Opencv4 -Python官方教程学习笔记35---特征匹配
目标
我们将在OpenCV中使用Brute-Force匹配器和FLANN匹配器 。
我们将在OpenCV中使用Brute-Force匹配器和FLANN匹配器
蛮力匹配器很简单。它使用第一组中一个特征的描述符,并使用一些距离计算将其与第二组中的所有其他特征匹配。并返回最接近的一个。
对于BF匹配器,首先我们必须使用cv.BFMatcher()创建BFMatcher对象。 它需要两个可选参数。第一个是normType,它指定要使用的距离测量。默认情况下为cv.NORM_L2。对于SIFT,SURF等(也有cv.NORM_L1)很有用。 对于基于二进制字符串的描述符,例如ORB,BRIEF,BRISK等,应使用cv.NORM_HAMMING,该函数使用汉明距离作为度量。如果ORB使用WTA_K == 3或4,则应使用cv.NORM_HAMMING2。
第二个参数是布尔变量,即crossCheck,默认情况下为false。如果为true,则Matcher仅返回具有值(i,j)的那些匹配项,以使集合A中的第i个描述符具有集合B中的第j个描述符为最佳匹配,反之亦然。即两组中的两个特征应彼此匹配。它提供了一致的结果,并且是D.Lowe在SIFT论文中提出的比率测试的良好替代方案。
创建之后,两个重要的方法是BFMatcher.match()和BFMatcher.knnMatch()。第一个返回最佳匹配。第二种方法返回k个最佳匹配,其中k由用户指定。当我们需要对此做其他工作时,它可能会很有用。
就像我们使用cv.drawKeypoints()绘制关键点一样,cv.drawMatches()可以帮助我们绘制匹配项。它水平堆叠两张图像,并绘制从第一张图像到第二张图像的线,以显示最佳匹配。还有cv.drawMatchesKnn绘制所有k个最佳匹配。如果k=2,它将为每个关键点绘制两条匹配线。因此,如果要选择性地绘制,则必须通过掩码。
使用ORB描述符进行Brute-Force匹配
在这里,我们将看到一个有关如何在两个图像之间匹配特征的简单示例。在这种情况下,我有一个queryImage和trainImage。我们将尝试使用特征匹配在trainImage中找到queryImage。
我们正在使用ORB描述符来匹配特征。因此,让我们从加载图像,查找描述符等开始。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# path1 = r'D:\Laboratory\Study\Computer Vision\opencv4-python\tezheng1.png'
# path2 = r'D:\Laboratory\Study\Computer Vision\opencv4-python\tezheng2.png'
path1 = r'D:\Laboratory\Study\Computer Vision\opencv4-python\tezheng3.jpg'
path2 = r'D:\Laboratory\Study\Computer Vision\opencv4-python\tezheng4.jpg'
img1 = cv.imread(path1,0) # 索引图像
img2 = cv.imread(path2,0) # 训练图像
# 初始化ORB检测器
orb = cv.ORB_create()
# 基于ORB找到关键点和检测器
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
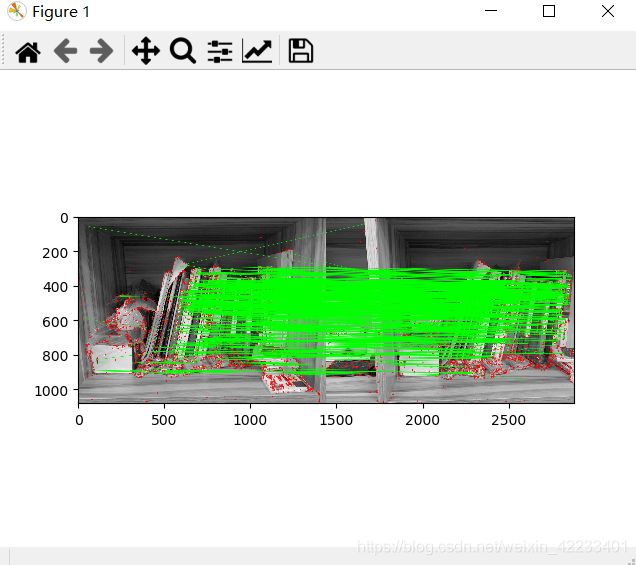
接下来,我们创建一个距离测量值为cv.NORM_HAMMING的BFMatcher对象(因为我们使用的是ORB),并且启用了CrossCheck以获得更好的结果。然后,我们使用Matcher.match()方法来获取两个图像中的最佳匹配。我们按照距离的升序对它们进行排序,以使最佳匹配(低距离)排在前面。然后我们只抽出前10的匹配(只是为了提高可见度。您可以根据需要增加它)
# 创建BF匹配器的对象
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True) # 匹配描述符.
matches = bf.match(des1,des2) # 根据距离排序
matches = sorted(matches, key = lambda x:x.distance)
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches,None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.imshow(img3),plt.show()
结果
什么是Matcher对象
matchs = bf.match(des1,des2)行的结果是DMatch对象的列表。该DMatch对象具有以下属性: - DMatch.distance-描述符之间的距离。越低越好。 - DMatch.trainIdx-火车描述符中的描述符索引 - DMatch.queryIdx-查询描述符中的描述符索引 - DMatch.imgIdx-火车图像的索引。
带有SIFT描述符和比例测试的Brute-Force匹配
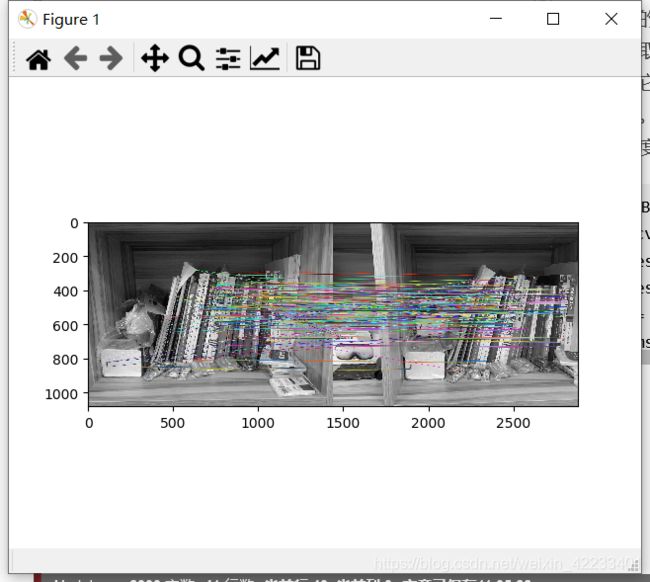
这次我们将使用BFMatcher.knnMatch()获得k个最佳匹配。在此示例中,我们将k = 2,以便可以应用D.Lowe在他的论文中阐述的比例测试。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
path1 = r'D:\Laboratory\Study\Computer Vision\opencv4-python\tezheng3.jpg'
path2 = r'D:\Laboratory\Study\Computer Vision\opencv4-python\tezheng4.jpg'
img1 = cv.imread(path1,0) # 索引图像
img2 = cv.imread(path2,0) # 训练图像
# 初始化SIFT描述符
sift = cv.xfeatures2d.SIFT_create()
# 基于SIFT找到关键点和描述符
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# 默认参数初始化BF匹配器
bf = cv.BFMatcher()
matches = bf.knnMatch(des1,des2,k=2)
# 应用比例测试
good = []
for m,n in matches:
if m.distance < 0.75*n.distance:
good.append([m])
# cv.drawMatchesKnn将列表作为匹配项。
img3 = cv.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.imshow(img3),plt.show()
结果

使用ORB时,你可以参考下面。根据文档建议使用带注释的值,但在某些情况下未提供必需的参数。其他值也可以正常工作。
FLANN_INDEX_LSH = 6
index_params= dict(algorithm = FLANN_INDEX_LSH,
table_number = 6, # 12
key_size = 12, # 20
multi_probe_level = 1) #2
第二个字典是SearchParams。它指定索引中的树应递归遍历的次数。较高的值可提供更好的精度,但也需要更多时间。如果要更改值,请传递search_params = dict(checks = 100)
代码:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
path1 = r'D:\Laboratory\Study\Computer Vision\opencv4-python\tezheng3.jpg'
path2 = r'D:\Laboratory\Study\Computer Vision\opencv4-python\tezheng4.jpg'
img1 = cv.imread(path1,0) # 索引图像
img2 = cv.imread(path2,0) # 训练图像
# 初始化SIFT描述符
sift = cv.xfeatures2d.SIFT_create()
# 基于SIFT找到关键点和描述符
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# FLANN的参数
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50) # 或传递一个空字典
flann = cv.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
# 只需要绘制好匹配项,因此创建一个掩码
matchesMask = [[0,0] for i in range(len(matches))]
# 根据Lowe的论文进行比例测试
for i,(m,n) in enumerate(matches):
if m.distance < 0.7*n.distance:
matchesMask[i]=[1,0]
draw_params = dict(matchColor = (0,255,0),
singlePointColor = (255,0,0),
matchesMask = matchesMask,
flags = cv.DrawMatchesFlags_DEFAULT)
img3 = cv.drawMatchesKnn(img1,kp1,img2,kp2,matches,None,**draw_params)
plt.imshow(img3,),plt.show()
结果: