spark本地提交集群运行踩过的坑
spark本地提交集群运行踩过的坑
1.本地提交,集群跑spark程序设置(scala)
val conf = new SparkConf().setAppName("SparkWordCount")
conf.setMaster("spark://hadoop-01:7077")
conf.setJars(Array("D:\\hadoop\\spark\\target\\zbs_com-1.0-SNAPSHOT.jar"))
问题1:
requirement failed: Can only call getServletHandlers on a running MetricsSystem
收到了请求但处理消息有问题。像是对象序列化后的id值不一致,感觉应该是两边jdk、或者spark版本不一致导致的。查看java -version,都是1.8,排除。spark版本,集群是2.2.1,我本机是2.3.0,比集群版本高。
解决办法:统一Spark版本。将本机也改为2.2.1版本,并修改环境变量,重启电脑。即可以正常提交任务。
原文链接:https://blog.csdn.net/nazhidao/article/details/79979417
问题2
Intellij控制台输出警告:WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
这一行特别醒目
WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
在sparkui界面的
Caused by: java.net.UnknownHostException: DESKTOP-J06F0SV
初始工作没有接受任何资源;检查你的集群用户界面以确保工人注册并有足够的资源
这是我的提交任务后的集群信息:
网上说法
:
1.集群配置
2.内存问题
3.我的问题是 :
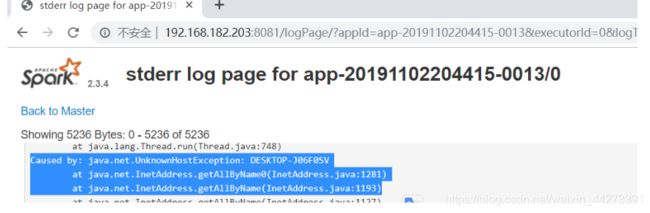
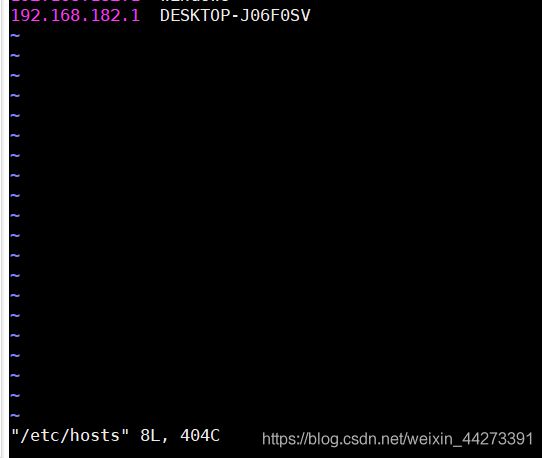
这个是主机名 DESK(…)在电脑属性(环境变量)处可以看到加到集群的/etc/hosts里
附代码
最后修改的代码:
package spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object spark_test {
def main(args: Array[String]): Unit = {
//ps:模板封装成一个方法以后调用方法即可
//模板代码
/*
需要创建SparkConf()对象 相当于MR中配置
必传参数
setAppName() 设置任务的名称 不传默认是一个UUID产生名字
设置运行模式
不写这个参数可以打包提交集群
写这个参数设置本地模式
setMaster() 传入的参数有如下写法
"local" --> 本地一个线程来进行任务处理
"local[数值]" --> 开始相应数值的线程来模拟spark集群运行任务
"local[*]" --> 开始相应线程数来模拟spark集群运行任务
两者区别:
数值类型--> 使用当前数值个数来进行处理
* -->当前程序有多少空闲线程就用多少空闲线程处理
*/
// val spark=SparkSession
val conf = new SparkConf().setAppName("SparkWordCount")
conf.setMaster("spark://hadoop-01:7077")
conf.setJars(Array("D:\\hadoop\\spark\\target\\zbs_com-1.0-SNAPSHOT.jar"))
// conf.setExecutorEnv("executor-memory","128m")
val sc = new SparkContext(conf)
//通过sparkcontext对象就可以处理数据
//读取文件 参数是一个String类型的字符串 传入的是路径
val lines: RDD[String] = sc.textFile("hdfs://192.168.182.201:9000/abc")
//切分数据
val words: RDD[String] = lines.flatMap(_.split(" "))
//将每一个单词生成元组 (单词,1)c
val tuples: RDD[(String, Int)] = words.map((_,1))
//spark中提供一个算子 reduceByKey 相同key 为一组进行求和 计算value
val sumed: RDD[(String, Int)] = tuples.reduceByKey(_+_)
//对当前这个结果进行排序 sortBy 和scala中sotrBy是不一样的 多了一个参数
//默认是升序 false就是降序
val sorted: RDD[(String, Int)] = sumed.sortBy(_._2,false)
//将数据提交到集群存储 无法返回值
sorted.saveAsTextFile("hdfs://hadoop-01:9000/out/12")
//本地模式
//一定要设置setMaster()
//可以直接打印
//println(sorted.collect.toBuffer)
//这种打印也可以
//sorted.foreach(println)
// val add1:RDD[Int] = sc.parallelize(List(1,2,3,4,5,6))
// val value:RDD[(Int,Int)] = add1.map((_,1))
// value.partitionBy()
// add1.mapPartitions()
//回收资源停止sc,结束任务
sc.stop()
}
}
dd1.map((_,1))
// value.partitionBy()
// add1.mapPartitions()
//回收资源停止sc,结束任务
sc.stop()
}
}