node.js模块化详解
说到node.js的模块化,就不得不提CommonJs规范。在 CommonJS 的规范中,每个 JavaScript 文件就是一个独立的模块上下文(module context),在这个上下文中默认创建的属性都是私有的。也就是说,在一个文件定义的变量(还包括函数和类),都是私有的,对其他文件是不可见的。
Node 从 CommonJS 的一些创意中,创造出自己的模块化实现。由于Node 在服务端的流行,Node 的模块形式被(不正确地)称为 CommonJS。
Node.js模块可以分为两大类,一类是核心模块,另一类是文件模块。
核心模块
就是Node.js标准的API中提供的模块,如fs、http、net等,这些都是由Node.js官方提供的模块,编译成了二进制代码,可以直接通过require获取核心模块,例如require('fs'),核心模块拥有最高的加载优先级,如果有模块与核心模块命名冲突,Node.js总是会加载核心模块。
文件模块
是存储为单独的文件(或文件夹)的模块,可能是JavaScript代码、JSON或编译好的C/C++代码。在不显式指定文件模块扩展名的时候,Node.js会分别试图加上.js、.json、.node(编译好的C/C++代码)。
加载方式
按路径加载模块
如果require参数一"/"开头,那么就以绝对路径的方式查找模块名称,如果参数一"./"、"../"开头,那么则是以相对路径的方式来查找模块。
通过查找node_modules目录加载模块
如果require参数不以"/"、"./"、"../"开头,而该模块又不是核心模块,那么就要通过查找node_modules加载模块了。我们使用的npm获取的包通常就是以这种方式加载的。
加载缓存
Node.js模块不会被重复加载,这是因为Node.js通过文件名缓存所有加载过的文件模块,所以以后再访问到时就不会重新加载了。
注意:Node.js是根据实际文件名缓存的,而不是require()提供的参数缓存的,也就是说即使你分别通过require('express')和require('./node_modules/express')加载两次,也不会重复加载,因为尽管两次参数不同,解析到的文件却是同一个。
Node.js 中的模块在加载之后是以单例化运行,并且遵循值传递原则:如果是一个对象,就相当于这个对象的引用。
模块载入过程
加载文件模块的工作,主要由原生模块module来实现和完成,该原生模块在启动时已经被加载,进程直接调用到runMain静态方法。
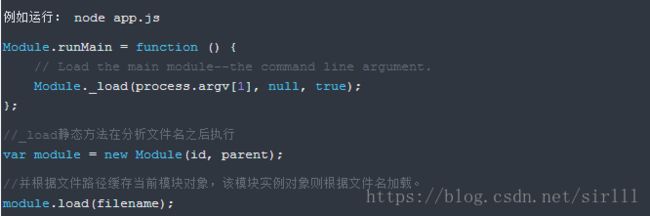
具体说一下上文提到了文件模块的三类模块,这三类文件模块以后缀来区分,Node.js会根据后缀名来决定加载方法,具体的加载方法在下文 require.extensions中会介绍。
.js通过fs模块同步读取js文件并编译执行。.node通过C/C++进行编写的Addon。通过dlopen方法进行加载。.json读取文件,调用JSON.parse解析加载。
接下来详细描述js后缀的编译过程。Node.js在编译js文件的过程中实际完成的步骤有对js文件内容进行头尾包装。以app.js为例,包装之后的app.js将会变成以下形式:
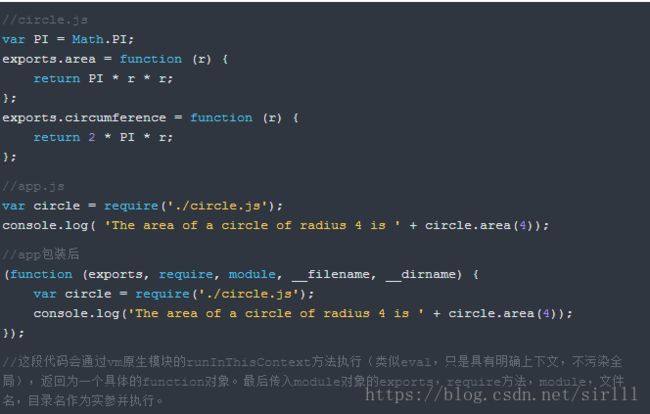
这就是为什么require并没有定义在app.js 文件中,但是这个方法却存在的原因。从Node.js的API文档中可以看到还有 __filename、 __dirname、 module、 exports几个没有定义但是却存在的变量。其中 __filename和 __dirname在查找文件路径的过程中分析得到后传入的。 module变量是这个模块对象自身, exports是在module的构造函数中初始化的一个空对象({},而不是null)。
在这个主文件中,可以通过require方法去引入其余的模块。而其实这个require方法实际调用的就是module._load方法。
load方法在载入、编译、缓存了module后,返回module的exports对象。这就是circle.js文件中只有定义在exports对象上的方法才能被外部调用的原因。
以上所描述的模块载入机制均定义在lib/module.js中。
require 函数
require 引入的对象主要是函数。当 Node 调用 require() 函数,并且传递一个文件路径给它的时候,Node 会经历如下几个步骤:
Resolving:找到文件的绝对路径;
Loading:判断文件内容类型;
Wrapping:打包,给这个文件赋予一个私有作用范围。这是使 require 和 module 模块在本地引用的一种方法;
Evaluating:VM 对加载的代码进行处理的地方;
Caching:当再次需要用这个文件的时候,不需要重复一遍上面步骤。
require.extensions 来查看对三种文件的支持情况:
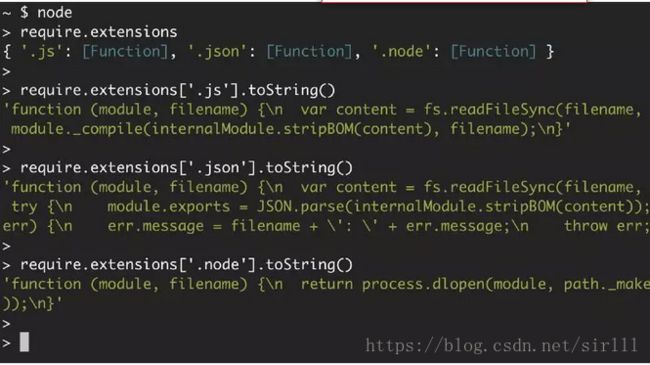
可以清晰地看到 Node 对每种扩展名所使用的函数及其操作:对 .js 文件使用 module._compile;对 .json 文件使用 JSON.parse;对 .node 文件使用 process.dlopen。
文件查找策略
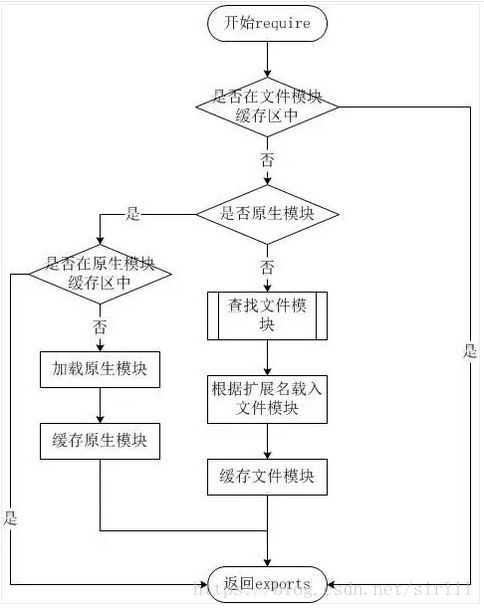
从文件模块缓存中加载
尽管原生模块与文件模块的优先级不同,但是优先级最高的是从文件模块的缓存中加载已经存在的模块。
从原生模块加载
原生模块的优先级仅次于文件模块缓存的优先级。require方法在解析文件名之后,优先检查模块是否在原生模块列表中。以http模块为例,尽管在目录下存在一个 http、 http.js、 http.node、 http.json文件, require(“http”)都不会从这些文件中加载,而是从原生模块中加载。
原生模块也有一个缓存区,同样也是优先从缓存区加载。如果缓存区没有被加载过,则调用原生模块的加载方式进行加载和执行。
从文件加载
当文件模块缓存中不存在,而且不是原生模块的时候,Node.js会解析require方法传入的参数,并从文件系统中加载实际的文件,加载过程中的包装和编译细节在前面说过是调用load方法。
当 Node 遇到 require(X) 时,按下面的顺序处理。
1、如果 X 是内置模块(比如 require('http'))
a. 返回该模块。
b. 不再继续执行。
2、如果 X 以 "./" 或者 "/" 或者 "../" 开头
a. 根据 X 所在的父模块,确定 X 的绝对路径。
b. 将 X 当成文件,依次查找下面文件,只要其中有一个存在,就返回该文件,不再继续执行。
X
X.js
X.json
X.node
c. 将 X 当成目录,依次查找下面文件,只要其中有一个存在,就返回该文件,不再继续执行。
X/package.json(main字段)
X/index.js
X/index.json
X/index.node
3、如果 X 不带路径
a. 根据 X 所在的父模块,确定 X 可能的安装目录。
b. 依次在每个目录中,将 X 当成文件名或目录名加载。
4、抛出 "not found"
模块循环依赖
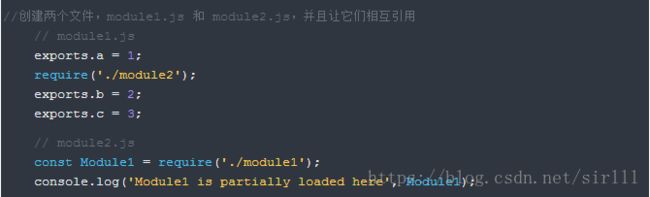
在 module1 完全加载之前需要先加载 module2,而 module2 的加载又需要 module1。这种状态下,我们从 exports 对象中能得到的就是在发生循环依赖之前的这部分。上面代码中,只有 a 属性被引入,因为 b 和 c 都需要在引入 module2 之后才能加载进来。
Node 使这个问题简单化,在一个模块加载期间开始创建 exports 对象。如果它需要引入其他模块,并且有循环依赖,那么只能部分引入,也就是只能引入发生循环依赖之前所定义的这部分。