《python爬虫学习》之爬取b站的完结动画列表
前言
继接口爬取和网页页面爬取两个练习后,闲着无聊我也四处去找一些合法网站练手,而这次想要爬取的网站是集鬼畜、二次元、学习等元素于一身的b站中的完结动画。
网站地址:https://www.bilibili.com/v/anime/finish/#/
废话不多说,开始我们的爬取。
步骤1:进入开发者模式

通过分析,可以知道我们要爬取的数据没有对应的接口文件,这就说明我们只能通过爬取网页的方法进行。
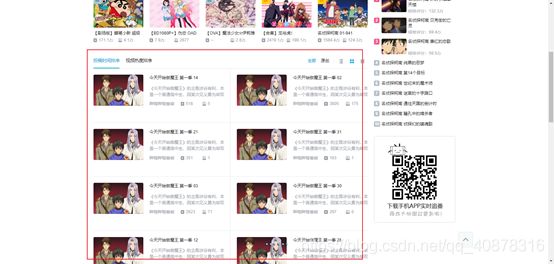
经过分析,我们可以得出我们想要的数据的路径为div[@class=” vd-list-cnt”]/ul/li/
步骤2:写爬虫
我们先使用requests爬取页面数据,因为简单,所以这里就不贴代码了。
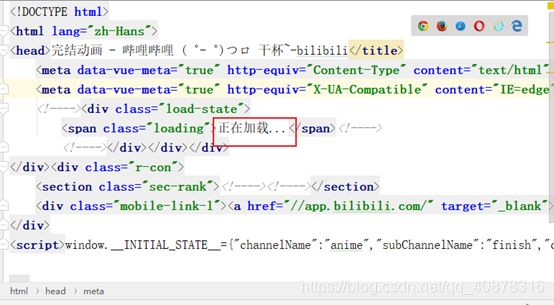
出乎意料的是,使用requests.get()方法虽然能够获取数据,但仔细观察就会发现,爬取的页面代码并非完整的代码。这是因为b站的数据是js动态加载的,而requests一般获取的数据是进入网站之后加载之前的页面(大概)。
所以这里我们就需要转换思路,使用selenium模块,通过脚本的方式打开网站再爬取。
步骤3:selenium模块爬取页面
使用selenium,用脚本打开火狐浏览器等页面加载后在拿页面代码
from selenium import webdriver
url='https://www.bilibili.com/v/anime/finish/#/'
# 启动火狐浏览器
browser=webdriver.Firefox()
# 浏览器窗口最大化
# browser.maximize_window()
# 输入网站
browser.get(url)
# 获取网站代码
data=browser.page_source
with open('baidu.html', 'w', encoding='utf8')as f:
f.write(data)
# 关闭浏览器
browser.close()结果:
步骤4:精炼代码
from selenium import webdriver
from lxml import etree
import time
url='https://www.bilibili.com/v/anime/finish/#/'
# 启动火狐浏览器
browser=webdriver.Firefox()
# 浏览器窗口最大化
# browser.maximize_window()
# 输入网站
browser.get(url)
# 获取网站代码
data=browser.page_source
html=etree.HTML(data)
# 先获取图片地址看看
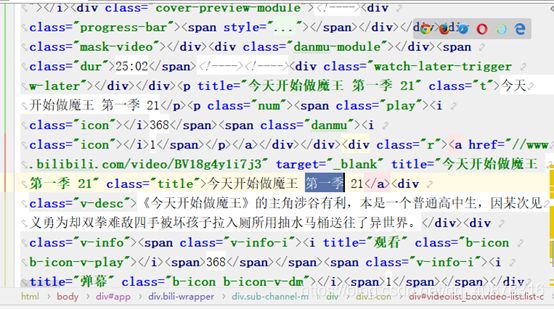
result=html.xpath('//*/div[@class="l-item"]/div[@class="l"]//div[@class="lazy-img"]/img/@src')
print(result)
# 关闭浏览器
browser.close()结果:

我们会发现,我们爬取的数据只有几条,经过与网站对应,我们发现爬取到的数据仅是我们进入页面看到的,而空着的是我们不下拉页面看不到的东西(这里我做了进入页面后下拉置低的操作,虽然后面的数据能爬取到,但中间的数据依旧为空)
说明b站的数据是动态加载用户看得到的地方,不是用户一进页面就立马加载数据。所以我们要爬取完整的网站数据,还必须规规矩矩的浏览完整个页面。
步骤5:让浏览器自动下拉滚动条
from selenium import webdriver
from lxml import etree
import time
url='https://www.bilibili.com/v/anime/finish/#/'
# 启动火狐浏览器
browser=webdriver.Firefox()
# 浏览器窗口最大化
browser.maximize_window()
# 输入网站
browser.get(url)
time.sleep(3)
# 获取页面高度
js = "return action=document.body.scrollHeight"
height = browser.execute_script(js)
i=0
while i<=height:
i+=100
# 将滚动条慢慢拉至页面底部(这里应该有更好的方法,用循环太墨迹)
browser.execute_script(f'window.scrollTo(0, {i})')
time.sleep(3)
# 获取网站代码
data=browser.page_source
html=etree.HTML(data)
# 先获取图片地址看看
result=html.xpath('//*/div[@class="l-item"]/div[@class="l"]//div[@class="lazy-img"]/img/@src')
print(result)
# 关闭浏览器
browser.close()
结果:

我们设置脚本让浏览器自己下拉滚动条,欺骗b站服务器将所有数据吐出来后再爬取页面,这样我们就可以获取完整的数据。
补充其他数据:
from selenium import webdriver
from lxml import etree
import time
url='https://www.bilibili.com/v/anime/finish/#/'
browser=webdriver.Firefox()
browser.maximize_window()
browser.get(url)
time.sleep(3)
js = "return action=document.body.scrollHeight"
height = browser.execute_script(js)
i=0
while i<=height:
i+=100
browser.execute_script(f'window.scrollTo(0, {i})')
time.sleep(3)
data=browser.page_source
html=etree.HTML(data)
result=html.xpath('//*/ul[@class="vd-list mod-2"]/li/div[@class="l-item"]')
for res in result:
image = res.xpath('div[@class="l"]//div[@class="lazy-img"]/img/@src')[0]
url=res.xpath('div[@class="l"]//a/@href')[0].replace('//','')
times=res.xpath('div[@class="l"]//span[@class="dur"]/text()')
title=res.xpath('div[@class="r"]/a/text()')
abstract = res.xpath('div[@class="r"]/div[@class="v-desc"]/text()')
num = res.xpath('div[@class="r"]/div[@class="v-info"]/span/span/text()')
print(f'标题:{title},简介:{abstract},封面:{image},地址:{url},时长:{times},播放量:{num[0]},弹幕数:{num[1]}')
browser.close()
结果:

步骤6:写入excel表格
from selenium import webdriver
from lxml import etree
import xlwt
import time
url='https://www.bilibili.com/v/anime/finish/#/'
# 启动火狐浏览器
browser=webdriver.Firefox()
# 浏览器窗口最大化
browser.maximize_window()
workbook=xlwt.Workbook()
sheet=workbook.add_sheet('完结番剧')
list=['标题','简介','封面','地址','时长','播放量','弹幕数']
for i in range(0,len(list)):
sheet.write(0,i,list[i])
browser.get(url)
time.sleep(3)
js = "return action=document.body.scrollHeight"
height = browser.execute_script(js)
i=0
while i<=height:
i+=100
browser.execute_script(f'window.scrollTo(0, {i})')
time.sleep(3)
data=browser.page_source
html=etree.HTML(data)
result=html.xpath('//*/ul[@class="vd-list mod-2"]/li/div[@class="l-item"]')
lists=[]
for res in result:
image = res.xpath('div[@class="l"]//div[@class="lazy-img"]/img/@src')[0]
url=res.xpath('div[@class="l"]//a/@href')[0].replace('//','')
times=res.xpath('div[@class="l"]//span[@class="dur"]/text()')[0]
title=res.xpath('div[@class="r"]/a/text()')[0]
abstract = res.xpath('div[@class="r"]/div[@class="v-desc"]/text()')[0]
num = res.xpath('div[@class="r"]/div[@class="v-info"]/span/span/text()')
list=[title,abstract,image,url,times,num[0],num[1]]
lists.append(list)
j=0
for dh in lists:
j += 1
for k in range(0,len(dh)):
sheet.write(j,k,dh[k])
workbook.save('b站.xls')
# 关闭浏览器
browser.close()
结果:

步骤7:重构
这里我不仅将代码整理了一下,还加了 @atexit.register 方法,避免爬取过程中出错直接退出程序而数据未保留的问题。这次重构版总共是爬取了802页的数据,耗时也比较长,另外我发现b站其他模块的视频列表url和完结动画列表url有类似的地方,也就是只要改下url,便可以爬取其他类型的视频。
from selenium import webdriver
from lxml import etree
import xlwt
import time
import atexit
lists=[]
# 启动火狐浏览器
browser = webdriver.Firefox()
# 无论爬取是否正常,最后都关闭火狐浏览器
@atexit.register
def closeWebSite():
print("正在关闭浏览器...")
browser.quit()
print("浏览器已关闭.")
# 将爬取的数据写入excel表格中
# 使用@atexit.register,避免程序出错时,数据没来得及保存,导致前面爬取到的全无
@atexit.register
def saveExcel():
workbook = xlwt.Workbook()
sheet = workbook.add_sheet('完结番剧')
titleList = ['标题', '简介', '封面', '地址', '时长', '播放量', '弹幕数']
num = 0
print(f'数据正在插入excel表中...')
for i in range(0, len(titleList)):
sheet.write(num, i, titleList[i])
for dh in lists:
num += 1
for k in range(0, len(dh)):
sheet.write(num, k, dh[k])
print(f'数据插入成功,本次插入{num}条数据')
workbook.save('b站demo.xls')
# 爬取页面
def openWebSite(url):
# 输入网站
browser.get(url)
# 设置停滞时间,一来是怕爬取速度太快数据没加载出来,二是防止脚本频繁操作给爬取对象的服务器造成压力
time.sleep(1)
# 获取页面高度
js = "return action=document.body.scrollHeight"
height = browser.execute_script(js)
i = 0
while i <= height:
i += 100
# 将滚动条慢慢拉至页面底部(这里应该有更好的方法,用循环太墨迹)
browser.execute_script(f'window.scrollTo(0, {i})')
time.sleep(1)
# 返回获取到的网站页面
return browser.page_source
# 获取总页数
def getPage(html):
html = etree.HTML(html)
result = html.xpath('//*/div[@class="pager pagination"]/ul[@class="pages"]/li[@class="page-item last"]/button/text()')[0]
return result
# 获取数据
def htmlxXath(html):
html = etree.HTML(html)
result = html.xpath('//*/ul[@class="vd-list mod-2"]/li/div[@class="l-item"]')
for res in result:
'''
如果没有空数据,即如果不会出现索引问题,我们就正常爬取,如果报错,那么我们就加判断条件限制.
这里不直接使用if限定res的值不为空
因为每一次循环都去判断会浪费时间,虽然极小,但积少成多,数量大时效率会低下.
'''
try:
image = res.xpath('div[@class="l"]//div[@class="lazy-img"]/img/@src')[0]
url = res.xpath('div[@class="l"]//a/@href')[0].replace('//', '')
times = res.xpath('div[@class="l"]//span[@class="dur"]/text()')[0]
title = res.xpath('div[@class="r"]/a/text()')[0]
abstract = res.xpath('div[@class="r"]/div[@class="v-desc"]/text()')[0]
num = res.xpath('div[@class="r"]/div[@class="v-info"]/span/span/text()')
except IndexError:
image = res.xpath('div[@class="l"]//div[@class="lazy-img"]/img/@src')[0]
url = res.xpath('div[@class="l"]//a/@href')[0].replace('//', '')
times = res.xpath('div[@class="l"]//span[@class="dur"]/text()')
title = res.xpath('div[@class="r"]/a/text()')[0]
abstract = res.xpath('div[@class="r"]/div[@class="v-desc"]/text()')
num = res.xpath('div[@class="r"]/div[@class="v-info"]/span/span/text()')
# 在66页有简介为空的视频导致IndexError: list index out of range错误,所以需要做一下判断
# 其他的判断同理
if len(abstract) == 0:
abstract = '无简介'
else:
abstract = abstract[0]
if len(times) == 0:
times = '未知'
else:
times = times[0]
finally:
list = [title, abstract, image, url, times, num[0], num[1]]
lists.append(list)
def cartoonSpider(url):
# 浏览器窗口最大化
browser.maximize_window()
# beginTime = time.time()
html=openWebSite(url)
maxPage=int(getPage(html))
print(f'一共有{maxPage}页')
print(f'正在爬取第 1 页内容...')
htmlxXath(html)
# 第一页要获取页数,所以单独写,然后从第二页开始
for i in range(2,maxPage+1):
print(f'正在爬取第 {i} 页内容...')
fullurl=f'{url}all/default/0/{i}/'
html = openWebSite(fullurl)
htmlxXath(html)
# endTime = time.time()
# print(endTime - beginTime)
# saveExcel()
# browser.close()
if __name__=="__main__":
url = 'https://www.bilibili.com/v/anime/finish/#/'
cartoonSpider(url)
爬取结果:

遇到问题
“selenium.common.exceptions.WebDriverException: Message: ‘geckodriver’ executable needs to be in PATH.”
这主要是因为我一开始没有给火狐浏览器安装插件,以前学的是用谷歌浏览器。下载安装插件并配置好path就行。具体可以参考这边文章:https://blog.csdn.net/qq471011042/article/details/79514908