1 | Spinnaker: Agent 缓存云厂商各项数据流程分析

在 clouddriver 中缓存云厂商的各项数据,是由这些 agent 所来完成。本文主要聚焦于何时执行、如何存储、以及存储后如何使用这三点上。
Agent 从哪里来
创建 agent
为每个云账号的每个区域创建10个不同类型的 agent

安排启动
ProviderUtils.rescheduleAgents()

上面的 agentScheduler 的实现类为 com.netflix.spinnaker.cats.redis.cluster.ClusteredAgentScheduler,具体操作就是将待添加的 100 个 agents 全部放到其中的 map 中,并以 accountName+region+className 作为 key。
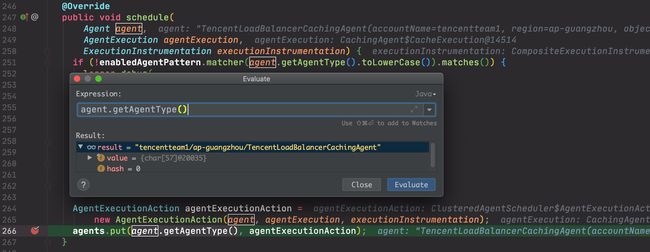
到此时,已经把新增的 agents 全部安排好了。
为什么加入到 agents 这个 map 中,agent 就能跑起来
首先,ClusteredAgentScheduler 实现类 Runnable
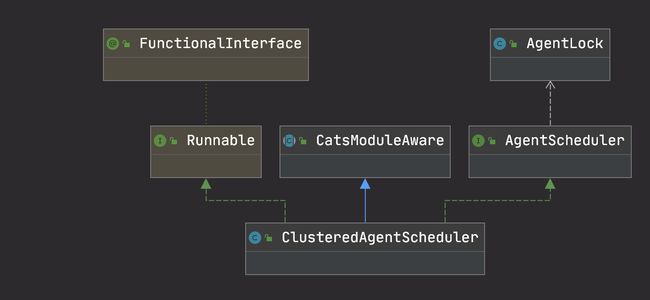
并且,在其实现的 run 方法中,会将所有的 agents 封装成一个 Runnable,然后丢到 agentExecutionPool 中执行。
@Override
public void run() {
try {
runAgents();
}//....
}
private void runAgents() {
Map<String, NextAttempt> thisRun = acquire();
activeAgents.putAll(thisRun);
for (final Map.Entry<String, NextAttempt> toRun : thisRun.entrySet()) {
final AgentExecutionAction exec = agents.get(toRun.getKey());
agentExecutionPool.submit(new AgentJob(toRun.getValue(), exec, this));
}
}
ClusteredAgentScheduler 的 run 方法何时调用
首先 ClusteredAgentScheduler 作为一个 Runnable,被加入到一个 ScheduledExecutor 中,并且它的执行周期为 30s。
Executors.newSingleThreadScheduledExecutor(
new NamedThreadFactory(ClusteredAgentScheduler.class.getSimpleName())),
// ...
Integer lockInterval = agentLockAcquisitionIntervalSeconds == null ? 1 : agentLockAcquisitionIntervalSeconds;
lockPollingScheduler.scheduleAtFixedRate(this, 0, lockInterval, TimeUnit.SECONDS);
agentLockAcquisitionIntervalSeconds 最终来源为 yaml 文件中的配置数值

即:

如何执行到 agent 的拉取逻辑
上面的描述,并不是特别直观,执行到 agent 拉取逻辑的调用链路不是特别明显,它的调用链路如下:
- 将 agent 以及 agent 中所产生的 AgentExecution 封装到 AgentExecutionAction 中,也就是前面所述的,将 agent 加入到某个 map 中,只是做了包装。
agentScheduler.schedule(agent, agent.getAgentExecution(catsModule.providerRegistry), catsModule.executionInstrumentation)
// ...
// 其中 agentExecution 最终来自 agent,也就是抽象类 CachingAgent 中的内部类。
AgentExecutionAction agentExecutionAction =
new AgentExecutionAction(agent, agentExecution, executionInstrumentation);
- 将 AgentExecutionAction 包装到 AgentJob,即一个 Runnable 中,并提交到线程池中
final AgentExecutionAction exec = agents.get(toRun.getKey());
agentExecutionPool.submit(new AgentJob(toRun.getValue(), exec, this));
- 在
AgentJob的 run 方法中,执行AgentExecutionAction的execute()方法
private final AgentExecutionAction action;
@Override
public void run() {
Status status = Status.FAILURE;
try {
status = action.execute();
} finally {
scheduler.agentCompleted(
action.getAgent().getAgentType(), lockReleaseTime.getNextTime(status));
}
}
- 在
AgentExecutionAction中执行 agentExecution 的 executeAgent(agent) 方法
Status execute() {
try {
executionInstrumentation.executionStarted(agent);
long startTime = System.nanoTime();
agentExecution.executeAgent(agent);
executionInstrumentation.executionCompleted(
agent, TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startTime));
return Status.SUCCESS;
} catch (Throwable cause) {
executionInstrumentation.executionFailed(agent, cause);
return Status.FAILURE;
}
}
- executeAgent 方法来到 CachingAgent 中,此时的调用栈就相对较清晰,如下
@Override
public void executeAgent(Agent agent) {
AgentIntrospection introspection = new DefaultAgentIntrospection(agent);
CacheResult result = executeAgentWithoutStore(agent); // 此处进入 agent 拉取逻辑
introspection.finish(result);
CacheIntrospectionStore.getStore().recordAgent(introspection);
storeAgentResult(agent, result);
}
public CacheResult executeAgentWithoutStore(Agent agent) {
CachingAgent cachingAgent = (CachingAgent) agent;
ProviderCache cache = providerRegistry.getProviderCache(cachingAgent.getProviderName());
return cachingAgent.loadData(cache); // 调用 agent 的拉取逻辑
}
获取数据
获取数据的入口是函数 loadData(),只负责从云账号拉取信息,并将信息按照一定的形式组装后返回,交给后续的逻辑处理模板进行处理。此处获取数据及组织数据的逻辑,根据 agent 类型的不同,有很大的出入,但是他们的共同点在于,组装所需返回的数据的形式。
以 TencentImageCachingAgent 为例,它有一个函数,实现了某个接口,如下:

这里有两个问题:
- 函数
getProvidedDataTypes()何时调用?用于什么场景?
在存储数据时进行调用,用来获取哪些数据项是可以覆盖更新的。 - 什么是
AgentDataType?有什么用处?
首先它有两个属性,分别为String typeName和Authority authority,在此处 typeName 就是 NAMESPACE 中所对应的云主机所拥有的信息类型,而 authority 有两个值,一个是 AUTHORITATIVE 表示此数据是资源数据,一个是 INFORMATIVE 表示此数据为关联数据(起关联作用)。
typeName 的作用为对应后面存储操作时所需要操作的表等;authority 的作用则如上所述。
最后,loadData() 函数返回的数据,就是以上述 AgentDataType 所包含的值作为 key 的 map。
![]()
存储数据
在这一部分的代码中,逻辑非常多且略带抽象,因为这一部分代码,是所有 agent 拉完数据后,进行存储的统一模板代码,有部分代码处理个别 agent 数据的情况出现。但是化繁为简,它的目的就是做存储,并且此时的存储方式,有两种,资源对应 AUTHORITATIVE;关联数据对应 INFORMATIVE。抛开 agent 的差异,专注到存储的逻辑中,它的逻辑其实也很明了。
存储数据的位置在:CacheingAgent.java 的内部类 CacheExecution 的 executeAgent() 的最后一行,如下:

准备工作
从 storeAgentResult(agent, result) 出发。准备工作其实主要是确定 agent 拉回的数据,哪些是需要存储的,以及用什么样的方式进行存储。

进入 SqlProviderCache.kt 的 putCacheResult 方法。它的代码很长,但是主要根据 agent 数据类型的不同,最终调用两个方法,即:
private fun cacheDataType(type: String, agent: String, items: Collection<CacheData>, authoritative: Boolean, cleanup: Boolean)
private fun cacheDataType(type: String, agent: String, items: Collection<CacheData>, authoritative: Boolean) {
cacheDataType(type, agent, items, authoritative, cleanup = true)
}
本质上是调用同一个方法,也就是第一个方法,只是入参会有所不同。所以 putCacheResult 的主要逻辑可归纳如下:
- 根据 agent 返回数据不同,在 authoritativeTypes 中加入对应类型为资源的数据的 key。
- 如果 agent 返回数据的 key 中含有以 ON_DEMAND.ns,该 key 也加入到 authoritativeTypes 中,也属于资源数据。
- 此时分三种情况:
- 如果 agentType 中含有 ON_DEMAND,那么拉取结果中的 ON_DEMAND.ns 对应的 key 将被视为属于资源数据。
- 如果 authoritativeTypes 不为空,那么拉取结果中,key 为 AUTHORITATIVE 类型的数据,将被视为属于资源数据。
- 非上述两种情况,对拉取结果中所有的数据,直接覆盖更新。
- 对于非 AUTHORITATIVE 类型的数据,将视为属于关联数据。
- 有需要删除的项目,直接删除。
上面便是对此函数的抽象概括,接下来进入实际的存储操作中。按照上面的分析,实际 db 操作包括两种,即增、删。
删除
删除相对比较简单。
override fun evictDeletedItems(type: String, ids: Collection<String>) {
// ...
backingStore.evictAll(type, ids)
// ...
}
override fun evictAll(type: String, ids: Collection<String>) {
// ...
var deletedCount = 0
var opCount = 0
try {
ids.chunked(dynamicConfigService.getConfig(Int::class.java, "sql.cache.read-batch-size", 500)) { chunk ->
withRetry(RetryCategory.WRITE) {
jooq.deleteFrom(table(resourceTableName(type)))
.where("id in (${chunk.joinToString(",") { "'$it'" }})")
.execute()
}
deletedCount += chunk.size
opCount += 1
}
}
//...
}
增加
增加的逻辑在 cacheDataType 方法中,处理逻辑比较多,比较绕。其中包括了覆盖更新、追加更新两种。
从 SqlProviderCache.kt 的 cacheDataType() 进入 SqlCache.kt 的 mergeAll() 方法,便开始了新增逻辑。
- 创建表。如果存在就忽略。
- 判断是否运用那种存储方式。
val storeResult = if (authoritative) {
storeAuthoritative(type, agent, items, cleanup)
} else {
storeInformative(type, items, cleanup)
}
AUTHORITATIVE 和 INFORMATIVE 的区别:
- AUTHORITATIVE:操作资源表。它在更新表前,获取表名的方法为:resourceTableName(type)。
- INFORMATIVE:操作 *_rel 表。它在更新表前,获取表名的方法为:relTableName(type)。
它们通过 type 来获取表名的函数的实现分别为:
private fun resourceTableName(type: String): String =
checkTableName("cats_v${schemaVersion}_", sanitizeType(type), "")
private fun relTableName(type: String): String =
checkTableName("cats_v${schemaVersion}_", sanitizeType(type), "_rel")
另外它们两,还有一个特性上的区别,如下(来自:AgentDataType.java):
If an agent is an Authoritative source of data, then it’s resulting data set will be considered the current complete set for that data source. If an agent is an Informative source of data, its results will contribute to the data set for that type, but is never considered the complete set of data, so will not result in deletions when elements are no longer present.
资源更新-AUTHORITATIVE
AUTHORITATIVE 的更新资源的逻辑如下:
// 从表中取出已经存在的信息,包括 body_hash 和 id
val existingHashIds = getHashIds(type, agent)
// 找出已存在信息的 id
val existingIds = existingHashIds
.asSequence()
.map { it.id }
.toSet()
// 插入新的信息
// 代码过长,省略
// 根据 id 删除已存在的信息
if (!cleanup) {
return result
}
val toDelete = existingIds
.asSequence()
.filter { !currentIds.contains(it) }
.toSet()
evictAll(type, toDelete)
可以看出来,cleanup 为 true 的时候,才会删除之前的信息,即 cleanup 为 true 才覆盖更新。
关联资源更新-INFORMATIVE
此类型的 db 相关代码逻辑较绕,即函数 storeInformative(type, items, cleanup) 中,引入了很多变量,但通过命名揣测相应含义并不太可行,需要先行知晓一些概念。用到此类型的腾讯云 agent 如下:

外加一个 TencentLoadBalancerInstanceStateCachingAgent,它所实现的接口 HealthProvidingCachingAgent 引用了 INFORMATIVE,即:

此处仅以 TencentLoadBalancerInstanceStateCachingAgent 为例,此 Agent 返回一个 AUTHORITATIVE 类型的 health,还有一个 INFORMATIVE 类型的 instances。health 不看,只看 instances,且直接到 storeInformative(type, items, cleanup)。
Agent 返回的数据
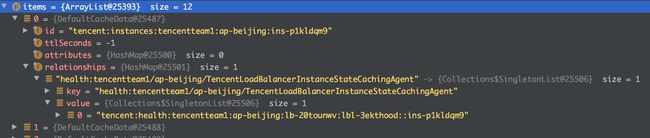
究竟干了啥
- 操作了两张表,cats_v1_instances_rel 和 cats_v1_health_rel。
- 其中的数据分为两类,一类是 fwd 系,另外一类是 rev 系。可能是 forward 和 reverse 的缩写。在此处,fwd 系的数据全部来自 cats_v1_instances_rel;rev 系的数据全部来自 cats_v1_health_rel。代码如下:
fwd

rev
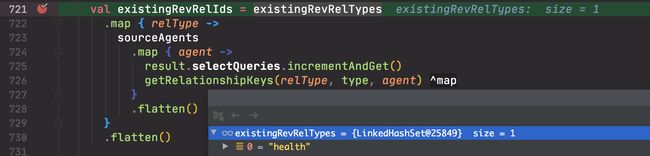
它们调用的方法实现如下:
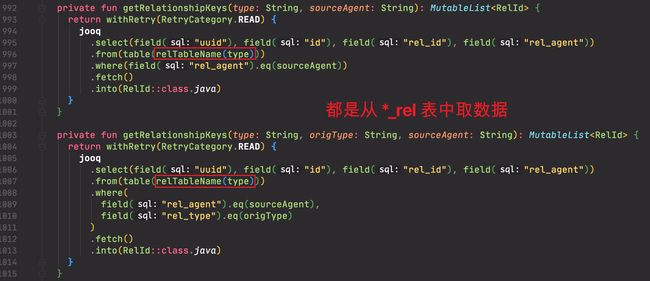
- 由于操作了两张表,且对两张表的操作基本一致,所以对流程而言,可以只分析某一张表的操作逻辑。
- 其中对 fwd 系数据的操作如下:
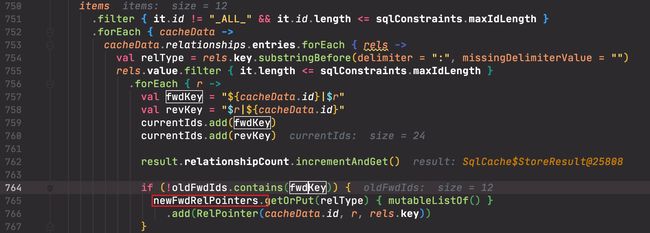
- 从 agent 返回的数据中挑选出新增的数据
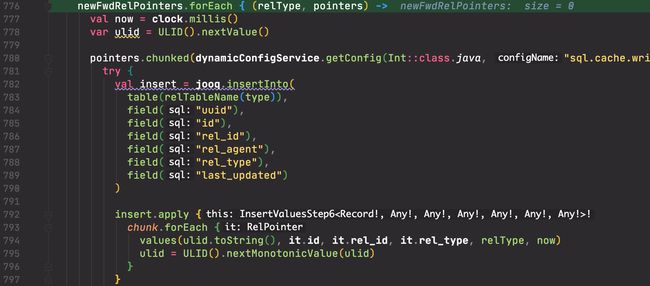
- 插入新增数据
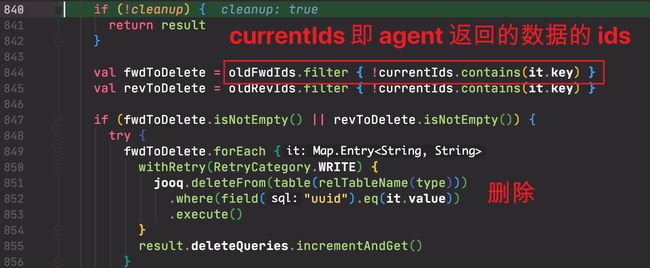
- 删除失效数据(失效的定义:表中存在,但 agent 返回的数据中不存在)
- 从 agent 返回的数据中挑选出新增的数据
与 AUTHORITATIVE 相比,cleanup 仍然是决定是否删除先前数据的一个开关,但是可以看出:
- AUTHORITATIVE 是将 agent 返回的所有数据,全部插入表中,且在 cleanup 开关打开后,将之前所有的数据(即上一批插入的数据)删除。
- INFORMATIVE 只将 agent 返回的新增数据(即之前表中不存在的数据)插入表中,且在 cleanup 开关打开后,将之前已失效的数据删除。
