CS231n学习笔记--15. Efficient Methods and Hardware for Deep Learning
Agenda

Hardware 101: the Family

Hardware 101: Number Representation

Hardware 101: Number Representation

1. Algorithms for Efficient Inference
1.1 Pruning Neural Networks


Iteratively Retrain to Recover Accuracy

Pruning RNN and LSTM

pruning之后准确率有所提升:

Pruning Changes Weight Distribution

1.2 Weight Sharing
Trained Quantization


How Many Bits do We Need?

Pruning + Trained Quantization Work Together
Huffman Coding

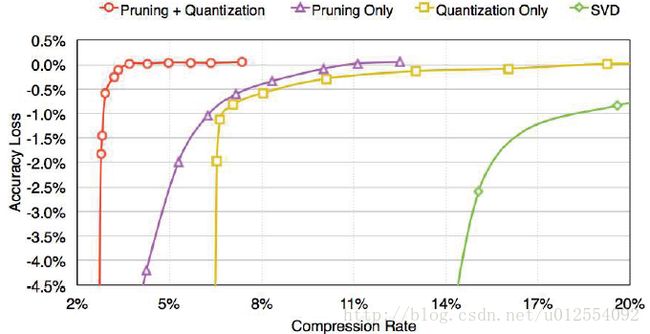
Summary of Deep Compression

Results: Compression Ratio
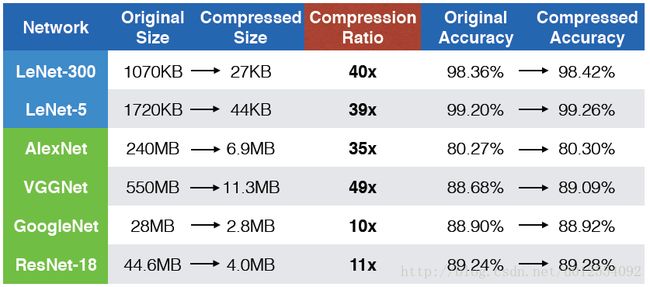
SqueezeNet

Compressing SqueezeNet

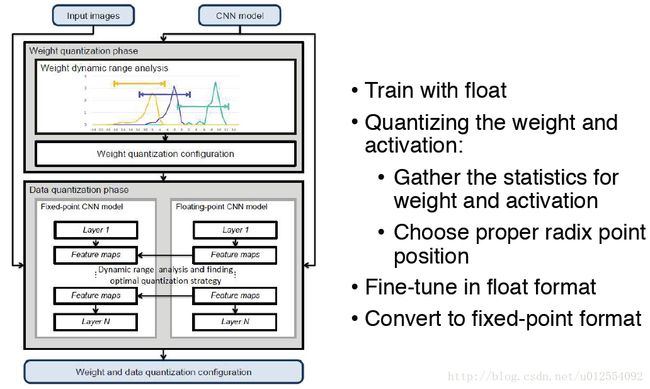
1.3 Quantization
Quantizing the Weight and Activation

1.4 Low Rank Approximation
Low Rank Approximation for Conv:类似Inception Module

Low Rank Approximation for FC :矩阵分解

1.5 Binary / Ternary Net
Trained Ternary(三元) Quantization
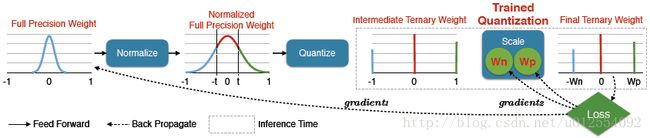
Weight Evolution during Training

Error Rate on ImageNet

1.6 Winograd Transformation
3x3 DIRECT Convolutions

Direct convolution: we need 9xCx4 = 36xC FMAs for 4 outputs
3x3 WINOGRAD Convolutions:
Transform Data to Reduce Math Intensity

Direct convolution: we need 9xCx4 = 36xC FMAs for 4 outputs
Winograd convolution: we need 16xC FMAs for 4 outputs: 2.25x fewer FMAs
2. Hardware for Efficient Inference
Hardware for Efficient Inference:
a common goal: minimize memory access

Google TPU


Roofline Model: Identify Performance Bottleneck

Log Rooflines for CPU, GPU, TPU

EIE: the First DNN Accelerator for Sparse, Compressed Model:
不保存、计算0值
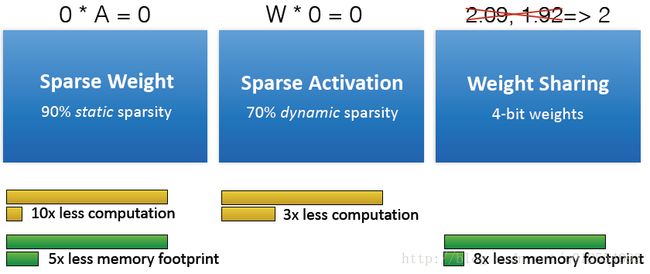

EIE Architecture

Micro Architecture for each PE

Comparison: Throughput

Comparison: Energy Efficiency

3. Algorithms for Efficient Training
3.1 Parallelization
Data Parallel – Run multiple inputs in parallel

Parameter Update
参数共享更新

Model-Parallel Convolution – by output region (x,y)

Model Parallel Fully-Connected Layer (M x V)


Summary of Parallelism

3.2 Mixed Precision with FP16 and FP32
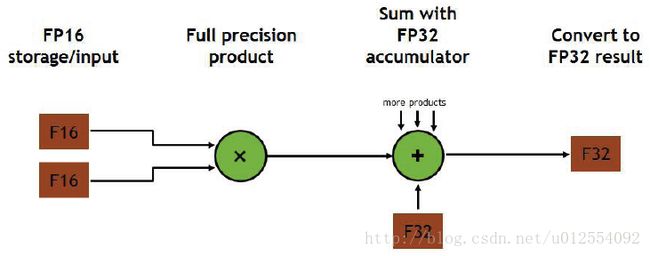
Mixed Precision Training

结果对比:

3.3 Model Distillation
student model has much smaller model size

Softened outputs reveal the dark knowledge

Softened outputs reveal the dark knowledge

3.4 DSD: Dense-Sparse-Dense Training

DSD produces same model architecture but can find better optimization solution, arrives at better local minima, and achieves higher prediction accuracy across a wide range of deep neural networks on CNNs / RNNs / LSTMs.
DSD: Intuition

DSD is General Purpose: Vision, Speech, Natural Language

DSD on Caption Generation

4. Hardware for Efficient Training
GPU / TPU

Google Cloud TPU

Future

Outlook: the Focus for Computation
