ADMM优化框架
交替方向乘子法(Alternating Direction Method of Multipliers,ADMM)是一种求解优化问题的计算框架, 适用于求解分布式凸优化问题,特别是统计学习问题。 ADMM 通过分解协调(Decomposition-Coordination)过程,将大的全局问题分解为多个较小、较容易求解的局部子问题,并通过协调子问题的解而得到大的全局问题的解。
ADMM 最早分别由 Glowinski & Marrocco 及 Gabay & Mercier 于 1975 年和 1976 年提出,并被 Boyd 等人于 2011 年重新综述并证明其适用于大规模分布式优化问题。由于 ADMM 的提出早于大规模分布式计算系统和大规模优化问题的出现,所以在 2011 年以前,这种方法并不广为人知。
ADMM 计算框架(也称作Split Bregmen)
一般问题
若优化问题可表示为
m i n f ( x ) + g ( z ) s . t . A x + B z = c ( 1 ) minf(x)+g(z) s.t.Ax+Bz=c\qquad (1) minf(x)+g(z)s.t.Ax+Bz=c(1)
其中 x ∈ R s , z ∈ R n , A ∈ R p × s , B ∈ R p × n , c ∈ R p , f : R s → R x∈R^s,z∈R^n,A∈R^{p×s},B∈R^{p×n},c∈R^p,f:R^s→R x∈Rs,z∈Rn,A∈Rp×s,B∈Rp×n,c∈Rp,f:Rs→R。x与 z 是优化变量; f ( x ) + g ( z ) f(x)+g(z) f(x)+g(z)是待最小化的目标函数(Objective Function),它由与变量 x 相关的
f ( x ) f(x) f(x)和与变量 x 相关的 g(z)这两部分构成,这种结构可以很容易地处理统计学习问题优化目标中的正则化项; A x + B z = c Ax+Bz=c Ax+Bz=c 是 p 个等式约束条件(Equality Constraints)的合写。其增广拉格朗日函数(Augmented Lagrangian)为
L ρ ( x , z , y ) = f ( x ) + g ( z ) + y T ( A x + B z − c ) + ( ρ / 2 ) ∥ A x + B z − c ∥ 2 2 Lρ(x,z,y)=f(x)+g(z)+y^T(Ax+Bz−c)+(ρ/2)∥Ax+Bz−c∥^2_2 Lρ(x,z,y)=f(x)+g(z)+yT(Ax+Bz−c)+(ρ/2)∥Ax+Bz−c∥22
其中 y 是对偶变量(或称为拉格朗日乘子), ρ > 0 ρ>0 ρ>0 是惩罚参数。 L ρ Lρ Lρ 名称中的“增广”是指其中加入了二次惩罚项 ( ρ / 2 ) ∥ A x + B z − c ∥ 2 2 (ρ/2)∥Ax+Bz−c∥^2_2 (ρ/2)∥Ax+Bz−c∥22。
则该优化问题的 ADMM 迭代求解方法为
x k + 1 : = a r g m i n x L ρ ( x , z k , y k ) x^{k+1}:=argmin_xLρ(x,z^k,y^k) xk+1:=argminxLρ(x,zk,yk) z k + 1 : = a r g m i n z L ρ ( x k + 1 , z , y k ) z^{k+1}:=argmin_zLρ(x^{k+1},z,y^k) zk+1:=argminzLρ(xk+1,z,yk) y k + 1 : = y k + ρ ( A x k + 1 + B z k + 1 − c ) y^{k+1}:=y^k+ρ(Ax^{k+1}+Bz^{k+1}−c) yk+1:=yk+ρ(Axk+1+Bzk+1−c)
令 u = ( 1 / ρ ) y u=(1/ρ)y u=(1/ρ)y,并对 A x + B z − c Ax+Bz−c Ax+Bz−c配方,可得表示上更简洁的缩放形式(Scaled Form)
x k + 1 : = a r g m i n x ( f ( x ) + ( ρ / 2 ) ∥ A x + B z k − c + u k ∥ 2 2 ) x^{k+1}:=argmin_x(f(x)+(ρ/2)∥Ax+Bz^k−c+u^k∥^2_2) xk+1:=argminx(f(x)+(ρ/2)∥Ax+Bzk−c+uk∥22) z k + 1 : = a r g m i n z ( g ( z ) + ( ρ / 2 ) ∥ A x k + B z − c + u k ∥ 2 2 ) z^{k+1}:=argmin_z(g(z)+(ρ/2)∥Ax^k+Bz−c+u^k∥^2_2) zk+1:=argminz(g(z)+(ρ/2)∥Axk+Bz−c+uk∥22) u k + 1 : = u k + A x k + 1 + B z k + 1 − c u^{k+1}:=uk+Ax^{k+1}+Bz^{k+1}−c uk+1:=uk+Axk+1+Bzk+1−c
可以看出,每次迭代分为三步:
求 解 与 x 相 关 的 最 小 化 问 题 , 更 新 变 量 x 求解与 x相关的最小化问题,更新变量 x 求解与x相关的最小化问题,更新变量x 求 解 与 z 相 关 的 最 小 化 问 题 , 更 新 变 量 z 求解与 z 相关的最小化问题,更新变量 z 求解与z相关的最小化问题,更新变量z 更 新 对 偶 变 量 u 更新对偶变量 u 更新对偶变量u
ADMM名称中的“乘子法”是指这是一种使用增广拉格朗日函数(带有二次惩罚项)的对偶上升(Dual Ascent)方法,而“交替方向”是指变量 x 和 z 是交替更新的。两变量的交替更新是在 f ( x ) f(x) f(x) 或 g ( z ) g(z) g(z)可分时可以将优化问题分解的关键原因。
收敛性
可以证明,当满足条件
函数 f , g f,g f,g具有 closed, proper, convex 的性质
拉格朗日函数 L 0 L0 L0 有鞍点
时,ADMM 的迭代收敛(当 k → ∞ k→∞ k→∞, r k → 0 , f ( x k ) + g ( z k ) → p ⋆ , y k → y ⋆ r^k→0,f(x^k)+g(z^k)→p^⋆,y^k→y^⋆ rk→0,f(xk)+g(zk)→p⋆,yk→y⋆。这样的收敛条件比没有使用增广拉格朗日函数的对偶上升法的收敛条件宽松了不少。
在高精度要求下,ADMM 的收敛很慢;但在中等精度要求下,ADMM 的收敛速度可以接受(几十次迭代)。因此 ADMM 框架尤其适用于不要求高精度的优化问题,这恰好是大规模统计学习问题的特点。
一致性(Consensus)问题
一类可用 ADMM 框架解决的特殊优化问题是一致性(Consensus)问题,其形式为
m i n ∑ i = 1 N f i ( z ) + g ( z ) min∑^N_{i=1}f_i(z)+g(z) mini=1∑Nfi(z)+g(z)
将加性优化目标 ∑ i = 1 N f i ( z ) ∑ i = 1 N f i ( z ) ∑^N_{i=1}f_i(z)∑_{i=1}^Nf_i(z) ∑i=1Nfi(z)∑i=1Nfi(z) 转化为可分优化目标 ∑ i = 1 N f i ( x i ) ∑ i = 1 N f i ( x i ) ∑^N_{i=1}f_i(x_i)∑_{i=1}^Nf_i(x_i) ∑i=1Nfi(xi)∑i=1Nfi(xi),并增加相应的等式约束条件,可得其等价问题
m i n ∑ i = 1 N f i ( x i ) + g ( z ) s . t . x i − z = 0 , i = 1 , … , N ( 2 ) min∑^N_{i=1}f_i(x_i)+g(z) s.t.x_i−z=0, i=1,…,N\qquad (2) mini=1∑Nfi(xi)+g(z)s.t.xi−z=0,i=1,…,N(2)
这里约束条件要求每个子目标中的局部变量 x i x_i xi与全局变量 z z z 一致,因此该问题被称为一致性问题。
可以看出,令式(1)中的
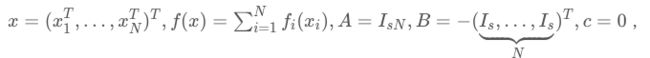
即得到式(2)。因此 Consensus 问题可用 ADMM 框架求解,其迭代方法为
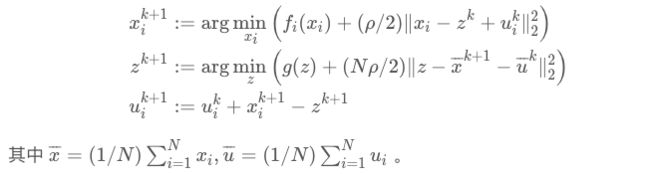
可 以 看 出 , 变 量 x 和 对 偶 变 量 u 的 更 新 都 是 可 以 采 用 分 布 式 计 算 的 。 只 有 在 更 新 变 量 z 时 , 需 要 收 集 x 和 u 分 布 式 计 算 的 结 果 , 进 行 集 中 式 计 算 。 可以看出,变量 x 和对偶变量 u 的更新都是可以采用分布式计算的。只有在更新变量 z 时,需要收集 x和 u分布式计算的结果,进行集中式计算。 可以看出,变量x和对偶变量u的更新都是可以采用分布式计算的。只有在更新变量z时,需要收集x和u分布式计算的结果,进行集中式计算。
统计学习问题应用
统计学习问题也是模型拟合问题,可表示为
m i n l ( D , d , z ) + r ( z ) min l(D,d,z)+r(z) minl(D,d,z)+r(z)
其中 z ∈ R n z∈R^n z∈Rn 是待学习的参数, D ∈ R m × n D∈R^{m×n} D∈Rm×n 是模型的输入数据集, d ∈ R m d∈R^m d∈Rm是模型的输出数据集, l : R m × n × R m × R n → R l:R^{m×n}×R^m×R^n→R l:Rm×n×Rm×Rn→R 是损失函数, r : R n → R r:R^n→R r:Rn→R 是正则化项, m表示数据的个数, n表示特征的个数。
对于带L1正则化项的线性回归(Lasso),其平方损失函数为
l ( D , d , z ) = ( 1 / 2 ) ‖ D z − d ‖ 2 2 l(D,d,z)=(1/2)‖Dz−d‖^2_2 l(D,d,z)=(1/2)‖Dz−d‖22
对于逻辑回归(Logistic Regression),其极大似然损失函数为
l ( D , d , z ) = 1 T ( l o g ( e x p ( D z ) + 1 ) − D z d T ) l(D,d,z)=1^T(log(exp(Dz)+1)−Dzd^T) l(D,d,z)=1T(log(exp(Dz)+1)−DzdT)
对于线性支持向量机(Linear Support Vector Machine),其合页(Hinge)损失函数为
l ( D , d , z ) = 1 T ( 1 − D z d T ) + l(D,d,z)=1^T(1−Dzd^T)_+ l(D,d,z)=1T(1−DzdT)+
将训练数据集(输入数据和输出数据)在样本的维度( m m m )划分成 N N N 块

可以看出,令式(2)中的 f i ( x i ) = l i ( D i , d i , x i ) , g ( z ) = r ( z ) f_i(x_i)=l_i(D_i,d_i,x_i),g(z)=r(z) fi(xi)=li(Di,di,xi),g(z)=r(z) ,即得到式(3),因此 统计学习问题可用 Consensus ADMM 实现分布式计算,其迭代方法为
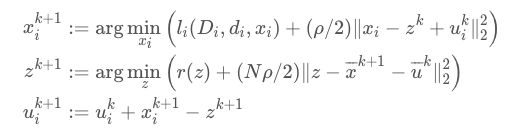
分布式实现
MPI
MPI 是一个语言无关的并行算法消息传递规约。使用 MPI 范式的 Consensus ADMM 算法如下所示。
1. I n i t i a l i z e N p r o c e s s e s , a l o n g w i t h x i , u i , r i , z 1. Initialize N processes, along with x_i,u_i,r_i,z 1.InitializeNprocesses,alongwithxi,ui,ri,z
Repeat

该算法中假设有 N 个处理器,每个处理器都运行同样的程序,只是处理的数据不同。第6步中的 Allreduce 是 MPI 中定义的操作,表示对相应的局部变量进行全局操作(如这里的求和操作),并将结果更新到每一个处理器。
MapReduce
MapReduce 是一个在工业界和学术界都很流行的分布式批处理编程模型。使用 MapReduce 范式的 Consensus ADMM 算法(一次迭代)如下所示。

为了实现多次迭代,该算法需要由一个 wrapper 程序在每次迭代结束后判断是否满足迭代终止条件
![]()
若不满足则启动下一次迭代。
参考文献
1.Boyd S, Parikh N, Chu E, et al. Distributed optimization and statistical learning via the alternating direction method of multipliers[J]. Foundations and Trends® in Machine Learning, 2011, 3(1): 1-122.
2.Eckstein J, Yao W. Understanding the convergence of the alternating direction method of multipliers: Theoretical and computational perspectives[J]. Pac. J. Optim., 2014.
3.Lusk E, Huss S, Saphir B, et al. MPI: A Message-Passing Interface Standard Version 3.1[J], 2015.
4.Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
5.http://shijun.wang/2016/01/19/admm-for-distributed-statistical-learning/