本文由作者王改革授权网易云社区发布。
一、背景和实现目标
在开发严选数据产品(大麦商品数据运营平台和移动数据工作台VIPAPP)的时候,最多的业务场景就是对实时和离线数据模型中查询、处理、统一数据结构返回给前端。所以在开发的同时也一直在思考如何将这些相似的数据处理流程统一起来,更关注数据指标本身。
开发中经常遇到的几个问题是:
数据查询连接管理分散
模型查询结果缓存分散
对于模型数据查询结果缺少统一的数据变换模块支持,每日产出的实时数据指标以及离线数据指标经过后端逻辑做接口返回的时候,会有大量的get、set操作,如果同时需要计算指标同比、环比、占比、对比值等复合指标时,就会充斥大量的重复脏代码。
依赖的数据服务对存储在MySQL、GP、Kylin、HBase等存储引擎的数据模型暂时没有多模型的连接支持。
所以针对以上问题,我们希望能够设计出能够在数据产品中使用的通用指标查询计算模块(DPRequestManager),主要实现如下目标:
管理数据模型查询,封装对于 统一查询服务(DQS)、MySQL等查询请求,提供查询连接池。
提供灵活的数据变换能力
能够通过配置对相应指标(包括指标值、环比、占比、同比等)自动计算,减少过多的冗余代码。
支持数据对象映射,减少频繁的取值和赋值操作
支持查询级别的缓存(可以根据系统需求自定义缓存时间、可以设定缓存条件),减少对依赖服务的查询压力。
二、通用指标查询计算模块(DPRequestManager)组织结构
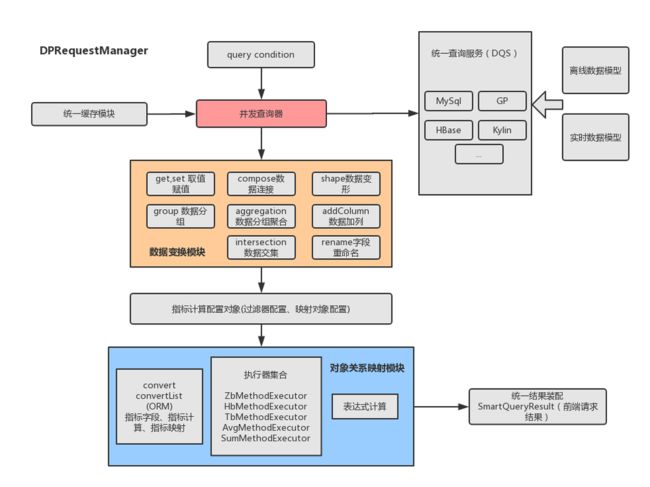
红色部分的并发查询器负责管理数据产品与底层数据查询存储引擎的连接,统一管理各种数据查询。DPRequestManager会作为数据产品模型查询的统一入口,封装底层数据模型存储引擎,为数据查询提供线程池服务。同时此部分还提供模型退化的能力。
统一缓存模块负责对数据查询做条件缓存,对于每日数据未产出或者其他情况可以对查询结果约定一些必要条件来决定是否缓存查询结果(缓存级别为请求级别)。
橙色部分的数据变换模块可以对DQS获取的多表数据进行灵活数据变换
配置模块可以对数据关系映射以及相应的复合指标计算做相应配置,统一生成结果,减少冗余代码
三、数据变换模块支持操作
对于从模型存储引擎查询结果处理成List
命名规则:模块内部将使用数据dataKey存放查询处理结果,dateKey对应的list结果可以类比excel行列表,其中的列名对应Map结构的key值。
现在主要提供如下数据操作:
1. compose(多个查询集合进行组合,做内存连接使用,对于多个数据中存在同名列的情况,可选择按照FIFO进行是否覆盖) compose({"group_id", "group_name"}, "result_A", "resultB")
2. rename(将数据某一列列名重新命名)group(基于元数据行进行分组) rename ("dk", {"sale_amount_day", "sale_qty_day"}, {"sale_amount, sale_qty"})
3. group(基于数据行进行分组) group(row -> new StringJoiner("_").add(row.get("week").add(row.get("group_id")))
4. aggregation(基于数据行进行分组, 然后对度量指标字段进行聚合) aggregation({"week", "group_id", "group_name"}, {sum("sale_amount"), sum("sale_qty")})
5. shape(数据变形,将多列数据变成宽表数据,平坦化透视表结构)
6. intersection(多个数据集合取交集)
7. top(根据有序度量取top集合)
四、指标计算配置以及对象关系映射
这个地方主要解决两个问题:
模型数据查询结果到数据对象的映射,减少频繁的取值和赋值,现在通用的ORM框架都能解决这个问题,DPRequestManager为了配合复合指标计算通过反射来实现数据对象映射部分。
映射过程中的指标计算(指标表达式计算、环比、同比、占比等复合指标的计算)
DPRequestManager主要是通过两个配置来配合解决复合指标计算的问题。
第一个配置主要是定义数据对象映射的数据筛选规则(目标数据集合、环比数据集合、占比数据集合等)
{
"clazz": StockDTO.class,
"useDate": "2018-12-07", // 指定目标值日期
"hbDate": "2018-12-06", // 指定环比日期
"hbKey": "group_id", // 计算环比使用
"filterKey": "", // 过滤器
"filterValue": ""
}
第二个配置是数据对象DTO的配置(通过注解对复合指标计算进行配置定义)
DTO配置主要使用了三个注解,@FromDO,@FunctionDO,@IgnoreAssign
@From 定义简单按key取值
@FunctionDO定义复合指标计算规则(hb,tb,zb,avg,sum等)
@IgnoreAssign 对象映射是字段忽略
同时支持定义的复合指标对象的指标计算赋值。
@Datapublic class StockSingleVO extends BaseVO { // 简单取值,默认驼峰转下划线取字段group_id
private Long groupId; @FromDO("'商品组:'+group_name") private String groupName; // 简单取值,直接在库量
@FromDO("stock_cnt_zhuzhan_1d") private Number stockCnt; // 环比,对在库量字段计算环比
@FromDO("stock_cnt_zhuzhan_1d") @FunctionDO(types = FunctionTypeEnum.HB) private Number stockCntHB; // 简单取值,计算在库+在途量
@FromDO(value = "stock_cnt_zhuzhan_1d+onway_cnt_zhuzhan_1d") private Number stockAndOnwayCnt; // 环比计算,计算在库+在途的环比
@FromDO(value = "stock_cnt_zhuzhan_1d+onway_cnt_zhuzhan_1d") @FunctionDO(types = FunctionTypeEnum.HB) private Number stockAndOnwayCntHB; // 占比计算
@FromDO(value = "stock_cnt_zhuzhan_1d+onway_cnt_zhuzhan_1d") @FunctionDO(types = FunctionTypeEnum.ZB) private Number stockAndOnwayCntZB;
}
数据过滤规则配置和数据对象中定义的复合指标计算配置一起支持数据对象映射,这样可以减少大量重复赋值取值以及手动计算复合指标的工作。同时配合使用数据变换模块和数据对象映射能够释放更大的灵活性,将数据变换模块、数据对象映射、复合指标计算模块解耦。
模块查询代码示例:
/**
* condition1,condition2为构造的指标查询条件
*/EngineRequest request1 = new EngineRequest(EngineType.DQS, condition1, EngineResultTypeEnum.LIST); // 构造查询请求1EngineRequest request2 = new EngineRequest(EngineType.DQS, condition2, EngineResultTypeEnum.LIST); // 构造查询请求2// 构造配置1(数据过滤配置 -> 配置目标日期、环比日期、计算环比目标分组key)EngineConvertConfig config = new EngineConvertConfig<>(StockSingleVO.class, "2018-12-07", "group_id", null, null);
config.setHbDate("2018-12-06");
Listlist = requestEngineManager.initThreadLocal()
.addRequest(dk1, request1)
.addRequest(dk2, request2)
.execute()
.compose(true, Arrays.asList("date_id", "group_id"), dk_new, dk1, dk2) // 请求结果连接
.converToList(dk_new, config); // 数据对象映射// 前端数据结构组装SmartQueryResult result = BaseVO.assembleResult(list, StockSingleVO.class);
五、总结
数据产品中很多通用的部分可以抽出来作为单独模块或者服务。文中介绍的复合指标查询模块已经在大麦商品数据运营平台中实践,它把数据产品指标查询、计算以及对象映射等公共部分提取出来,有效的提高开发效率并能够降低开发成本。
相关文章:
【推荐】 MySQL Group Replication数据安全性保障
【推荐】 Spring Boot 学习系列(10)—SpringBoot+JSP的使
【推荐】 JVM运行内存分配和回收