title: DALS002-统计推断(Inference)01-概率分布
date: 2019-07-22 12:0:00
type: "tags"
tags:
- 统计推断
categories: - 生物统计
前言
这篇笔记是《Data Analysis for the Life Sciences》的第2章,统计推断(Inference)。这一部分的主要内容涉及p值,置信区间(confidence intervals)。
先来看一篇文献,文献信息如下所示:
Winzell, M. S. and B. Ahren (2004). "The high-fat diet-fed mouse: a model for studying mechanisms and treatment of impaired glucose tolerance and type 2 diabetes." Diabetes 53 Suppl 3: S215-219.
这篇文献的摘要部分有这么一句话:
Body weight was higher in mice fed the high-fat diet already after the first week, due
to higher dietary intake in combination with lower metabolic efficiency.
上面摘要的这句话的意思是,饲喂高脂饮料的小鼠,在前一周内,体重上升,这是由能量摄入较高,外加代谢消耗低导致的。
为了支持这种结论,作者在结果部分提到了这些话:
Already during the first week after introduction of high-fat diet, body weight increased
significantly more in the high-fat diet-fed mice (+1.6± 0.1g) than in the normal diet-
fed mice (+ 0.2±0.1 g; P < 0.001)
当小鼠在第1周内饲喂高脂饮料后,饮喂高脂饲料的小鼠体重的增加 (+1.6± 0.1g) 明显高于普通饲料饲喂的小鼠体重增加(+0.2±0.1g; P < 0.001)。
这里面有几个地方需要注意,第一就是P<0.001。第二就是±。
要了解这两个内容,第一步就需要理解随机变量(random variables),这里使用作者在Github上提供的原始数据来计算,在第1篇笔记中已经提到,导入数据如下所示:
filename <- file.path(dir,"extdata/femaleMiceWeights.csv")
dat <- read.csv(filename)
我们先要来研究一个问题:给小鼠特定的饲料,几周后小鼠的体重是否会增加?现在我们从Jackson实验室(Jackson实验室是全球最大的实验小鼠供应商)购买了24只小鼠,随机分布它们吃正常的饲料(chow)和高脂饲料(hf, high fat),几周后,研究人员称量小鼠的体重,获取数据如下所示:
> head(dat)
Diet Bodyweight
1 chow 21.51
2 chow 28.14
3 chow 24.04
4 chow 23.45
5 chow 23.68
6 chow 19.79
现在问题来了,饲喂高脂饲料(hf)的小鼠体重是否更重?从数据中我们可以知道,在hf组,编号24的小鼠体重是20.73g,它是最轻的小鼠,但是编号21的小鼠是34.02g,它是最重的小鼠,但是它们吃的都是高脂饲料,无法比较。此时,我们把这些小鼠体重的变化称为变异(variability)。
再回到那篇文献,那篇文献下结论的时候,指的变量就是小鼠体重的平均变化,现在我们计算每组小鼠的平均变化,如下所示:
library(dplyr)
control <- filter(dat, Diet == "chow") %>% select(Bodyweight) %>% unlist
treatment <- filter(dat, Diet == "hf") %>% select(Bodyweight) %>% unlist
print(mean(treatment))
print(mean(control))
obsdiff <- mean(treatment) - mean(control)
obsdiff
结果如下所示:
> print(mean(treatment))
[1] 26.83417
> print(mean(control))
[1] 23.81333
> obsdiff <- mean(treatment) - mean(control)
> obsdiff
[1] 3.020833
从结果中我们可以发现,hf组小鼠的平均体重大概高于chow组小鼠平均体重的10%。为什么在这个地方我们不能下确定的结论,还需要一个p值(p-value)与置信区间(confidence intervals)?
这是因为这些均数数是随机变量,如果我们再重复一次实验,也就是说,我们再从Jackson实验室购买24只小鼠,随机将它们分为2组,一组hf,一组chow,我们还会得到一个不同的平均值。每重复一次,都会得到一个平均值,我们称这样的数据为随机变量(random variable)。
随机变量(random variable)
现在我们进一步研究随机变量。试想,我们能够获取所有对照组小鼠的体重,把它们都放在R中计算,从统计学角度来说,这个所有的对照组小鼠的体重就是总体(population),我们可以从这个总体中随机抽取24只小鼠,事实上来说,我们不可能拿到总体,因为太大了,不过我们可以模拟这个思路,现在下载这个数据,如下所示:
dir <- system.file(package = "dagdata")
filename <- file.path(dir,"extdata/femaleControlsPopulation.csv")
population <- read.csv(filename)
population <- unlist(population) # turn it into a numeric
现在我们随机从总体(population)中抽取12个样本,如下所示:
control <- sample(population, 12)
mean(control)
control <- sample(population, 12)
mean(control)
control <- sample(population, 12)
mean(control)
运行结果如下所示:
> control <- sample(population, 12)
> mean(control)
[1] 23.33917
> control <- sample(population, 12)
> mean(control)
[1] 23.53917
> control <- sample(population, 12)
> mean(control)
[1] 24.18167
现在我们可以发现,每次抽取的时候,平均都发生了变化,我们可以一直这么重复的抽样下去,然后就能了解随机变量的分布。
零假设(Null Hypothesis)
现在我们再回到前面的那个hf组与chow组小鼠平均体重差值的变量obsdiff上来。众所周知,科学家都有怀疑精神,我们做了一次实验,我们如何知道obsdiff这个是由饮食造成的呢?如果我们给这2组小鼠都喂同样的饲料,结果会是什么呢?万一obsdiff这个值更大咋办?统计学家们就把这种情况称为零假设(Null Hypothesis)。这个零(null)指的就是怀疑的方向:我认为这2组小鼠的体重没有差异的可能性(possibility)有多大(credence)。(注:原话是:we give credence to the possibility that there is no difference)。
因为我们假设了我们能够获得总体,我们实际上可能尽可能多地观察到,当饲料没对体重没有影响时的差值。现在我们假设随机取了24只对照小鼠,把它们分为2组,也就是每组12只,现在我们观察一下它们平均体重值的差值,如下所示:
control <- sample(population, 12) # control mice
treatment <- sample(population, 12)
# We assume high diet have no effect on weight
print(mean(treatment) - mean(control))
结果如下所示:
> print(mean(treatment) - mean(control))
[1] 0.2275
现在我们重复这个过程1万次(最好不要使用for循环,这里可以使用replicate()函数),如下所示:
n <- 10000
null <- vector("numeric", n)
for (i in 1:n){
control <- sample(population, 12)
treatment <- sample(population, 12)
null[i] <- mean(treatment) - mean(control)
}
其中变量null就是我们称的零分布(null distribution),它里面有10000个差值,现在我们来计算一下,这里面的10000个差值与前面obsdiff的比较(原来过计算的obsdiff为3.020833),看一下大于原来的3.020833这个数字的比例有多大,如下所示:
mean(null >= 3.020833)
如下所示:
> mean(null >= 3.020833)
[1] 0.013
这个比例是0.013,也就是1.3%,也就是说,假设饲料对小鼠的体重没有影响,我们重复1万次实验,只有1.3%的比例,也就是说只有130次实验能说明“饲料对小鼠的体重没影响”这个结论,另外9870次我们都得不出这个结论,因此,即使作为怀疑性极强的科学们家,也只能说,当饲料对体重没有影响时,我们只能看到1.3%的的可能性。这就是p值。
下面是通过replicate()函数来实现上述过程,如下所示:
null_f <- function(x){
control <- sample(x, 12)
treatment <- sample(x, 12)
null <- mean(treatment) - mean(control)
return(null)
}
null_result <- replicate(n, null_f(population))
mean(null_result>=3.020833)
结果如下所示:
> mean(null_result>=3.020833)
[1] 0.0123
1.23%。
分布(distributions)
分布简单来说就是,对大量数据的精简描述,例如你测量了一个总体中的所有男性的身高,现在你需要把这些数据向一个外星人描述,而这个外星人从来没到过地球,数据如下所示:
library(UsingR)
x <- father.son$fheight
注:这个包UsingR是《Using R for Introductory Statistics》 Second Edition的数据。其中father.son这个数据集含有的是父亲的身高与儿子的身高(单位是英寸),用于研究Pearson相关系数。
现在向外星人描述比较简单的方法就是把它们都列出来,现在我们随机选择10个数据,如下所示:
round(sample(x,10),10)
如下所示:
> round(sample(x,10),10)
[1] 65.25267 62.41134 68.83427 66.69404 65.98544 69.60692 71.96564 68.11283 67.93353
[10] 67.41537
累积分布函数(Cumulative Distribution Function, CDF)
通过查看这些数字,我们了解一个大概,但是非常低效。但是我们可以通过一个分布曲线(distribution)来画一下这些数据,现在我们定义一下分布,先取一个值a,小于a值的数字的比例,就是分布,如下所示:
这个函数叫累积分布函数(CDF),当CDF来源于一个数据集中,而不是理论值时,我们就称它为经验累积分布函数(empirical CDF, ECDF),我们可以画出这个分布曲线,如下所示:
smallest <- floor(min(x))
largest <- ceiling(max(x))
values <- seq(smallest, largest, len=300)
heightecdf <- ecdf(x)
plot(values, heightecdf(values), type="l",
xlab="a(Height in inches)", ylab="Pr(x <= a)")
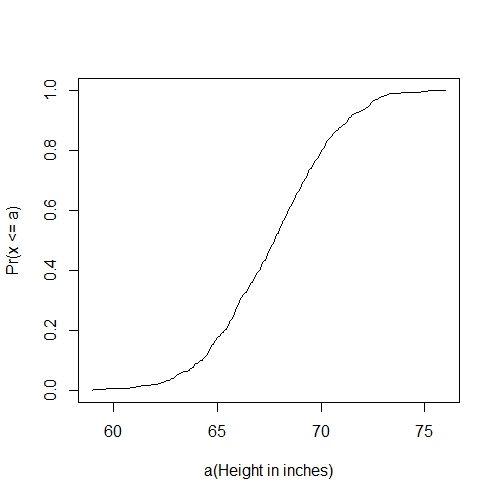
直方图(Histograms)
ecdf这个函数在R中并不常用,现在我们使用区间的形式来给出间内的比例,如下所示:
使用直方图更加直观,因为我们多数感兴趣的是某个区间的高度,例如70到71这个区间的比例,而很少会去看低于70这个比例,直方图如下所示:
hist(x)

可以对这个直方图做进一步的修饰,如下所示:
bins <- seq(smallest, largest)
hist(x, breaks=bins, xlab="Height(in inches)", main="Adlt men heights")
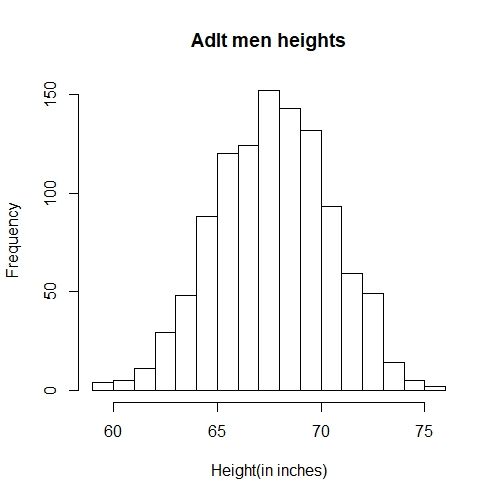
这种图比纯列数字更加直观,从图上我们大致就能判断出高于72英寸的人大概有70个人。
概率分布(Probability Distribution)
分布的一个更加重要的功能是用于描述一个随机变量的可能结果。与一组固定的数据不同,我们实际上无法观测到随机变量的所有可能结果,因此,我们在这种情况下,不描述比例(proportions),而是用于描述概率(probabilities)。例如,当我们从上面的那组身高数据中取机挑一个数字,它落在a与b区间内的概率就可以用下面的公式表示:
上面公式中的X表示随机变量,这个公式定义了随机变量的概率分布。例如,在这种情况下,如果我们知道了零假设下的小鼠体重均值的差值分布是真的,那么,我们就能在这个分布上找到与我们实验中计算出的值对应值的概率,也就是p值。
在前面的案例中,我们计算了10000个零假设下的随机变量概率分布(这种重复抽样的方法叫蒙特卡罗法,Monte Carlo),现在我们再重复一次,不过这次有所不同,在每重复做一次实验,我们就把这个点添加到图片上,如下所示:
library(rafalib)
n <- 100
nullplot(-5, 5, 1, 30, xlab="Observed differences(grams)", ylab="Frequencey")
totals <- vector("numeric",11)
for (i in 1:n){
control <- sample(population, 12)
treatment <- sample(population, 12)
nulldiff <- mean(treatment) - mean(control)
j <- pmax(pmin(round(nulldiff)+6, 11),1)
totals[j] <- totals[j]+1
text(j-6, totals[j], pch=15, round(nulldiff,1),cex=1)
if(i <15) Sys.sleep(1) # See values appear slowly
}

上面的图其实就是一个直方图,obsdiff最初的值是3.020833,从上面的图我们可以知道,与这个值接近的数字很少。
从前面我们计算的null可以看出来,如下所示:
hist(null, freq=TRUE)
abline(v=obsdiff, col="red", lwd=2)
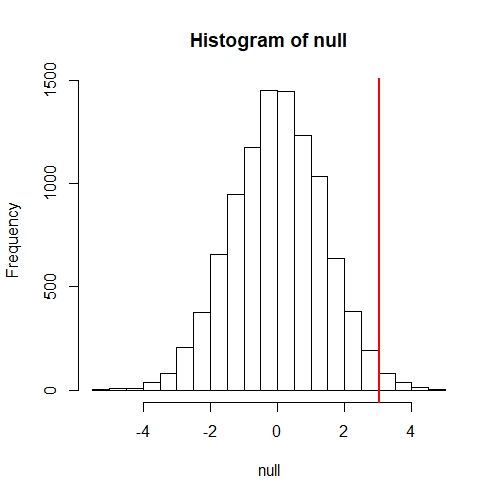
上面是我们手动计算Pr(a)的过程,但多数情况下,一些分布的Pr(a)公式都是已知的,例如正态分布。
正态分布(Normal Distribution)
正态分布是最常见的分布之一,normal就是正常,常见的意思,它的公式如下所示:
在R的pnorm()函数中,a通常是负无穷,b则是你要计算的参数,另外,要计算区间的概率,还需要两个参数,分别是均值与标准差,即pnomr(x, mu, sigma),这个公式计算的就是小于x的这值的概率,现在回到前面的obsdiff(3.020833)这个变量上来,我们计算一下:
1 - pnorm(obsdiff, mean(null),sd(null))
如下所示:
> 1 - pnorm(obsdiff, mean(null),sd(null))
[1] 0.01377017
小结
计算hf组与chow组小鼠的体重差异的p值是非常简单的。为了做这个计算,我们可以买来所有的小鼠,来重复的计算,找到零假设,但是不现实,因此我们要使用统计推断(Statistical Inference)的思想,这种思想可以允许我们使用少量的样本,例如24只小鼠就能得到一个相对靠谱的结论。
练习
原书P37