Go进阶之路——复杂类型
指针
Go 具有指针。 指针保存了变量的内存地址。
类型 *T 是指向类型 T 的值的指针。其零值是 `nil`。
var p *int& 符号会生成一个指向其作用对象的指针。
i := 42
p = &i* 符号表示指针指向的底层的值。
fmt.Println(*p) // 通过指针 p 读取 i
*p = 21 // 通过指针 p 设置 i这也就是通常所说的“间接引用”或“非直接引用”。
与 C 不同,Go 没有指针运算。
例子:
package main
import "fmt"
func main() {
i, j := 42, 2701
p := &i // point to i
fmt.Println(*p) // read i through the pointer
*p = 21 // set i through the pointer
fmt.Println(i) // see the new value of i
p = &j // point to j
*p = *p / 37 // divide j through the pointer
fmt.Println(j) // see the new value of j
}结构体
一个结构体(`struct`)就是一个字段的集合。可用于表示不同数据类型的集合。
结构体是由零个或多个任意类型的值聚合成的实体。
(而 type 的含义跟其字面意思相符。)
package main
import "fmt"
type Vertex struct {
X int
Y int
}
func main() {
fmt.Println(Vertex{1, 2})
}
结构体字段使用点号来访问。
package main
import "fmt"
type Vertex struct {
X int
Y int
}
func main() {
v := Vertex{1, 2}
v.X = 4
fmt.Println(v.X)
}结构体字段也可以通过结构体指针来访问。
ps:官方对此提到一句“通过指针间接的访问是透明的”,对此句中的“透明的”暂不知该如何解释,网上暂时也没找到解释。我最初误会以为可以通过指针访问私有变量,但经过尝试,事实并不可以。
结构体文法
结构体文法表示通过结构体字段的值作为列表来新分配一个结构体。
使用 Name: 语法可以仅列出部分字段。(字段名的顺序无关。)
特殊的前缀 & 返回一个指向结构体的指针。
package main
import "fmt"
type Vertex struct {
X, Y int
}
var (
v1 = Vertex{1, 2} // 类型为 Vertex
v2 = Vertex{X: 1} // Y:0 被省略
v3 = Vertex{} // X:0 和 Y:0
p = &Vertex{1, 2} // 类型为 *Vertex
)
func main() {
fmt.Println(v1, p, v2, v3)
}
输出结果:
![]()
结构体内嵌匿名成员
声明一个成员对应的数据类型而不指名成员的名字;这类成员就叫匿名成员。
package main
import "fmt"
type Person struct {
Age int
Name string
}
type Student struct {
Person
}
func main() {
per := Person{
Age: 18,
Name: "name",
}
stu := Student{Person: per}
fmt.Println("stu.Age: ", stu.Age)
fmt.Println("stu.Name: ", stu.Name)
}Go的面向对象中通常用匿名成员实现继承。
数组
- 定义:由若干相同类型的元素组成的序列
- 数组的长度是固定的,声明后无法改变
- 数组的长度是数组类型的一部分,eg:元素类型相同但是长度不同的两个数组是不同类型的
- 需要严格控制程序所使用内存时,数组十分有用,因为其长度固定,避免了内存二次分配操作
类型 [n]T 是一个有 n 个类型为 T 的值的数组。
表达式
var a [10]int定义变量 a 是一个有十个整数的数组。
package main
import "fmt"
func main() {
// 定义长度为 5 的数组
var arr1 [5]int
for i := 0; i < 5; i++ {
arr1[i] = i
}
printHelper("arr1", arr1)
// 以下赋值会报类型不匹配错误,因为数组长度是数组类型的一部分
// arr1 = [3]int{1, 2, 3}
arr1 = [5]int{2, 3, 4, 5, 6} // 长度和元素类型都相同,可以正确赋值
// 简写模式,在定义的同时给出了赋值
arr2 := [5]int{0, 1, 2, 3, 4}
printHelper("arr2", arr2)
// 数组元素类型相同并且数组长度相等的情况下,数组可以进行比较
fmt.Println(arr1 == arr2)
// 也可以不显式定义数组长度,由编译器完成长度计算
var arr3 = [...]int{0, 1, 2, 3, 4}
printHelper("arr3", arr3)
// 定义前四个元素为默认值 0,最后一个元素为 -1
var arr4 = [...]int{4: -1}
printHelper("arr4", arr4)
// 多维数组
var twoD [2][3]int
for i := 0; i < 2; i++ {
for j := 0; j < 3; j++ {
twoD[i][j] = i + j
}
}
fmt.Println("twoD: ", twoD)
}
func printHelper(name string, arr [5]int) {
for i := 0; i < 5; i++ {
fmt.Printf("%v[%v]: %v\n", name, i, arr[i])
}
// len 获取长度
fmt.Printf("len of %v: %v\n", name, len(arr))
// cap 也可以用来获取数组长度
fmt.Printf("cap of %v: %v\n", name, cap(arr))
fmt.Println()
}slice
一个 slice 会指向一个序列的值,并且包含了长度信息。
[]T 是一个元素类型为 T 的 slice。
切片组成要素:
- 指针:指向底层数组
- 长度:切片中元素的长度,不能大于容量
- 容量:指针所指向的底层数组的总容量
常见初始化方式
- 使用
make初始化
slice := make([]int, 5) // 初始化长度和容量都为 5 的切片
slice := make([]int, 5, 10) // 初始化长度为 5, 容量为 10 的切片- 使用简短定义
slice := []int{1, 2, 3, 4, 5}注意:与数组的隐式长度定义是有区别
package main
import "fmt"
func main() {
var arr = [5]int{0, 1, 2, 3, 4}
var arr1 = [...]int{0, 1, 2, 3, 4}
var arr2 = []int{0, 1, 2, 3, 4}
fmt.Printf("%T(%v)\n",arr,arr)
fmt.Printf("%T(%v)\n",arr1,arr1)
fmt.Printf("%T(%v)\n",arr2,arr2)
}输出结果:

- 使用数组来初始化切片
arr := [5]int{1, 2, 3, 4, 5}
slice := arr[0:3] // 左闭右开区间,最终切片为 [1,2,3]- 使用切片来初始化切片
sliceA := []int{1, 2, 3, 4, 5}
sliceB := sliceA[0:3] // 左闭右开区间,sliceB 最终为 [1,2,3]长度和容量
package main
import (
"fmt"
)
func main() {
slice := []int{1, 2, 3, 4, 5}
fmt.Println("len: ", len(slice))//len()获得长度
fmt.Println("cap: ", cap(slice))//len()获得容量
//改变切片长度
slice = append(slice, 6)
fmt.Println("after append operation: ")
fmt.Println("len: ", len(slice))
fmt.Println("cap: ", cap(slice)) //注意,底层数组容量不够时,会重新分配数组空间,通常为两倍
}输出结果:
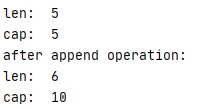
注意:底层数组容量不够时,会重新分配数组空间,通常为两倍,返回的 slice 会指向这个新分配的数组。
func append(s []T, vs ...T) []Tappend 的第一个参数 s 是一个类型为 T 的数组,其余类型为 T 的值将会添加到 slice。
append 的结果是一个包含原 slice 所有元素加上新添加的元素的 slice。
多个切片共享一个底层数组时,对底层数组的修改,将影响上层多个切片的值
package main
import (
"fmt"
)
func main() {
slice := []int{1, 2, 3, 4, 5}
newSlice := slice[0:3]
fmt.Println("before modifying underlying array:")
fmt.Println("slice: ", slice)
fmt.Println("newSlice: ", newSlice)
fmt.Println()
newSlice[0] = 6
fmt.Println("after modifying underlying array:")
fmt.Println("slice: ", slice)
fmt.Println("newSlice: ", newSlice)
}输出结果:

使用 copy 方法可以避免共享同一个底层数组
package main
import (
"fmt"
)
func main() {
slice := []int{1, 2, 3, 4, 5}
newSlice := make([]int, len(slice))
copy(newSlice, slice)
fmt.Println("before modifying underlying array:")
fmt.Println("slice: ", slice)
fmt.Println("newSlice: ", newSlice)
fmt.Println()
newSlice[0] = 6
fmt.Println("after modifying underlying array:")
fmt.Println("slice: ", slice)
fmt.Println("newSlice: ", newSlice)
}输出结果:

slice 的零值是 `nil`。一个 nil 的 slice 的长度和容量是 0。
package main
import "fmt"
func main() {
var z []int
fmt.Println(z, len(z), cap(z))
if z == nil {
fmt.Println("nil!")
}
}输出结果:
![]()
Go 中切片扩容的策略是这样的(https://halfrost.com/go_slice/):
- 首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)
- 否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap)
- 否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的 1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
- 如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)
map
在 Go 语言里面,map 一种无序的键值对, 它是数据结构 hash 表的一种实现方式,类似 Python 中的字典。
map 在使用之前必须用 make 而不是 new 来创建;值为 nil 的 map 是空的,并且不能赋值。
使用关键字 map 来声明形如:
map[KeyType]ValueType
注意点:
- 必须指定 key, value 的类型,插入的纪录类型必须匹配。
- key 具有唯一性,插入纪录的 key 不能重复。
- KeyType 可以为基础数据类型(例如 bool, 数字类型,字符串), 不能为数组,切片,map,它的取值必须是能够使用
==进行比较。 - ValueType 可以为任意类型。
- 无序性。
- 线程不安全, 一个 goroutine 在对 map 进行写的时候,另外的 goroutine 不能进行读和写操作,Go 1.6 版本以后会抛出 runtime 错误信息。
package main
import "fmt"
type Vertex struct {
Lat, Long float64
}
var m map[string]Vertex
func main() {
m = make(map[string]Vertex)
m["Bell Labs"] = Vertex{
40.68433, -74.39967,
}
fmt.Println(m["Bell Labs"])
}声明和初始化
- 使用 var 声明
var cMap map[string]int // 只定义, 此时 cMap 为 nil
fmt.Println(cMap == nil)
cMap["北京"] = 1 // 报错,因为 cMap 为 nil- 使用
make
cMap := make(map[string]int)
cMap["北京"] = 1
// 指定初始容量
cMap = make(map[string]int, 100)
cMap["北京"] = 1
说明:在使用 make 初始化 map 的时候,可以指定初始容量,这在能预估 map key 数量的情况下,减少动态分配的次数,从而提升性能。
- 简短声明方式
cMap := map[string]int{"北京": 1}基本操作:
package main
import "fmt"
func main() {
cMap := map[string]int{}
cMap["北京"] = 1 //写
code := cMap["北京"] // 读
fmt.Println(code)
code = cMap["广州"] // 读不存在 key
fmt.Println(code)
code, ok := cMap["广州"] // 检查 key 是否存在
if ok {
fmt.Println(code)
} else {
fmt.Println("key not exist")
}
delete(cMap, "北京") // 删除 key
fmt.Println(cMap["北京"])
}输出结果:

如果 key 在 cMap中,`ok` 为 true,code为对应的value 。否则, ok 为 `false`,并且 code 是 map 的元素类型的零值。
循环和无序性
package main
import "fmt"
func main() {
cMap := map[string]int{"北京": 1, "上海": 2, "广州": 3, "深圳": 4}
for city, code := range cMap {
fmt.Printf("%s:%d", city, code)
fmt.Println()
}
}第一次输出结果:

第二次输出结果:

map 嵌套
provinces := make(map[string]map[string]int)
provinces["北京"] = map[string]int{
"东城区": 1,
"西城区": 2,
"朝阳区": 3,
"海淀区": 4,
}
fmt.Println(provinces["北京"])一个小练习:
实现 `WordCount`。它应当返回一个含有 s 中每个 “词” 个数的 map。
package main
import (
"fmt"
"strings"
)
func WordCount(s string) map[string]int{
rs := map[string]int{}
s = strings.ToLower(s) //小写格式化
s = strings.Replace(s,".","",-1)//去除所有"."
s = strings.Replace(s,",","",-1)//去除所有","
words := strings.Fields(s)
for _,v := range words{
item,ok := rs[v]
if ok {
rs[v] = item+1
} else {
rs[v] = 1
}
}
return rs
}
func main() {
s :="A boy lives near my house and I never know his name. Every day, he will bring some " +
"food to the homeless dogs and cats. Sometimes when I am passing through, I see what " +
"he does. He is so kind that I decide to make friends with him. He is talkative and " +
"have a lot of funny things to share. What a lovely boy."
m := WordCount(s)
//for word,count := range m{
// fmt.Println(word,":",count)
//}
fmt.Println(m)
}输出结果:

用循环输出的话,结果是无序的。
自定义类型
在 Go 语言里面,还可以通过自定义类型来表示一些特殊的数据结构和业务逻辑。
使用关键字 type 来声明:
type NAME TYPE声明语法
- 单次声明
type City string
- 批量声明
type (
B0 = int8
B1 = int16
B2 = int32
B3 = int64
)
type (
A0 int8
A1 int16
A2 int32
A3 int64
)简单示例
package main
import (
"fmt"
"time"
)
type (
Country string
Year int
)
func main() {
country := Country("China")
fmt.Println("I'm come from " + country)//字符串拼接
fmt.Println(len(country))
t := time.Now()
year := Year(2020)
thisYear := Year(t.Year())
if year == thisYear {
fmt.Println("This year is ",year)
}
}自定义类型对应原始类型的所有操作其同样适用。
注意:自定义类型与其对应原始类型是不同的类型,故thisYear := Year(t.Year())需要显示类型转换(t.Year()返回int值,year == thisYear该比较两个变量类型需一致)
package main
import "fmt"
type Age int
type Height int
func main() {
age := Age(12)
height := Height(175)
fmt.Println(height / age)
}运行如上代码会出现./main.go:12:21: invalid operation: height / age (mismatched types Height and Age)错误,修复方法使用显式转换:
fmt.Println(int(height) / int(age))