7、JDK1.8HashMap源码分析系列文章(putMapEntries、tableSizeFor、hash、capacity)
目录
1、putMapEntries(Map m, boolean evict)
2、hash(Object key)
3、tableSizeFor(int cap)
4、capacity()
1、putMapEntries(Map m, boolean evict)
final void putMapEntries(Map m, boolean evict) {
// 获取待转移map的数据大小
int s = m.size();
// 如果s>0,说明存在数据,需要copy,否则不存在数据机型copy
if (s > 0) {
// 如果table为null(当前map中没有任何数据)
if (table == null) {
/**
* 根据copy数据的长度计算容量,正常情况下 threshold =(capacity * load factor),capacity 根据 table的长度确定,
* 但是现在 table 不存在,只有逆向计算,默认 copy数据的长度已达到扩容阈值,容量最小为1,需要向上取整。
* 计算出来的 capacity 不是2的倍数
*/
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ? (int)ft : MAXIMUM_CAPACITY);
// 只有在算出来的容量t > 当前暂存的容量(容量可能会暂放到阈值上的)时,才会用t计算出新容量,再暂时放到阈值上
if (t > threshold)
threshold = tableSizeFor(t);
/**
* 如果table不为null(当前map中有一部分数据),
* 当 s>扩容阈值时,传入map和当前map的并集的映射数量(即size)肯定会大于当前map的阈值的,
* 所以在循环放置新元素(最后循环的putVal操作)之前就应该resize,因为我们已经提前知道当前map不够放的
* 这句代码充分体现了HashMap的“懒汉模式”,因为resize是一个极其expensive的操作,应该是只在需要的时候做
*/
} else if (s > threshold)
// 扩容操作
resize();
// 对值进行copy
for (Map.Entry e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}2、hash(Object key)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}从上面的代码可以看到key的hash值的计算方法。key的hash值高16位不变,低16位与高16位异或作为key的最终hash值。(h >>> 16,表示无符号右移16位,高位补0,任何数跟0异或都是其本身,因此key的hash值高16位不变。)
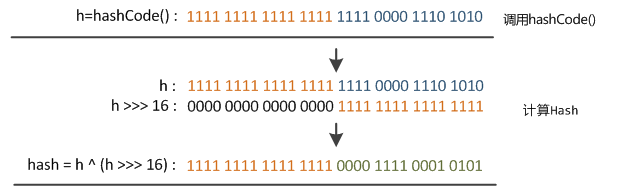
这个与HashMap中table下标的计算方法如下所示:
n = table.length;
index = (n-1) & hash;因为,table的长度都是2的幂,因此index仅与hash值的低n位有关,hash值的高位都被与操作置为0了。 假设table.length=2^4=16。

由上图可以看到,只有hash值的低4位参与了运算。 这样做很容易产生碰撞。设计者权衡了speed, utility, and quality,将高16位与低16位异或来减少这种影响。设计者考虑到现在的hashCode分布的已经很不错了,而且当发生较大碰撞时也用树形存储降低了冲突。仅仅异或一下,既减少了系统的开销,也不会造成的因为高位没有参与下标的计算(table长度比较小时),从而引起的碰撞。
3、tableSizeFor(int cap)
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}由此可以看到,当在实例化HashMap实例时,如果给定了initialCapacity,由于HashMap的capacity都是2的幂,因此这个方法用于找到大于等于initialCapacity的最小的2的幂(initialCapacity如果就是2的幂,则返回的还是这个数)。
然后逐条语句进行分析:
首先,为什么要对cap做减1操作。int n = cap - 1; 这是为了防止cap已经是2的幂。如果cap已经是2的幂, 又没有执行这个减1操作,则执行完后面的几条无符号右移操作之后,返回的capacity将是这个cap的2倍。
n |= n >>> 1;
任何一个数,只要不为0,它总有一个bit位的值为1,最坏的一种情况是最高位为1,无符号右移一位之后,再与本身进行或运算,这样就能使最高位和次高位的值均为1。然后以链式反应的形式来将数据各个位数全部变成1。
int 类型最多4个字节,故最多右移32位,超过这个阈值了之后,直接取最大值( MAXIMUM_CAPACITY)即可。
注意,得到的这个capacity却被赋值给了threshold。this.threshold = tableSizeFor(initialCapacity),在构造方法中,并没有对table这个成员变量进行初始化,table的初始化被推迟到了put方法中,在put方法中会对threshold重新计算。
4、capacity()
/**
* 获取 capacity (table数组的长度)的方法
* 如果数组不为空,返回数组的长度,
* 如果数组为空,扩容阈值大于0,默认扩容阈值为初始长度,否则返回默认初始容量16
* @return
*/
final int capacity() {
return (table != null) ? table.length :
(threshold > 0) ? threshold :
DEFAULT_INITIAL_CAPACITY;
}