下来我们将对比不同文本表示算法的精度,通过本地验证集计算F1得分。
3.2.1Count Vectors + RidgeClassifier
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import f1_score
train_df = pd.read_csv('./train_set.csv/train_set.csv', sep='\t', nrows=15000)
vectorizer = CountVectorizer(max_features=3000) #构建一个计算词频(TF)的玩意儿
train_test = vectorizer.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
# 0.74
3.2.2 TF-IDF + RidgeClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
#train_df = pd.read_csv('./train_set.csv/train_set.csv', sep='\t', nrows=15000)
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=3000)
train_test = tfidf.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
# 0.87
TfidfVectorizer参数解释
max_df or min_df: [0.0, 1.0]内浮点数或正整数, 默认值=1.0
当设置为浮点数时,过滤出现在超过max_df/低于min_df比例的句子中的词语;正整数时,则是超过max_df句句子。
这样就可以帮助我们过滤掉出现太多的无意义词语。
stop_words: list类型 直接过滤掉停用词。
ngram_range: tuple
有时候我们觉得单个的词语作为特征还不足够,能够加入一些词组更好,就可以设置这个参数,如下面允许词表使用1个词语,或者2个词语的组合。
max_feature: int
大规模语料上训练TFIDF会得到非常多的词语,如果再使用了上一个设置加入了词组,那么我们词表的大小就会爆炸。出于时间和空间效率的考虑,可以限制最多使用多少个词语,模型会优先选取词频高的词语留下。
尝试改变TFIDF的参数并验证精度。
vocabulary:vocabulary是词典索引,例如 vocabulary={“我”:0,“喜欢”:1,“相国大人”:2}