Eigen矩阵库使用说明
这是我在做项目时,给下一届接手的人写的一个关于Eigen库的快速上手手册,主要是针对于项目的应用来写的。当时使用Eigen库的目的是,将Matlab写的,LPCC和MFCC两种声音识别算法,十字形声阵列的MUSIC定位算法,和SVM分类器算法,转换成C++然后移植到到ARM处理器上(操作系统级上的并不是裸机)。而使用Eigen库的原因就是,其能够在编译时进一步优化,而且只需导入头文件即可进行调用,而不像其他的一些库需要安装那么麻烦。这篇使用说明是在2016年7月14日完成的。
由于我是第一次写这个博客,很多地方的图片我不知道怎么调整大小。原来的写的说明手册是在word上写的,已经上传到了CSDN上。
下面就是关于Eigen矩阵库的使用说明。
准备工作
http://blog.csdn.net/augusdi/article/details/12907341
建议先把这个网页上的东西看完,边看边输入里面的程序来看,撑死3个小时就完成了
下面以这个快速指导手册为准来讲解:
http://eigen.tuxfamily.org/dox/group__QuickRefPage.html
一、Modules and Header files
#include
这里一般就包括了我们所需要的所有函数,如果还需要稀疏部分的话,那就使用
#include
二、Array, matrix and vector types
1. Eigen提供了两种稠密矩阵:数学上的矩阵和向量,这两种通过使用模板Matrix类来实现;通常对于1维或者2维的数组通过模板Array类来实现。这两种类的不同点是主要在于API上:Array类提供了简单的数据操作的接口。而Matrix类提供了线性代数操作的接口。一般来说我们转算法只用Matrix好了,以后是不是需要优化这里先不管
两个类的定义
Matrix
![]()
Array
![]()
因为我们主要需要用的是Matrix类,这一类中有很多的成员函数,可以参考
http://eigen.tuxfamily.org/dox/classEigen_1_1Matrix.html
继续讲:

l Scalar是类型,可以使float, double, bool, int, std::complex
l RowsAtCompileTime和ColsAtCompileTime是行数和列数,可以使动态的也可以是静态的
l Option是按列排列还是按行排列,默认是按列排列(这个参数就不用设了,这样就跟Matlab一样都是按列排列)。
2. 行数和列数是动态的还是静态的还是一个动态一个静态都随便,下面给几个例子:

这里,Dynamic表示动态的意思。
3. 在大多数的情况下,我们可以用简单的方式来定义Matrix变量(通过typedef)

这里需要注意一下,向量一般都是指的是列向量(数学里也差不多,没发现所有的书上都喜欢定义列向量,然后转置成行向量嘛 -_-)。
上面只是一部分的例子,下面我会列举一下比较常用的例子:
4. 矩阵和数组之间的转换:

1) array()的定义如下

就是将矩阵表示转换成数组表示
2) matrix()的定义如下

就是将数组表示转换成矩阵表示
5. Basicmatrix manipulation
下面每栏按照下图的格式(总共4栏)

1) 构造函数

默认情况下,系数是未初始化的。1D objects表示1维的数组或者向量。2D objects表示2维的矩阵(就是有行和列),数组其实也是可以有二维的,上面没有列出来(实际上对于我们来说也不需要)
2) 初始化
![]()
这里要使用<<这个重载的运算符来进行赋值,在准备工作里的也说过了。这里需要说明的是,前面讲过,矩阵是按列存储的,所以在内存中的存储形式应该是1,4,7,2,5,8,3,6,9.但是这并不意味着我们通过<<来进行赋值时,也要按照列来输入,具体为什么需要看一下<<的重载定义。而我们同样可以跟Matlab一样,通过m1(0),m1(1)……(注意下标要从0开始)来一个一个的取出元素,我们可以发现,确实是按照列来存储的。具体的可以见http://eigen.tuxfamily.org/dox/group__TopicStorageOrders.html
3) 初始化

这里,Identity是单位矩阵的意思。
4) Runtimeinfo

这里,rows()和cols()是获取矩阵的行数和列数,size()是获取矩阵的大小(也就是有多少个数据)。
l innerSize()的定义如下
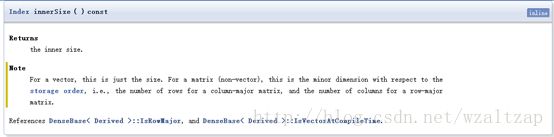
就是说,
向量的话(这里用的是vector,说明是列向量)和size()一样;
矩阵的话,这个矩阵是按列存储的,返回行数;这个矩阵是按行存储的话,返回列数
l outerSize()的定义如下

就是说,
向量的话,返回1;
矩阵的话,这个矩阵是按列存储的,返回列数;这个矩阵是按行存储的话,返回行数
l innerStride()的定义如下

首先,先要说明白一个问题,假设是按列存储的矩阵,那么一列就是一个slice。
所以这个函数就是在一个slice中,两个相邻元素之间的指针增量(不应该说是地址增量,因为地址是要算上数据类型大小的)
l outerStride()的定义如下

这个函数时两个相邻的slice之间的指针增量
l data()的定义如下

返回向量或者矩阵的数据部分数组的指针,可以用来进行数组(正常意义下的)转换成矩阵或者向量的操作
5) Compile-timeinfo
![]()
这一部分暂时还没什么用,这里就不展开了
6) Resizing

l resize函数的定义如下

上面可以看到有两个不同的定义,分开来说:

上面这个是针对向量的,参数只有一个size。注意这句话:这个方法对于那些固定值不是1的局部动态矩阵是没有效果的。
同时这里还需要注意一个地方,就是在例子中,w.resize(3);这句话中,w是一个固定尺寸的向量,这句话并没有对这个向量的个数进行增加或者删减,但是如果对个数进行增加或者减少时,就会出现错误,因为w的大小是固定的,而不是动态的。也就是固定大小的矩阵是不能使用resize()来修改矩阵的大小;

上面这个是对于矩阵的(其实也可以用于向量了,要明白的是,向量只是Matrix类中固定了其中一个参数为1的typedef)
注意第一句话:这个方法是针对于动态大小的矩阵,虽然在保证大小不变的前提下,可以使用它来对所有矩阵进行操作(但其实是没意义的了)。
如果你只想改变其中的一个参数,可以使用resize(NoChange_t,Index), resize(Index, NoChange_t),具体的见下面这两张图
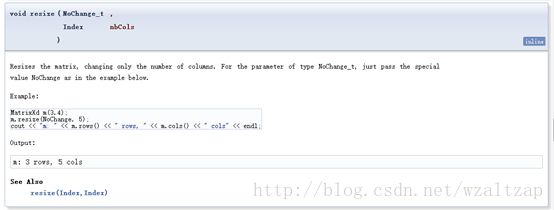

继续:
如果当前矩阵的系数个数和重新分配大小后的rows* cols正好相等,那么就没有进行内存的分配并且当前的值也没有改变。但是,其他情况下,包括收缩,所有的数据都进行了重新分配,并且以前的值都丢失了。
7) Coeffaccess with range checking
![]()
8) Coeffaccess without range checking
![]()
9) Assignment/copy
![]()
这里需要注意的是,使用“=”操作符操作动态矩阵时,如果左右边的矩阵大小不等,则左边的动态矩阵的大小会被修改为右边的大小
6. PredefinedMatrices

向量部分:
setConstant(value)是值都是value;
setRandom()是随机值
setLinSpaced(size, low, high)向量的值是在[low,high]之间分布,总共有size个数值
矩阵部分也是类似的,只是没有了setLinSpaced(size, low, high)
这部分内容很简单,这里不进行展开了
7. Mappingexternal arrays

这里直接看例子就好了,需要注意的是按列存储。
特别说明的是OuterStride<3>,根据前面提到过类似的(首字母大小写不一样),这个应该也是按照slice来操作,因为这个矩阵是2行3列按列存储,所以slice大小是2,然后类似于分帧,帧长是2,帧移是3。(可以试试是不是可以通过这种方式来实现分帧加窗,这样就可以不需要enframe函数了)
三、Arithmetic Operators
1. Eigen提供+、-、一元操作符“-”、+=、-=

1) +和-:两矩阵相加(矩阵中对应元素相加/减,返回一个临时矩阵)
2) -表示对矩阵取负(矩阵中对应元素取负,返回一个临时矩阵)
3) +=或者-=表示(对应每个元素都做相应操作)
2. 矩阵还提供与标量(单一个数字)的乘除操作,表示每个元素都与该标量进行乘除操作
![]()
二元操作符*在A*a中表示矩阵A中的每隔元素都与数字a相乘,结果放在一个临时矩阵中,矩阵的值不会改变。对于a*A、A/a、A*=a、A /=a也是一样。
3. 矩阵的相乘,矩阵与向量的相乘也是使用操作符*,共有*和*=两种操作符

4. 矩阵的转置和共轭转置
![]()
可以通过成员函数transpose()、conjugate()和 adjoint()来完成矩阵的转置,共轭矩阵,和共轭转置矩阵,注意这些函数返回操作后的结果,而不会对原矩阵的元素进行直接操作,如果要让原矩阵的进行转换,则需要使用响应的InPlace函数,例如:transposeInPlace() 、 adjointInPlace() 之类。
还有必须要注意的是,虽然adjoint是伴随的意思,但是在这里并不是求伴随矩阵,有兴趣的可以看这个http://blog.csdn.net/masibuaa/article/details/8121298
adjoint()的定义如下(注意看警告部分)
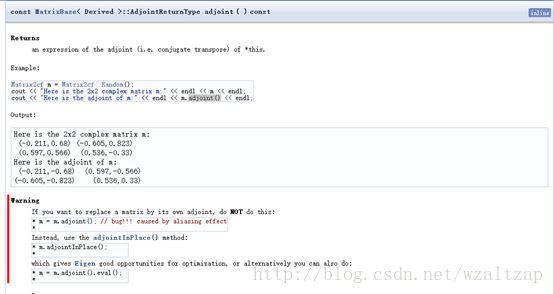
5. 点乘和内积

dot()的定义如下

注意,只能由于向量,而且当是复数向量时,计算的是(a^H)*(a)
至于value()的定义如下,但是有什么作用现在还不知道

6. 外积

7. 范数和归一化

1) norm()的定义如下

对于向量,使用的是L2范数,也就是向量本身点积的开方
对于矩阵,使用的是Frobenius范数
2) normalized()的定义如下:

这个是针对于向量的。用处就是向量的每个数除以这个向量的范数
3) normalize()的定义如下:

作用和normalized()是一样的,区别在于,normalized()是产生一个临时矩阵,而这个是直接对原矩阵进行变换。
4) squaredNorm()的定义如下

和前面的norm()的区别就是,在norm()的结果上做了一个平方
8. 叉积
![]()
cross()的定义如下
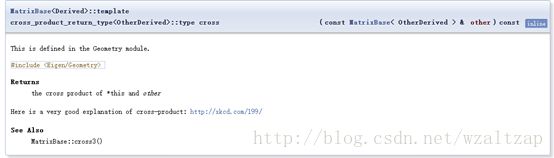
至于叉积和外积有什么区别,自己去找,懒得解释了
四、Coefficient-wise & Array operators
1. 矩阵和向量的系数操作
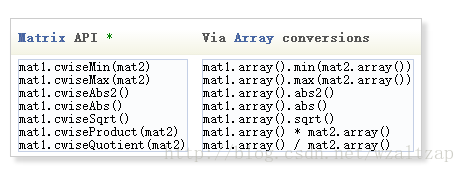
1) cwiseMin()的定义如下

就是输出相同位置的两个矩阵中较小的系数所组成的矩阵
2) cwiseMax()的定义如下

跟上面的一样,只是较小换成了较大
3) cwiseAbs2()的定义如下
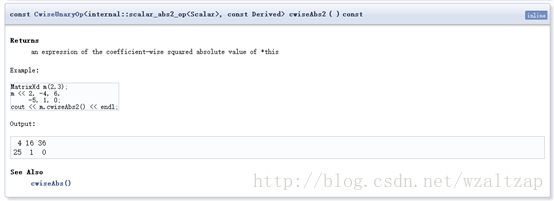
就是求各个系数绝对值的平方
4) cwiseAbs()的定义如下

就是求各个系数的绝对值
5) cwiseSqrt()的定义如下

就是求各个系数的开方
6) cwiseProduct()的定义如下

就是输出相同位置的两个矩阵中各个系数的乘积所组成的矩阵
7) cwiseQuotient()的定义如下
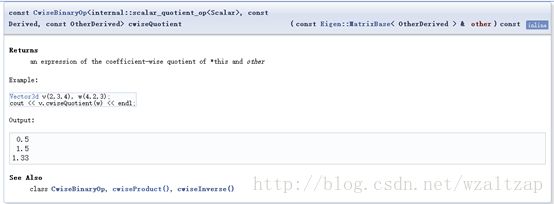
比如v.cwiseQuotient(w),那么就是v中的各个系数分别除以w中的相对应位置的系数的结果
2. 数组操作
这一部分一般不是重点,所以这里就不详细展开了

上面要注意一个地方,就是Matrix类是没有<,>,<=,>=,==,!=这些操作的,如果想进行这些操作,可以通过array()来转换成数组表示
五、Reduction
Eigen提供了很多的降维方法,比如minCoeff(), maxCoeff() , sum() , prod() , trace() , norm() , squaredNorm() , all() , any()。所有的这些降维操作都可以对矩阵的系数,column-wise,row-wise进行。
1. 先说明一下VectorwiseOp,下面是这个的说明

这是一个伪表达式,提供了局部降维操作,有两个参数:
ExpressionType:局部降维的目标类型
Direction:表示进行的方向(垂直或者水平)
他是DenseBase::colwise()和DenseBase::rowwise()的返回类型,而且大部分情况下只有这两种方式
1) colwise()的定义如下

其实也就是可以理解为取出每一列。但是,这里要注意,colwise()是把每一列变成了一个块,然后这些块组成了一个行向量,所以这时候你是不能将这些块进行输出或者对矩阵中的某一个元素进行赋值的。
2) rowwise()的定义如下

其实也就是可以理解为取出每一行,需要注意的地方和上面是一样的
2. 下面对每一个降维操作进行讲解
1) minCoeff()的定义如下

这是第一种定义,可以对矩阵和向量操作,直接返回最小值

这是第二种定义,可以对矩阵和向量操作,返回最小值,同时将最小值所在的行数和列数保存到调用时输入的两个地址指向的内存中

这是第三种定义,只能对向量操作,返回最小值,同时将最小值所在的位置保存到调用时输入的地址指向的内存中
例子:


2) maxCoeff()的定义如下

和minCoeff()一样
3) sum()的定义如下

返回所有系数的和
4) prod()的定义如下

返回所有系数的积
5) trace()的定义如下

返回矩阵的迹,不一定要是方阵
6) norm() ,squaredNorm()前面已经讲过
7) all()的定义如下

就如字面意思一样,要所有的系数都满足条件才行
8) any()的定义如下

就如字面意思一样,只要有一个系数满足条件就行
例子

六、Sub-matrices
1. 矩阵的行和列的读写访问

1) col()的定义如下

就是取出矩阵中的第i列,要注意和cols()的区别
2) row()的定义如下

就是取出矩阵中的第i行,要注意和rows()的区别
3) swap()的定义如下

就是交换,注意是交换,两个矩阵都会发生变化
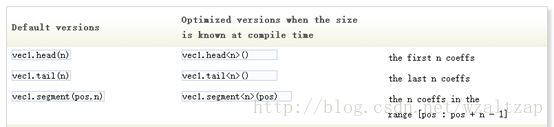
2. 向量子块的读写访问
3. 矩阵子块的读写访问

1) block()的定义如下

注意,这个函数返回的是一个动态矩阵
2) block

注意,这个函数返回的是一个静态矩阵
3) topLeftCorner()的定义如下

取左上角的矩阵,返回的是一个动态矩阵

返回一个静态矩阵

这个其实和第一个是差不多的,区别就是可以选择一个参数静态的而另外一个是动态的
4) topRightCorner()是右上角,bottomLeftCorner()是左下角,bottomRightCorner()是右下角,具体的定义都和topLeftCorner()差不多
5) topRows()的定义如下

就是从第一行开始,取n行,返回的是一个动态矩阵

注意,这里当N时固定数值时,n必须等于N,或者不写,这时候返回的是一个静态矩阵
当N是Dynamic时,n需要写好,表示取几行,返回的是一个行数是动态,列数是静态的矩阵
6) bottomRows()是从底部行取,leftCols()是从左边列取, rightCols()是从右边列取,具体的定义都和 topRows()差不多
七、Miscellaneous operations
1. Reverse
向量,矩阵的行或者列或者整个矩阵都可以倒置

1) reverse()的定义如下
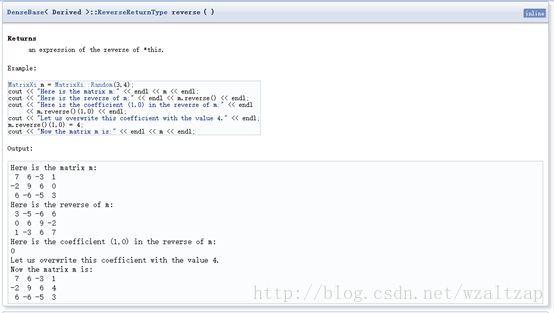
就是数据倒置过来
2) reverseInPlace()的定义如下

这个跟前面的那个作用是一样的,区别是直接在原矩阵上进行操作,这个定义里面也讲了这样做的意义。
2. Replicate

注意,这个例子中的第一行的两个定义是错误的
replicate()的定义如下

这是第一个,返回的是一个动态矩阵

这是第二个,返回的是一个静态矩阵
这两个的作用都是将矩阵或者向量看成是一块,然后按照参数进行复制

这是第三个,和前两个的区别是,这个只有一个参数,就是将向量进行复制,列向量就复制成多列(横向复制),可以向定义中的例子里的一样,使用v.rowwise().replicate(5),也可以使用v.rowwise().replicate<5>()。但是这里要注意,一定要使用rowwise(),这就是为什么之前的例子的第一行是错误的原因
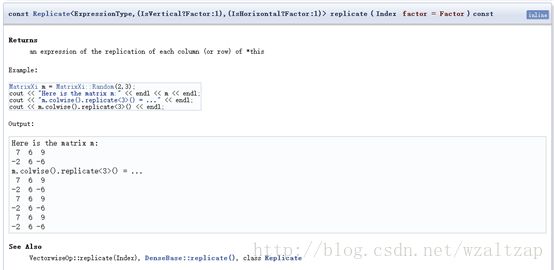
这是第4个,和上面那个的区别就是这是对矩阵进行操作,同样先通过colwise()将每一列变成了一个块,这些块组成了行向量(这样就跟上面类似了),然后进行复制(纵向复制);或者通过rowwise()将每一行变成一个块,这些块组成了列向量,然后进行复制(横向复制)。可以向定义中的例子里的一样,使用m.colwise().replicate<3>(),也可以使用m.colwise().replicate (3)。
八、Diagonal, Triangular, and Self-adjoint matrices
1. Diagonalmatrices

1) asDiagonal()的定义如下

这个函数是针对向量的,是将向量的系数作为对角矩阵对角线上的值
2) DiagonalMatrix类的定义如下

_Scalar:是系数类型
SizeAtCompileTime:矩阵的维数,可以是Dynamic
MaxSizeAtCompileTime:这个参数是最优的或者默认和SizeAtCompileTime一样。大部分情况下不用理他。
注意例子中使用了一个向量来对对角矩阵进行赋值。
3) diagonal()的定义如下

这个就是取出主对角线上的系数,并不一定要求矩阵为方阵
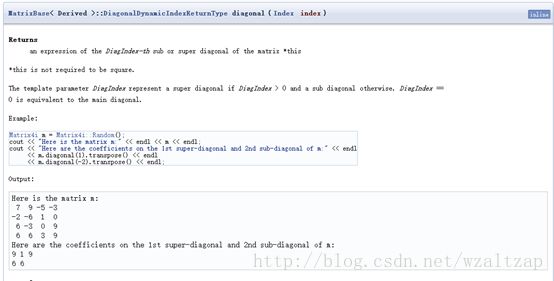
这个就是以主对角线为基准0,当参数为正数,对角线向上移,当参数为负数时,对角线向下移。
4) 最后一个例子只是简单的运算,这里不展开,主要说一个求逆函数,这个函数是很重要的,但是前面一直没有提到
inverse()的定义如下

2. Triangularviews和Symmetric/selfadjoint views
这两部分有些麻烦,就不展开了,等以后用到的话再提
九、Fast Fourier Transform module
FFT的实现并不是Eigen中自带的库,而是采用外部的模块,即unsupported module。
所以我们需要首先包含这个文件,即#include
这个模块提供了FFT,通过一个可配置后端实现。
默认的实现方式是基于kissfft的,这是一个小的,免费的,可靠有效的
还有两种实现后端:
l fftw(http://www.fftw.org):更快的
l MKL (http://en.wikipedia.org/wiki/Math_Kernel_Library):最快的,商业的
十、特征分解
很麻烦,懒得讲了
http://eigen.tuxfamily.org/dox/classEigen_1_1EigenSolver.html
http://eigen.tuxfamily.org/dox/classEigen_1_1ComplexEigenSolver.html
十一、奇异值分解
http://eigen.tuxfamily.org/dox/classEigen_1_1JacobiSVD.html很麻烦,懒得讲了