K8s 本地储存
1. 基本概念
kubernetes从1.10版本开始支持local volume(本地卷)可以充分利用本地快速SSD,从而获取比remote volume(如cephfs、RBD)更好的性能.
下面两种类型应用适合使用local volume。
数据缓存,应用可以就近访问数据,快速处理。
分布式存储系统,如分布式数据库Cassandra ,分布式文件系统ceph/gluster
2.创建StorageClass
手动创建local-pv 需要创建storageclass, pv. 如果你的资源申请pv使用使用的persistvolumetemplate, pvc 会自动创建.
首先需要有一个名为local-volume的sc。
| kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: local-volume provisioner: kubernetes.io/no-provisioner volumeBindingMode: WaitForFirstConsumer |
sc的provisioner是 kubernetes.io/no-provisioner
volumeBindingMode必须是WaitForFirstConsumer(延迟绑定策略),否则就无法绑定localPV。
2.1 PVC绑定策略

PersistentVolume Controller会遍历现有PV和可以动态创建的StorageClass,找到满足条件(访问权限、容量等)进行绑定,Scheduler基于资源要求找到匹配的节点,以过滤和打分的方式选出“匹配度”最高的Node。流程如下图所示:
PVC绑定在Pod调度之前,PersistentVolume Controller不会等待Scheduler调度结果,在Statefulset中PVC先于Pod创建,所以PVC/PV绑定可能完成在Pod调度之前。
Scheduler不感知卷的“位置”,仅考虑存储容量、访问权限、存储类型、还有第三方CloudProvider上的限制(譬如在AWS、GCE、Aure上使用Disk数量的限制)
当应用对卷的“位置”有要求,比如使用localPV,可能出现Pod被Scheduler调度到NodeB,但PersistentVolume Controller绑定了在NodeD上的本地卷,以致PV和Pod不在一个节点,如下图所示:
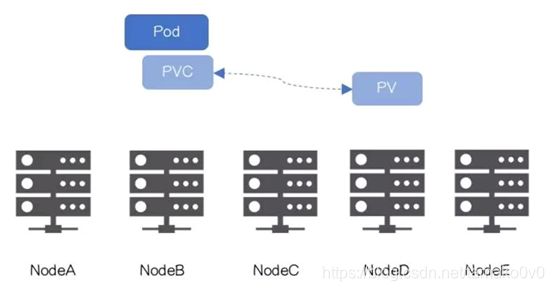
2.2 延时绑定策略
为了解决此问题,k8s调度器采用一下策略:
- 预分配使用本地卷的PV
- 通过NodeAffinity方式标记PV位置
- 创建StorageClass,通过StorageClass间接标记PVC的延时绑定
- 标记该PVC需要延后到Node选择出来之后再绑定
依照原有流程创建PVC和Pod,但对于需要延时绑定的PVC,PersistentVolume Controller不再参与。通过PVC.StorageClass,PersistentVolume Controller得知PVC是否需要延时绑定。
PV不立即绑定PVC,而是直到有Pod需要用PVC的时候才绑定。调度器会在调度时综合考虑选择合适的local PV,这样就不会导致跟Pod资源设置,selectors,affinity and anti-affinity策略等产生冲突。如果PVC先跟local PV绑定了,由于local PV是跟node绑定的,这样selectors,affinity等等就基本没用了,所以更好的做法是先根据调度策略选择node,然后再绑定local PV。
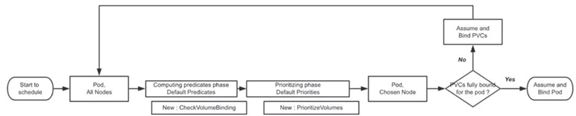
3.创建localPV
创建以下yaml文件
persistentVolumeReclaimPolicy: Retain表示pv删除是不删除磁盘上存储的数据,如果设置为Delete表示当pv删除时清理磁盘上数据
其中nodeAffinity表示节点亲和性,即localPV磁盘所在机器
path: /mnt/test表示挂载目录,默认格式为filesystem
| apiVersion: v1 kind: PersistentVolume metadata: name: example-local-pv spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: local-volume local: path: /mnt/test nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - 192.168.198.138 |
4.挂载目录
这里使用实际存储是192.168.198.138 上的/data/local/vol1 目录.
所以要手动建立这些目录给pv挂载使用,可以使用下面的方式使用挂载的方式挂载到目录.
| #!/bin/bash # Usage: sudo loopm ount file size m ount-point touch $1 truncate -s $2 $1 mke2fs -t ext4 -F $1 1> /dev/null 2> /dev/null if [[ ! -d $3 ]]; then echo $3 " not exist, creating..." mkdir $3 fi mount $1 $3 df -h |grep $3 |
lpfs.sh /data0/k8spv/data0 5G /mnt/test
5.绑定pv,使用pvc
| apiVersion: v1 kind: PersistentVolumeClaim metadata: name: myclaim spec: accessModes: - ReadWriteOnce resources: requests: storage: 5Gi storageClassName: local-volume --- kind: Pod apiVersion: v1 metadata: name: mypod spec: containers: - name: myfrontend image: nginx:least volumeMounts: - mountPath: "/usr/share/nginx/html" name: mypd volumes: - name: mypd persistentVolumeClaim: claimName: myclaim |
6.如何在生产环境中使用localPV
6.1 磁盘挂载
volumeMode可以是FileSystem(Default)和Block。
一般使用节点上local volume的初始化需要完成如下操作(local disk需要pre-partitioned, formatted, and mounted. 共享存储对应的Directories也需要pre-created)。在生产环境中,一般使用独立的磁盘作为应用的挂载目录,有利于提升性能。
执行如下命令查看磁盘分区
| fdisk /dev/sda |
在提示输出命令时输入p查看分区,执行结果如下:

Blocks表示磁盘大小。
使用local volume时,磁盘格式仅支持xfs和ext4,不支持其他文件系统,做分区时需要注意。使用如下命令查看文件系统格式
| parted –l |

6.2 创建pvc
与上面案例类似,我们可以创建本地卷为容器提供存储服务
| kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: local-storage provisioner: kubernetes.io/no-provisioner volumeBindingMode: WaitForFirstConsumer --- kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: local-storage1 provisioner: kubernetes.io/no-provisioner volumeBindingMode: WaitForFirstConsumer --- apiVersion: v1 kind: PersistentVolume metadata: name: local-pv-sda1 spec: capacity: storage: 6Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: local-storage1 local: path: /dev/sda5 nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - 192.168.198.139 --- apiVersion: v1 kind: PersistentVolume metadata: name: local-pv-sda spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: local-storage local: path: /dev/sda5 nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - 192.168.198.139 --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: local-pvc-sda spec: accessModes: - ReadWriteOnce storageClassName: local-storage resources: requests: storage: 5Gi --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: local-pvc-sda1 spec: accessModes: - ReadWriteOnce storageClassName: local-storage1 resources: requests: storage: 5Gi |
通过yaml文件可以看到,我创建了两套pv、pvc和sc,但是pv绑定的磁盘分区都是同一个,一般生产环境中不推荐此种方式,此处为了演示一个deployment可以绑定多个磁盘。
如果一个deployment绑定的两个pvc不是同一个node上的磁盘,会导致调度失败。
6.3 创建hadoop节点绑定多个localpv
| --- apiVersion: v1 kind: Service metadata: name: bd-master-via labels: app: bd-master spec: type: NodePort ports: - port: 50070 name: hdfsweb nodePort: 30070 - port: 9000 name: hdfs nodePort: 30000 - port: 50010 name: hdfs2 nodePort: 30010 - port: 50020 name: hdfs3 nodePort: 30020 - port: 8088 name: yarn nodePort: 32088 selector: app: bd-master --- apiVersion: v1 kind: Service metadata: name: bd-master labels: app: bd-master spec: clusterIP: None ports: - port: 9000 name: hdfs - port: 50010 name: hdfs2 - port: 50020 name: hdfs3 - port: 50070 name: hdfsweb - port: 50075 name: hdfs5 - port: 50090 name: hdfs6 - port: 31010 name: hdfs7 - port: 8020 name: hdfs8 - port: 10020 name: mapred2 - port: 19888 name: jobhistory - port: 8088 name: yarn - port: 8030 name: yarn1 - port: 8031 name: yarn2 - port: 8032 name: yarn3 - port: 8033 name: yarn4 - port: 8040 name: yarn5 - port: 8042 name: yarn6 selector: app: bd-master --- apiVersion: v1 kind: ConfigMap metadata: name: hdp-cm data: master: "bd-master" --- apiVersion: apps/v1 kind: Deployment metadata: name: bd-master spec: selector: matchLabels: app: bd-master replicas: 1 template: metadata: labels: app: bd-master spec: hostname: bd-master containers: - name: bd-master image: bdhadoophive64:0.0.3 securityContext: privileged: true ports: - containerPort: 9000 name: hdfs - containerPort: 50010 name: hdfs2 - containerPort: 50020 name: hdfs3 - containerPort: 50070 name: hdfsweb - containerPort: 50075 name: hdfs5 - containerPort: 50090 name: hdfs6 - containerPort: 31010 name: hdfs7 - containerPort: 8020 name: hdfs8 - containerPort: 10020 name: mapred2 - containerPort: 19888 name: jobhistory - containerPort: 8088 name: yarn - containerPort: 8030 name: yarn1 - containerPort: 8031 name: yarn2 - containerPort: 8032 name: yarn3 - containerPort: 8033 name: yarn4 - containerPort: 8040 name: yarn5 - containerPort: 8042 name: yarn6 env: - name: MASTER valueFrom: configMapKeyRef: name: hdp-cm key: master volumeMounts: - name: logs mountPath: /hadoop/logs - name: data1 mountPath: /hadoop/data1 - name: data2 mountPath: /hadoop/data2 - name: data3 mountPath: /hadoop/data3 - name: data4 mountPath: /hadoop/data4 - name: data5 mountPath: /hadoop/data5 #- name: data6 # mountPath: /hadoop/data6 #- name: data7 # mountPath: /hadoop/data7 #- name: data8 # mountPath: /hadoop/data8 #- name: data9 # mountPath: /hadoop/data9 #- name: data10 # mountPath: /hadoop/data10 - name: namenode mountPath: /hadoop/namenode - name: opendir mountPath: /root/opendir - mountPath: /usr/local/hadoop/etc/hadoop/ name: config volumes: - name: logs hostPath: path: /data1/bd-master/logs - name: data1 persistentVolumeClaim: claimName: local-pvc-sda - name: data2 persistentVolumeClaim: claimName: local-pvc-sda1 - name: data3 hostPath: path: /data3/bd-master/datanode - name: data4 hostPath: path: /data4/bd-master/datanode - name: data5 hostPath: path: /data5/bd-master/datanode #- name: data6 # hostPath: # path: /data6/bd-master/datanode #- name: data7 # hostPath: # path: /data7/bd-master/datanode #- name: data8 # hostPath: # path: /data8/bd-master/datanode #- name: data9 # hostPath: # path: /data9/bd-master/datanode #- name: data10 # hostPath: # path: /data10/bd-master/datanode - name: namenode hostPath: path: /data1/bd-master/namenode - name: opendir hostPath: path: /usr/local/opendir - hostPath: path: /home/hadoop/ name: config |
执行如下命令创建hadoopmaster节点
| Kubectl create –f bd-master.yaml |
查看节点运行状态
7. localPV的局限
7.1 无法动态创建PV
Local PV 的本地持久存储允许直接使用节点上的一块磁盘、一个分区或者一个目录作为持久卷的存储后端,但暂时还不提供动态配置支持,必须先把PV 创建好。
PV需要直接挂载本地磁盘或者分区,针对不同型号/不同环境的服务器分区与磁盘io性能并不一致,需要手动配置。
7.2 稳定性受Node本身影响
由于localPV和磁盘强绑定关系以及nodeAffinity影响,导致如果pod所在物理机出现问题或者磁盘出现问题,会直接导致服务不可用,且无法重新调度服务。
目前解决方案:
- Node不可用后,等待阈值超时,确定Node无法恢复
- 确认Node不可恢复,删除PVC,通过解除PVC和PV绑定的方式,解除Pod和Node的绑定
- 使用动态卷快照/克隆卷重新创建PV绑定PVC,或者使用主从模式,重新创建PV,PVC进行数据同步
- scheduler将Pod调度到其他可用Node,PVC重新绑定到可用Node的PV
7.3 资源利用率降低
一旦本地存储使用完,即使CPU、Memory剩余再多,该节点也无法提供服务。
目前解决方案:
需要做好本地存储规划,譬如每个节点Volume的数量、容量等,使用存储时需要把磁盘规划好,在一个大规模运行的环境,存在落地难度。
8.localPV与hostPath比较
相比 hostPath 卷,local 卷可以以持久和可移植的方式使用,而无需手动将 Pod 调度到节点,因为系统通过查看 PersistentVolume 所属节点的亲和性配置,就能了解卷的节点约束.
Both use local disks available on a machine. But! Imagine you have a cluster of three machines and have a Deployment with a replica of 1. If your pod is scheduled on node A, writes to a host path, then the pod is destroyed. At this point the scheduler will need to create a new pod, and this pod might be scheduled to node C which doesn't have the data.
Local volumes fix this by ensuring a pod is scheduled to the machine where the data exists.
两者都使用计算机上可用的本地磁盘。但是!假设你有一个由三台机器组成的集群,并且有一个副本为1的Deployment。如果你的pod被调度在到节点A上,使用host path,然后pod被销毁。这时调度器会创建一个新的pod,这个pod可能被调度到没有数据的节点C。
localPV通过确保将pod调度到数据所在的计算机来解决此问题。
|
|
hostPath |
localPV |
| 支持类型 |
Directory、File、Socket、CharDevice、BlockDevice |
Filesystem、BlockDevice |
| 调度策略 |
不提供node亲和性支持,可以通过pod配置亲和性 |
根据PV节点亲和性调度 |
| 储存管理 |
PV、PVC和StorageClass完整实现 |
PV、PVC和StorageClass,对sc只支持延时绑定 |
9.未来功能
- 本地块设备直接作为卷源,使用时具有分区和fs格式(当前需要预分区格式化和挂载)
- 动态配置共享本地持久存储
- LocalPV健康监测,污染和耐受性
- InlinePV使用专用本地磁盘作为临时存储
项目github地址
https://github.com/kubernetes-sigs/sig-storage-local-static-provisioner#future-features