训练机器学习模型时如何评估数据质量
A Deep Dive Into Benchmarks, Consensus and Review
训练数据的质量对于模型表现至关重要。我们用一致性和标注数据准确率来评估质量。业内评估训练数据质量的基本方法是benchmark(aka gold standard),一致性和检查。作为AI数据科学家,工作中一个重要任务就是如何有效组合应用这些数据质量保证方法。
在这边文章中,你会学到:
*数据质量,一致性和准确率的定义以及它们的重要性
*业内用来量化质量的标注方法
*自动化质量保证流程的最前沿工具
一致性 vs. 准确率
数据质量决定于一致性和准确率。不但包括这个数据标注的多少准确,还包括一段时间内准确的次数有多少。下面介绍业内用于评估一致性和准确率的基本方法。
一致性指的是一个标注员的标注和其他人标注一样。一致性通过确保标注员标注同样的准确或者同样的错误来防止数据随机噪音。一致性是通过共识算法来衡量的。 如果没有自动化的最先进的AI工具,此过程将是手动的,耗时的并且有安全责任。 由于标签可能始终正确或错误,因此仅靠高一致性不足以完全说明质量。
准确性衡量的是标签与“ground truth”的接近程度。 Ground Truth数据是由知识专家或数据科学家标记用来测试标注员准确性的训练数据的子集。 准确性是通过Benchmark衡量的。 Benchmark使数据科学家能够监视其数据的整体质量,然后通过深入了解标注员工作的准确性来调查和解决可能引起质量方面的任何潜在下降的原因。
复查是确保准确性的另一种方法。 标注完成后,有经验专家会检查标签的准确性。 复查通常通过目视抽查某些标注来进行,但是某些项目会审查所有标签。 复查通常用于识别标注过程中的低准确性和不一致,而Benchmark通常用于感知标注员表现
基准往往是最便宜的质量保证选项,因为它涉及的重叠工作量最少。 但是,它仅捕获训练数据集的子集。 共识和复查的花费多少取决于共识设置和审查比例(两者都可以设置为数据集的0-100%,并且同时分配给多个标注员)。
Quality Workflows
理想情况下,质量保证是一个自动化过程,可在您的训练数据开发和改进过程中持续不断地运行。 借助Labelbox共识和benchmark测试功能,您可以自动化一致性和准确性测试。 通过测试,您可以自定义要测试的数据的百分比以及用于标注测试数据的标注员数量。 对于许多数据科学家而言,发现一个项目的质量保证测试的最佳组合通常是一个新兴的过程,通过实验会越来越清晰。
Benchmarks
Benchmarks 工作流
- 给一个标注好的标签添加星星标志来添加新的benchmark
- 系统自动把标注为benchmark的任务分给标注员
- 通过标注员(3a)或benchmark(3b)跟踪项目的整体质量,并深入研究任何偏差产生原因
Benchmarks举例
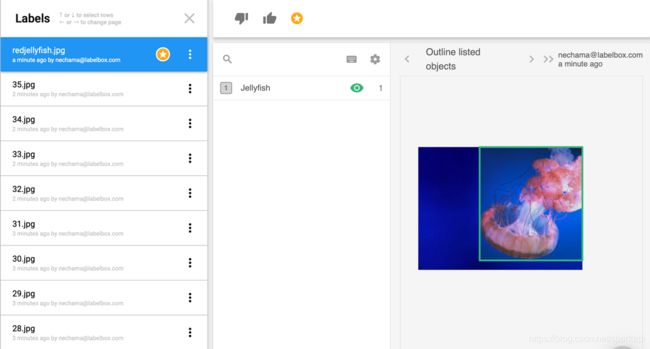
下面以一个水母项目举例说明上面概述的benchmark测试工作流程。 该项目使用矩形边界框。一旦启动了项目并标记了Groundtruth数据,就可以用基准星标记标签。(问题:谁有权限标注benchmark数据?标注多少benchmark数据? benchmark和groundtruth数据的区别?)
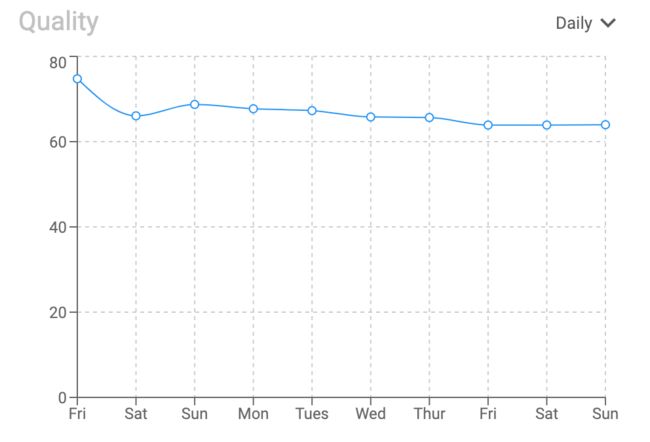
由于随机分配给标注员benchmark数据,因此您可以使用整体质量图监控项目质量。
要解决质量下降的问题,可以按标注员或benchmark作为维度来研究。
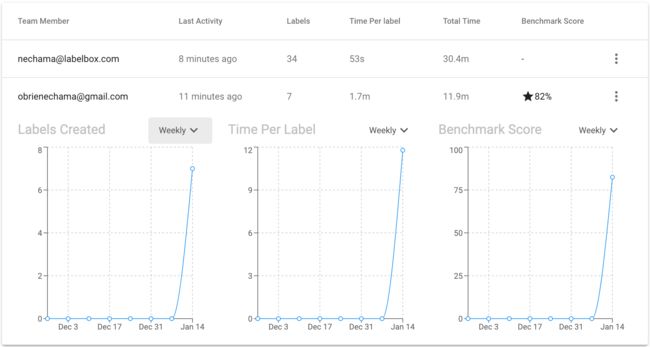
Systemic poor labeler performance is often indicative of poor instructions, while poor performance on certain pieces of data is often indicative of edge cases. Data scientists use these values to help them improve labeler on-boarding and education processes.
普遍上的标注不佳通常是因为培训不到位,而某些数据的性能不佳通常是因为某些特殊例子没有完全理解或者考虑到。 数据科学家利用这些信息来帮助他们改善标注员的入职和培训流程
通过点击benchmark准确率65%的图片,您可以看到拥挤的水母图像并将其与基准进行比较。(这个65%是怎么得出的?)
尽管它们非常相似,但标签倾向于在每个框中包含多少触手上存在分歧。 在这里,您可以编辑,删除或重新排列标签。
数据标记是一个迭代的过程。 当我们对项目变得更加了解时,我们认为应该标记的内容的想法通常会演变。 例如,也许在一开始我们认为应该标记整个水母。 但是,很长的细密的触角触手可能会使模型感到困惑,而不是改善其性能。 该模型可能会开始识别银色的线,尤其是在照片边缘附近,认为那很可能被遮挡的水母,实际上可能只是水下植物碎片或海葵的卷须。 因为这不是一个公认的问题,在数值和视觉上监视和迭代训练数据的能力经常被低估。
一致性
一致性衡量多个标注员标注的一致性(人或者机器)一致性分数是通过标注一致的标签除以标签总数得到的
一致性工作流程
启用一致性并自定义共识参数
(自动)随机标签以随机间隔分布在各个标签上
跟踪整体一致性并通过查看各个标签商和标签一致性分数来调查质量下降情况
共识示例
要配置共识,您可以自定义训练数据的百分比和要测试的标签数量
共识工作流程
1.启用共识并自定义共识参数
2.系统自动随机把任务分配给不同标注员
3.跟踪整体一致性并通过查看单独标注员和标签共识性分数来调查质量下降情况
共识示例
要配置共识,您可以自定义训练数据的百分比和要测试的标签数量。
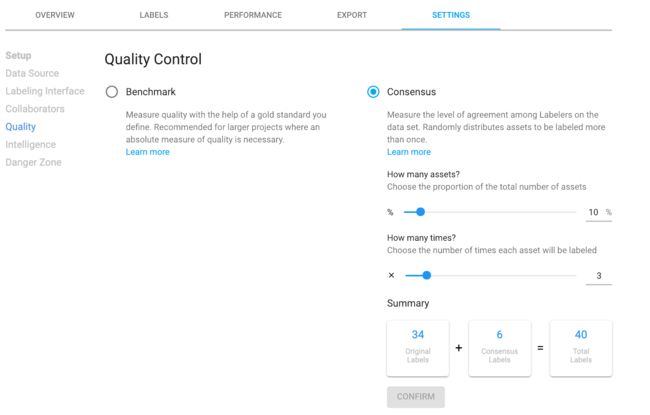
使用共识直方图监控总体一致性
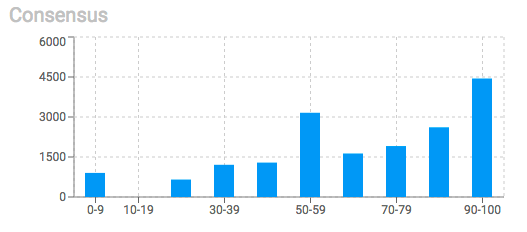
按项目(asset)细分共识得分。 在这里您可以比较特定图像的标签。 这是研发的协作部分,使AI团队可以在项目上进行创新。 意见分歧可能是从其他角度思考问题的机会,而这反过来又可能引发新的解决方案。
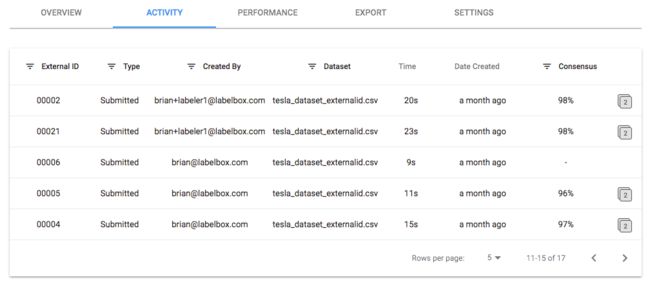
通常情况下,数据标记有敏捷的进展。 通常,生产中最成功的AI模型的标注任务会随着时间的推移而发展,以更好地适应其用例。 这意味着,随着视觉工程师对问题的更加熟悉,他们可以分解问题并逐步解决问题,并通过模型为其他模型整理图像,以提高效率。 换句话说,有效的建模通过创建原子任务生产线来发挥机器的重复性和精度优势。
Typically, there is an agile progression to data labeling. Often the most successful AI models in production have had labeling tasks that evolved over time to better fit their use cases. Meaning, as visual engineers get more familiar with the problem they are able break it down and solve it in steps with models curating images for other models down the line to drive efficiencies. In other words, effective modeling plays to the repetition and precision strengths of machines by creating a production line of atomic tasks.
复查
通过人与机器之间紧密的反馈循环控制数据,使团队能够构建出色的ML应用程序。 可视化数据至关重要,这不仅对于解决质量问题很重要,而且对于深入了解机器学习问题和为机器学习问题提供完善的解决方案也至关重要。
审查工作流程
审阅是手动而不是自动化的过程。 这是使人陷入困境的一部分。
选择要查看的标签
查看,修改或重新排队标签
复查示例
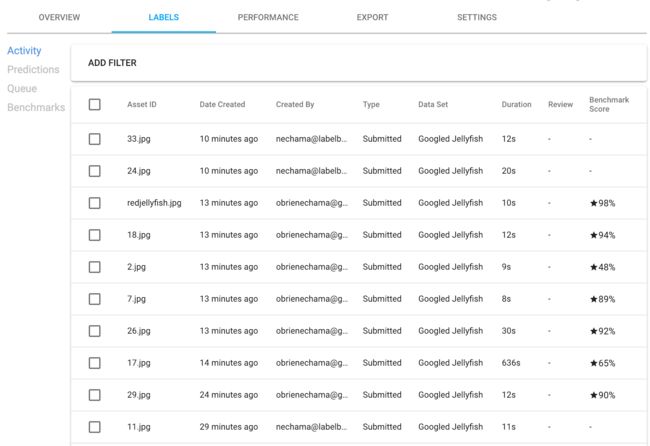
过滤选项可帮助标注经理确定要检查的标签的优先级。 如下图所示,可用的过滤器包括标签,共识分数,包含的标签等
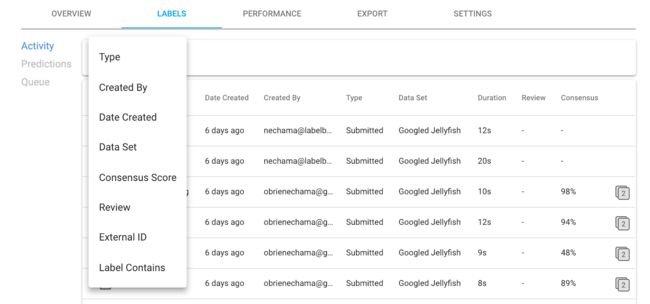
复查的人通常是表现最好的标注人员或内部知识专家。 要查看标签,有拇指向上和向下的图标。 审阅者还可以选择在现场修改或更正标签。 此外,单击三个垂直点可让您删除标签并重新加入标签,在适用时查看基准,并复制链接以发送给其他协作者.
Conclusion
Creating training data is often one of the most expensive components of building a machine learning application. Properly monitoring training data quality increases the chance of having a performant model the first time around. And, getting labels right the first time (first pass quality) is far cheaper than the cost of discovering and redoing work to fix the problem. With world class tooling at your fingertips, you can ensure your labeling maintains the level of quality you need to get the modeling results you want.
With Quality Assurance processes data scientists can:
- Monitor overall consistency and accuracy of training data
- Quickly troubleshoot quality errors
- Improve labeler instructions, on-boarding, and training
- Better understand the specifics to their project on what and how to label