区块链研究实验室 | 如何基于tendermint实现fabric的拜占庭容错排序
前言
HyperLedger Fabric作为一个架构灵活的企业级区块链平台,正在被越来越多的企业用于生产环境。
fabric orderer服务过程分析
我们先以最简单的solo为例,看一下Fabric的orderer节点接收排序请求后的主要处理逻辑。首先,orderer的排序服务需要实现consensus包的Consenter(排序引擎)interface,Consenter接口只需要实现一个HandleChain方法,该方法需要返回一个Chain对象。Chain对象需要实现Chain interface,实现Order(普通交易排序)、Configure(配置交易排序)、Start等主要方法。那我们现在来看一下当一个orderer节点启动后,将会经过怎样的步骤,如何实现对交易的排序。
1、当我们在fabric网络定义排序类型为solo的情况时,orderer节点启动会初始化一个solo consenter对象(参考代码orderer/common/server/main.go中的方法initializeMultichannelRegistrar)。
2、当orderer启动后,orderer节点会检查本地账本中存在的通道,此时发现只有一个testchainid通道(了解fabric的话,我们会知道当区块链网络创世时,会有一条默认名为testchainid的系统通道),solo consenter会为系统通道testchainid创建一个chain对象保存在orderer内存中,并启动监听来自orderer节点接收到的系统通道配置交易(testchainid只会接受配置类交易,如创建新的通道请求)。chain对象请求监听的原理其实是在chain的start方法中会启动一个goroutine监听一个名为sendChan的go chan。
3、此时我们假设有一个创建名为mychannel新信道的交易被orderer接收到,只能是testchainid系统通道对应的chain对象来进行处理,此时orderer节点会判断该交易类型为配置类型交易,则调用chain对象的configure方法,configure方法将交易写入chain.sendChan中。
4、此时,会触发sendChan的监听服务,监听服务会检查交易并将交易通过ch.support.BlockCutter().Ordered方法放入本地队列中等待出块,出块任务在启动orderer节点时时会启动一个chan timer,每隔固定时间(设置的batchTimeOut)会从队列中取出一定的交易数量(不超过设置的每个块最大的交易量)出块,并写入orderer本地账本,当mychannel的创建交易被成功受理出块,即意味着名为mychannel的新通道已经被创建。
5、mychannel通道创建后,solo consenter会通过HandleChain方法为之创建一个新的chain对象,mychannel chain对象会受理mychannel信道的交易排序,原理与以上同。
以上只是以solo的order type为例,fabric截止到目前的1.4版本,官方推荐使用更稳定的kafka排序。kafka排序与上述例子中solo排序的区别是:可以支持多个orderer节点,所有的交易可以请求任何一个orderer节点,请求的orderer节点本地排序出块后会通过kafka集羣将数据同步给其他的orderer节点,意味着排序服务可以实现更高的可用性。我们在查看orderer源码时,发现了官方已经在做raft排序。简单测试了一下,过程是能够走通了,大家可以耐心等release版本。
为什么要做pbft排序服务
我们认为目前已经release的kafka排序是能够满足初级的联盟链需求的。背景是,现在的联盟链更多是一强多弱型企业联盟,如一个大型公司主导区块链业务与技术,其上下游机构合作参与;如一个集团性企业布道区块链,其分子公司合作参与;如aws、阿里云等云厂商提供baas云服务,企业使用只需要向baas申请节点资源。以上情况中,kafka集羣大都需要部署到大型公司、集团总部或者云厂商,保证高计算能力和高可用,是可以支持比较高并发的上炼请求的(官方数据是TPS可以达到3000以上)。
为什么说是初级呢?我们可以发现以上列举的情况实际是有偏离区块链初衷的,区块链在联盟中更应该作为联盟企业间平等、互信合作的基础设施。当联盟间各个企业不存在一强多弱,真正是几家平等的企业在合作时,在技术设计中就会存在一个比较大的疑惑,kafka排序服务应该部署在哪里呢?也许部署到公有云上是一个选择,但当云厂商本身是利益的相关方呢?
所以我们认为,无论是官方正在开发的raft排序还是我们正在做的pbft排序,最重要的目的就是首先要允许orderer节点部署到不同的企业,每个企业都参与到fabric的排序服务,而不是像kafka排序一样需要将排序服务部署到一个中心化的机构。
基于tendermint的abci实现fabric排序服务
Tendermint提供了一个高性能、一致的、安全的BFT共识引擎,严格的分叉问责保证能够控制作恶者的行为。Tendermint非常适合用于扩展异构区块链,包括公有链以及注重的性能的许可链/联盟链,像Ethermint 就是一次对Ethereum以太坊POS机制的快速实现。使用Tendermint在许可/联盟链域中的成功案例包括Oracle ,CITA 和Hyperledger Burrow 。tendermint项目的团队是正在进行著名跨链项目Cosmos研发的团队(相信很多同学一定关注过这个明星项目),而tendermint也是作为共识协议用于在Cosmos Hub上构建第一个分区。Tendermint独有的abci定义了区块链执行的标准接口,可以允许用户自定义实现接口内容,不需要修改tendermint源代码来集成他。关于更多tendermint的介绍这里不再赘述。
这里,我们通过tendermint的abci来实现fabric的orderer服务。
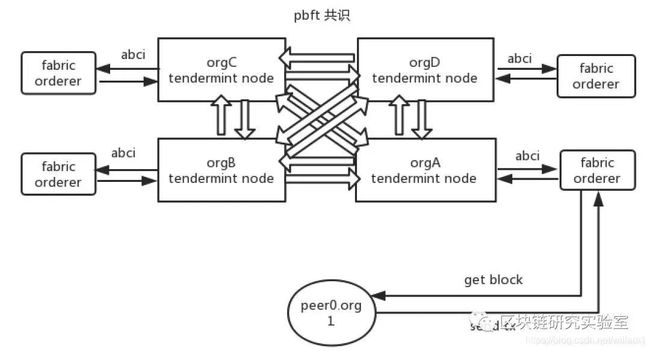
fabric的排序方式,需要peer节点将交易proposal 发送给任一orderer节点,kafka排序是orderer节点藉助kafka消息队列,而raft排序是orderer节点藉助etcd实现区块传递给其他orderer节点。而在这里,我们让orderer节点藉助其内部的tendermint节点服务,将消息传递给其他orderer节点,并能够兼容其中的拜占庭节点。
下面我们藉助tendermint的abci接口,实现代码不侵入,完成orderer的tendermint pbft排序。
首先,新建一个全新的package实现fabric consensus的所有接口方法。这里可以判断,每次handleChain方法触发(一个新的fabric channel创建)时,尝试调用tendermint包的node.NewNode方法启动tendermint服务,可以多个channel只启动一个tendermint服务。
然后,每当有新的交易传递到orderer时,envelope类型的交易都会通过order方法和configure方法传递进来,这里我们只需要在两个方法中,将交易串行化为tendermint可以传递的数据类型如byte数组,调用tendermint节点的Mempool.checkTx方法,将交易打包到tendermint的内存池中即可。
之后的事情,打包到tendermint内存池中的交易,将进行多个orderer节点的pbft共识,这里会执行tendermint的标准p2p通信和多轮共识。
完成共识之后,需要我们通过tendermint的abci的DeliverTx和commit方法获取到共识后的交易,并调用fabric的CreateNextBlock方法和WriteBlock方法打包生成区块。即完成一个完整的交易共识并记账。
这里,有一个比较容易产生疑问的问题,我们知道fabric是多信道的账本结构,而tendermint是单通道账本,如何做到兼容两边?在这里,实际我们是需要写fabric和tendermint两套账本的,从上述过程我们可以看到,共识交易完成后需要每个orderer节点自行调用fabric自带的写区块方法在对应的通道中进行写块,而同时我们在abci中也创建了一个tendermint的基于leveldb的账本。即每一笔交易,我们也在tendermint的账本中记录了一份,只是没有区分通道,因为本来fabric中的orderer也是记录的全信道数据。该账本主要用于fabric追块,当某个orderer节点的tendermint块高度比其他节点小时,会触发tendermint的追块功能,从tendermint中读取交易后写入自己的tendermint账本,同时写入fabric对应通道的区块中。
以上整个过程,没有动过tendermint的源代码,只需要扩展一个新的实现fabric的consensus接口的类,在类中同时实现tendermint的abci接口即可。具体细节如果有读者感兴趣可以反馈给作者,可能后面会开源一个简单的demo出来。
代码已经通过单元测试和first network脚本集成测试。后续会补充基于hyperledger caliper的性能测试结果。现在还在概念验证阶段,很多功能还未完成,如动态添加orderer节点需要结合tendermint动态添加validator功能来做,性能也未优化,也或许还有一些其他问题,所有还未用于生产环境。 也希望各位读者若对方案有疑问或有见解可以随时指教,谢谢!
本文转载于公众号:区块链研究实验室