通过ConnectInterceptor源码掌握OKHttp3网络连接原理 呕心沥血第十弹【十】
ConnectInterceptor
- 系列
- 前言
- 连接拦截器
- Http协议发展
- OKHttp创新
- 源码分析
- ConnectionPool
- StreamAllocation
- RealConnection
- 总结
系列
OKHttp3–详细使用及源码分析系列之初步介绍【一】
OKHttp3–流程分析 核心类介绍 同步异步请求源码分析【二】
OKHttp3–Dispatcher分发器源码解析【三】
OKHttp3–调用对象RealCall源码解析【四】
OKHttp3–拦截器链RealInterceptorChain源码解析【五】
OKHttp3–重试及重定向拦截器RetryAndFollowUpInterceptor源码解析【六】
OKHttp3–桥接拦截器BridgeInterceptor源码解析及相关http请求头字段解析【七】
OKHttp3–缓存拦截器CacheInterceptor源码解析【八】
OKHttp3-- HTTP缓存机制解析 缓存处理类Cache和缓存策略类CacheStrategy源码分析 【九】
通过ConnectInterceptor源码掌握OKHttp3网络连接原理 呕心沥血第十弹【十】
前言
没想到离上篇OKHttp3源码分析文章已经过去了3个月,中间忙着写其它的了,这次准备把OKHttp这个系列结束掉;今天这篇文章来谈谈拦截器链中的第四个拦截器,即连接拦截器,这是OKHttp中非常重要的一个拦截器,值得重视
连接拦截器
这个拦截器类的源码很简单,只有数十行,如下
@Override
public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// 我们需要网络来满足这个请求。可能是为了验证一个GET请求的条件
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpCodec httpCodec = streamAllocation.newStream(client, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
它的作用官方描述的也很简单:
打开与目标服务器的连接,并执行下一个拦截器
虽然代码量很少,实际上大部分功能都封装到其它类去了,这里只是调用而已,其涉及的几个重要类如下
- StreamAllocation
- RealConnection
- ConnectionPool
- HttpCodec
为了更好的了解这些类,我们先回顾下Http协议的发展历史
Http协议发展
Http/1.0
在Http/1.0版本中,有一个我们都很熟悉的特点,就是“无连接”,这里的无连接不是指真的没有连接,而是指每次连接只处理一个请求,服务端在响应客户端的请求后,就主动断开连接,不继续维护该连接;但是如果一个网页包含很多图片,那么每个图片的请求都意味着一次Socket的创建销毁,同时建立和关闭连接又是一个相对比较费时的过程,这样会严重影响客户机和服务器的性能
Http/1.1
在Http/1.1版本中,为了处理1.0中的连接无法复用,于是支持持久连接,在一个TCP连接上可以依次发送多个请求,减少了建立和关闭连接的消耗和延迟;在该版本中默认是打开持久连接的,即在请求头中添加Connection:keep-alive,如果要关闭,需要在请求头中指定Connection:close,keep-alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间
当然了还有其它变化,比如:
- 增加Host请求头字段,WEB浏览器可以使用主机名来明确表示要访问服务器上的哪个WEB站点,实现了在一台WEB服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟WEB站点
- 还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头
慢慢的持久连接的弊端出来了,即HOLB(Head of Line Blocking),或者说线头阻塞,因为同一个持久连接中的请求依然是串行的,当某一个请求因为网络、服务器等原因阻塞了,那后面的所有请求都得不到处理
于是1.1协议中提出了pipelining概念,即客户端在上次请求返回结果前还能继续发送HTTP请求,但服务器端必须按照接收到客户端请求的先后顺序依次返回响应结果,以保证客户端能够区分出每次请求的响应内容,这样就极大地降低了延迟
但是好景不长,pipelining依然存在问题,如下:
- pipelining只支持http1.1
- Post请求不能使用pipelining
- 虽然请求可以同时发出,但是响应必须依次返回,遵循FIFO原则,带来的结果就是如果某一个响应阻塞了,后面的响应也不会返回
SPDY
一系列问题在后来的发展过程中不断优化,但都是治标不治本,直到2012年google提出了SPDY的方案,SPDY是想解决http1.x的痛点,即延迟和安全性;这里谈谈延迟,要想降低延迟,应用层的http和传输层的tcp都是都有调整的空间,但是为了提高业界响应的积极性,Google从应用层下手,只需要在请求的header里设置user agent,然后在server端做好支持即可,极大的降低了部署的难度,设计如下:

SPDY位于HTTP之下,TCP和SSL之上,这样可以轻松兼容老版本的HTTP协议(将http1.x的内容封装成一种新的frame格式),同时可以使用已有的SSL功能
SPDY的功能可以分为基础功能和高级功能两部分,基础功能默认启用,高级功能需要手动启用
SPDY基础功能:
- 多路复用(multiplexing): 它能够让多个 请求stream–响应 完全混杂在一起进行,共享同一个tcp连接,通过streamId来互相区别,这彻底解决了HOLB问题
- 请求优先级(request prioritization):,允许给每个请求设置优先级,服务端会先响应优先级高的请求,避免在多路复用时关键性请求被延后处理
- header压缩:http1.x的header由于cookie和user agent很容易膨胀,而且每次都要重复发送,SPDY对header的压缩率可以达到80%以上
高级功能主要是server推送(server push)和server暗示(server hint),主要是Server主动推送内容给Client,或者提示客户端有新的内容产生,让客户端发起请求获取
Http/2.0
SPDY的诞生让人们意识到是可以在应用层修改协议来优化http1.x的,同时修改后的效果明显且业界反馈良好,于是IETF(Internet Enginerring Task Force)开始正式考虑以SPDY为蓝图制定HTTP2.0的计划
其主要改动如下:
- 新的二进制格式(Binary Format):http/1.x使用的是明文协议,其协议格式由三部分组成:request line,header,body,其协议解析是基于文本,但是这种方式存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合;基于这种考虑,http/2.0的协议解析决定采用二进制格式,实现方便且健壮
- 多路复用(MultiPlexing):即连接共享,在SPDY里提到过streamId用来区分请求,一个request对应一个stream并分配一个id,这样一个TCP连接上可以有多个stream,每个stream的frame可以随机的混杂在一起,接收方可以根据stream id将frame再归属到各自不同的request里面
- 优先级和依赖(Priority、Dependency):每个stream都可以设置优先级和依赖,优先级高的stream会被server优先处理和返回给客户端,stream还可以依赖其它的sub streams;优先级和依赖都是可以动态调整的,比如在APP上浏览商品列表,用户快速滑动到底部,但是前面的请求已经发出,如果不把后面的优先级设高,那么当前浏览的图片将会在最后展示出来,显然不利于用户体验
- header压缩:http2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小
- 重置连接:很多APP里都有停止下载图片的需求,对于http1.x来说,是直接断开连接,导致下次再发请求必须重新建立连接;http2.0引入RST_STREAM类型的frame,可以在不断开连接的前提下取消某个request的stream
当然了还有其它很多改动,这里就不过多叙述
HTTP2.0最大的亮点在于多路复用,当然了这也是OKHttp的优点;HTTP/2.0标准于2015年5月以RFC 7540正式发表,同时为了给http2.0让路,google在2016年不再继续支持SPDY开发,至此,SPDY完成了历史的使命,退出历史的舞台
OKHttp创新
OKHttp针对HTTP/1.x和HTTP/2也分别做了处理
在Android里Google提供了HttpUrlConnection这个API来实现网络请求,当然还有当时非常火热的Volley框架,它也是使用的HttpUrlConnection;但是HttpUrlConnection实现比较简单,只支持1.0/1.1,没有多路复用的机制,如果遇到大量并发请求时,性能会很差;因为Volley是对HttpUrlConnection进行的封装,并没有自己实现网络连接过程,所以并发也是它的缺陷;但是OKHttp不同,它没有使用HttpUrlConnection,InputStream,OutputStream这些api,反而是利用Okio这个开源库实现了一套自己的网络连接机制
HttpUrlConnection在IO方面用到的是InputStream和OutputStream,但是OkHttp用的是sink和source,在http1有两个实现类BufferedSink、BufferedSource,在http2有另外两个实现类FramingSource、FramingSink;其中sink相当于OutputStream,source相当于InputStream
在上面Http/2.0中说过多路复用机制,多个stream可以共用一个TCP连接,每个TCP连接通过一个Socket操作,一个Socket又对应着一个host和port;这时候如果有多个stream或者说多个请求都连接在同一个host和port上,那它们就可以共用一个Socket,这样能极大减少TCP握手/挥手占用的时间
- 在OKHttp中,封装一次连接操作的是RealConnection对象,里面保存了一个Socket负责连接,Handshake负责握手,List
- 一次RealConnection的创建意味着Socket的创建,但是OKHttp使用了ConnectionPool的概念,需要RealConnection就先到连接池里找,如果没有再创建新的RealConnection,然后放入到连接池里(你也可以类比成线程和线程池的意思)
- StreamAllocation封装了一次请求所需的网络组件,内部维护了一个RealConnection记录当前这个Stream是被分配到哪个RealConnection上,还有用来进行网络IO操作的HttpCodec对象
- 请求也有了,连接也有了,谁来充当水管来读写数据呢?当然是HttpCodec了,它的官方注释是对HTTP请求进行编码并解码HTTP响应,针对HTTP/1.x和HTTP/2,OKHttp提供了两个实现类,即Http1Codec、Http2Codec,它们封装了Socket连接的读写操作;Http1Codec内部维护了BufferedSource和BufferedSink进行I/O操作,而Http2Codec内部又进行了封装,维护了Http2Stream对象,其内部维护了FramingSource和FramingSink进行I/O操作
源码分析
解释了这些后,我们再来看下源码是如何带我们入坑的
再将拦截器的源码贴下:
@Override
public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// 我们需要网络来满足这个请求。可能是为了验证一个GET请求的条件
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpCodec httpCodec = streamAllocation.newStream(client, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
首先是获取StreamAllocation对象,它是从拦截器链RealInterceptorChain中获取的,感觉作者是不是词穷了,哈哈,实在没词了用Real表明这真的是最后的实现类了,好多类都是这样;但是实例化其实是在RetryAndFollowUpInterceptor拦截器的intercept方法,然后通过拦截器链的proceed方法传给它,这在前面将这个拦截器的时候提到过
ConnectionPool
接下来看看其StreamAllocation实例化过程
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(request.url()), callStackTrace);
实例化过程重点是传入的第一个参数:client.connectionPool(),看源码知道这是连接池ConnectionPool对象,而它又是在实例化OkHttpClient的时候创建的,这里就不再展示其方法调用了,翻看前面的文章就知道了;但是这里要注意一点:ConnectionPool内部的很多方法的调用都是从OKHttpClient的内部类instance统一对外暴露
接下来看看ConnectionPool这个类,先看官方注释
* Manages reuse of HTTP and HTTP/2 connections for reduced network latency. HTTP requests that
* share the same {@link Address} may share a {@link Connection}. This class implements the policy
* of which connections to keep open for future use.
大概意思如下:
管理HTTP和HTTP/2的重用,以减少网络延迟,相同的Address的HTTP请求将共享同一个Connection
再瞅瞅构造方法
//每个address的最大空闲连接数
private final int maxIdleConnections;
//每个连接的最大保活时间
private final long keepAliveDurationNs;
//路由黑名单,记录不可用的route
final RouteDatabase routeDatabase = new RouteDatabase();
//清理任务正在执行的标志
boolean cleanupRunning;
//OkHttpClient内部调用该方法实例化
public ConnectionPool() {
this(5, 5, TimeUnit.MINUTES);
}
public ConnectionPool(int maxIdleConnections, long keepAliveDuration, TimeUnit timeUnit) {
this.maxIdleConnections = maxIdleConnections;
this.keepAliveDurationNs = timeUnit.toNanos(keepAliveDuration);
// 需要给keep alive duration设置下限
if (keepAliveDuration <= 0) {
throw new IllegalArgumentException("keepAliveDuration <= 0: " + keepAliveDuration);
}
}
通过构造方法可以知道,连接池里每个地址最多可以允许5个空闲连接(注意不是全局的空闲连接限制),同时保活时间是5分钟,当然了这些参数在后面的版本是可能变化的,我这里使用版本的是3.7;
cleanup
既然允许空闲连接,那肯定有清除过期连接的操作,确实,它内部维护了一个线程池和一个负责清除操作的的线程,逻辑如下
private static final Executor executor = new ThreadPoolExecutor(0 /* corePoolSize */,
Integer.MAX_VALUE /* maximumPoolSize */, 60L /* keepAliveTime */, TimeUnit.SECONDS,
new SynchronousQueue(), Util.threadFactory("OkHttp ConnectionPool", true));
private final Runnable cleanupRunnable = new Runnable() {
@Override public void run() {
while (true) {
//对连接池进行清理,返回下次清理等待时间
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (ConnectionPool.this) {
try {
//暂停当前线程
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
}
};
long cleanup(long now) {
//正在使用的连接数
int inUseConnectionCount = 0;
//空闲的连接数
int idleConnectionCount = 0;
//空闲时间最长的连接
RealConnection longestIdleConnection = null;
//最长的空闲时间
long longestIdleDurationNs = Long.MIN_VALUE;
// 通过循环找出一个需要清除的空闲时间最长的连接,或者下次清理的时间
synchronized (this) {
for (Iterator i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
// 判断当前连接是否正在使用,主要逻辑是判断RealConnection里的StreamAllocation集合是否为空
if (pruneAndGetAllocationCount(connection, now) > 0) {
//正在使用的连接数+1
inUseConnectionCount++;
continue;
}
//空闲的连接数+1
idleConnectionCount++;
// 如果当前空闲连接的空闲时间大于最大空闲时间,就给longestIdleDurationNs、longestIdleConnection 重新赋值
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
// 如果空闲时间最长的连接的空闲时间等于或大于保活时间
// 或者空闲连接数等于或者大于最大空闲连接数
//那么将这个空闲时间最长的连接从集合中清除
connections.remove(longestIdleConnection);
} else if (idleConnectionCount > 0) {
// 如果只是存在空闲连接,就计算出下次清理的时间
//比如保活时间是5分钟,有一个空闲连接已经空闲了3分钟,那么还有2分钟就达到最长空闲时间,所以5-2=3分钟后要进行清理
return keepAliveDurationNs - longestIdleDurationNs;
} else if (inUseConnectionCount > 0) {
// 如果没有空闲连接,那就在5分钟后再去清理
return keepAliveDurationNs;
} else {
// 连接池没有连接,返回-1,结束清理线程
cleanupRunning = false;
return -1;
}
}
//关闭这个最长空闲时间的连接的socket资源
closeQuietly(longestIdleConnection.socket());
//清理一个空闲时间最长的连接以后,需要立即再次执行清理
return 0;
}
put/get
ConnectionPool内部维护了一个集合用来保存连接(ArrayDeque不了解的可以参考博主前面的关于它的分析文章)
Deque connections = new ArrayDeque<>();
它的保存操作如下
void put(RealConnection connection) {
//断言,判断线程是不是被自己锁住了
assert (Thread.holdsLock(this));
if (!cleanupRunning) {
cleanupRunning = true;
executor.execute(cleanupRunnable);
}
connections.add(connection);
}
- 首先是根据情况判断是否需要执行清除空闲连接操作,清除在上方已给出
- 然后将连接保存到ArrayDeque中
它的获取操作如下
RealConnection get(Address address, StreamAllocation streamAllocation, Route route) {
//断言,判断线程是不是被自己锁住了
assert (Thread.holdsLock(this));
for (RealConnection connection : connections) {
if (connection.isEligible(address, route)) {
//复用这个连接
streamAllocation.acquire(connection);
return connection;
}
}
return null;
}
这里不是想当然的通过ArrayDeque的get方法获取,要知道这里是根据给定的Address和Route来从连接池中查找是否能有复用的RealConnection
所以是遍历,判断是否还能将一个StreamAllocation分配给RealConnection;如果能,就让StreamAllocation持有connection,同时将这个StreamAllocation添加到RealConnection内部的allocations集合中
其判断逻辑:
- RealConnection能承载最大并发流是一个,如果当前连接已经创建了streams,那就不能在接收新的streams了,也就不能复用了
- 如果地址不同,不能复用
- 如果与当前连接的主机完全相同,那就可以复用
- 如果host不相同,在HTTP/2的域名切片场景下一样可以复用,但是要求这个新的连接必须是HTTP/2
再看看其它方法,因为后续会使用到
pruneAndGetAllocationCount
private int pruneAndGetAllocationCount(RealConnection connection, long now) {
List> references = connection.allocations;
for (int i = 0; i < references.size(); ) {
Reference reference = references.get(i);
//如果StreamAllocation被使用,则遍历下一个
if (reference.get() != null) {
i++;
continue;
}
// 到这里说明StreamAllocation未被使用
StreamAllocation.StreamAllocationReference streamAllocRef =
(StreamAllocation.StreamAllocationReference) reference;
String message = "A connection to " + connection.route().address().url()
+ " was leaked. Did you forget to close a response body?";
Platform.get().logCloseableLeak(message, streamAllocRef.callStackTrace);
//那就删除它
references.remove(i);
//修改noNewStreams值,表明这个连接不能再分配新的流了
connection.noNewStreams = true;
// 如果集合为null,说明这个连接没有被引用了,是一个空闲连接
if (references.isEmpty()) {
connection.idleAtNanos = now - keepAliveDurationNs;
return 0;
}
}
//返回集合实际大小
return references.size();
}
该方法是修正连接上分配的StreamAllocation数量,避免泄漏;如果返回值是0,说明该连接是空闲连接;如果大于0,说明是活跃连接
evictAll
public void evictAll() {
List evictedConnections = new ArrayList<>();
synchronized (this) {
for (Iterator i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
if (connection.allocations.isEmpty()) {
connection.noNewStreams = true;
evictedConnections.add(connection);
i.remove();
}
}
}
for (RealConnection connection : evictedConnections) {
closeQuietly(connection.socket());
}
}
这个方法就很简单了,清除所有空闲连接,释放Socket资源
connectionBecameIdle
boolean connectionBecameIdle(RealConnection connection) {
assert (Thread.holdsLock(this));
if (connection.noNewStreams || maxIdleConnections == 0) {
connections.remove(connection);
return true;
} else {
notifyAll(); // 唤醒清理线程,我们可能已超过空闲连接限制
return false;
}
}
判断一个连接是否是空闲连接,如果是,就需要从集合中清除;否则唤醒清除线程
deduplicate
Socket deduplicate(Address address, StreamAllocation streamAllocation) {
assert (Thread.holdsLock(this));
for (RealConnection connection : connections) {
if (connection.isEligible(address, null)
&& connection.isMultiplexed()
&& connection != streamAllocation.connection()) {
return streamAllocation.releaseAndAcquire(connection);
}
}
return null;
}
看名称是去重的意思,主要是判断如果当前请求是HTTP/2,那么所有指向该地址的请求都应该共享同一个TCP连接,也就是多路复用,
那么就遍历连接池中所有连接,找到一个可以复用的连接
StreamAllocation
希望读者没有被绕晕,好,讲完了连接池,再回头看StreamAllocation,它被实例化了之后,重点是下面两行代码
HttpCodec httpCodec = streamAllocation.newStream(client, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
到这里再简单介绍下StreamAllocation,在上面说过,这个对象封装了一次网络请求所需的组件,什么意思呢?贴一段官方注释
* This class coordinates the relationship between three entities:
*
*
* - Connections: physical socket connections to remote servers. These are
* potentially slow to establish so it is necessary to be able to cancel a connection
* currently being connected.
*
- Streams: logical HTTP request/response pairs that are layered on
* connections. Each connection has its own allocation limit, which defines how many
* concurrent streams that connection can carry. HTTP/1.x connections can carry 1 stream
* at a time, HTTP/2 typically carry multiple.
*
- Calls: a logical sequence of streams, typically an initial request and
* its follow up requests. We prefer to keep all streams of a single call on the same
* connection for better behavior and locality.
*
我们知道一次网络连接有三个角色:请求、连接、流,当一个请求发出,那就需要建立连接,连接建立后需要一个流用来读写数据;而这个StreamAllocation就是协调这三者之间的关系,它负责为一次请求寻找连接,然后建立流来实现网络通信;这三个角色与注释中的Calls、Connections、Streams对应;
- Call是对一次请求信息的封装,在StreamAllocation里对应着Address、Route等信息
- Connection是对Socket链路的封装,在StreamAllocation里持有一个RealConnection的引用
- Stream代表读写数据的流,在StreamAllocation里持有一个HttpCodec的引用,它根据HTTP版本不同有两个实现类:Http1Codec、Http2Codec
既然这样,那么StreamAllocation实际负责的操作就有从连接池中为一个请求找到合适的连接,获取流,当然还有关闭流、终止、取消等方法,下面就从源码看看
先看下它内部定义的变量
//地址
public final Address address;
//路由
private Route route;
//连接池
private final ConnectionPool connectionPool;
//日志
private final Object callStackTrace;
// 路由选择器
private final RouteSelector routeSelector;
//拒绝次数
private int refusedStreamCount;
//连接
private RealConnection connection;
//是否被释放
private boolean released;
//是否被取消
private boolean canceled;
//先理解成OKHttp中的流吧,主要是封装了I/O操作
private HttpCodec codec;
可以看到跟上面分析的基本一致
newStream
接下来看第一个方法
public HttpCodec newStream(OkHttpClient client, boolean doExtensiveHealthChecks) {
int connectTimeout = client.connectTimeoutMillis();
int readTimeout = client.readTimeoutMillis();
int writeTimeout = client.writeTimeoutMillis();
boolean connectionRetryEnabled = client.retryOnConnectionFailure();
try {
//找到一个健康的连接
RealConnection resultConnection = findHealthyConnection(connectTimeout, readTimeout,
writeTimeout, connectionRetryEnabled, doExtensiveHealthChecks);
//利用连接实例化流HttpCodec对象,如果是HTTP/2返回Http2Codec,否则返回Http1Codec
HttpCodec resultCodec = resultConnection.newCodec(client, this);
synchronized (connectionPool) {
//让当前的StreamAllocation持有这个流对象,然后返回它
codec = resultCodec;
return resultCodec;
}
} catch (IOException e) {
throw new RouteException(e);
}
}
看名字就知道这个方法是获取流的,重点逻辑是findHealthyConnection和newCodec两个方法,先看看findHealthyConnection
findHealthyConnection
private RealConnection findHealthyConnection(int connectTimeout, int readTimeout,
int writeTimeout, boolean connectionRetryEnabled, boolean doExtensiveHealthChecks)
throws IOException {
while (true) {
//找到一个连接
RealConnection candidate = findConnection(connectTimeout, readTimeout, writeTimeout,
connectionRetryEnabled);
// 如果这个连接是新建立的,那肯定是健康的,直接返回
synchronized (connectionPool) {
if (candidate.successCount == 0) {
return candidate;
}
}
// 如果不是新创建的,需要检查是否健康
if (!candidate.isHealthy(doExtensiveHealthChecks)) {
//不健康 关闭连接,释放Socket资源
//如果这个连接不会再创建新的stream,从连接池移除
//继续下次寻找连接操作
noNewStreams();
continue;
}
//如果是健康的就重用,返回
return candidate;
}
}
该方法主要是查找一个健康的连接,如果找不到,那就一直找,直到找到为止;这就好奇了,什么样的连接是不健康的呢?看看isHealthy方法
isHealthy
public boolean isHealthy(boolean doExtensiveChecks) {
if (socket.isClosed() || socket.isInputShutdown() || socket.isOutputShutdown()) {
return false;
}
if (http2Connection != null) {
return !http2Connection.isShutdown();
}
......
return true;
}
- 连接对象的Socket关闭了、输入流关闭了、输出流关闭了,这些情况只要有一个发生都是不健康的
- http2连接关闭视为不健康
findConnection
最后通过findConnection方法看下是怎么找到一个连接的
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
boolean connectionRetryEnabled) throws IOException {
Route selectedRoute;
synchronized (connectionPool) {
......
// 尝试使用已分配的连接 第一次进来内部维护connection肯定是null
RealConnection allocatedConnection = this.connection;
if (allocatedConnection != null && !allocatedConnection.noNewStreams) {
return allocatedConnection;
}
// 尝试从连接池获取连接,如果有可复用的连接 就返回
Internal.instance.get(connectionPool, address, this, null);
if (connection != null) {
return connection;
}
selectedRoute = route;
}
// 第一次进来肯定是null,需要递归创建一个路由,是个阻塞的过程
if (selectedRoute == null) {
selectedRoute = routeSelector.next();
}
RealConnection result;
synchronized (connectionPool) {
//请求被取消了 抛出异常
if (canceled) throw new IOException("Canceled");
// 现在有了ip address,那就更换路由再从连接池里获取 对多IP的支持
Internal.instance.get(connectionPool, address, this, selectedRoute);
if (connection != null) return connection;
// 到这里说明实在找不到 必须要实例化一个连接了
route = selectedRoute;
refusedStreamCount = 0;
result = new RealConnection(connectionPool, selectedRoute);
//将这个连接分配给流
//同时将流添加到这个连接的集合里
acquire(result);
}
// 对于新创建的连接,要执行TCP + TLS握手来建立连接 阻塞操作
result.connect(connectTimeout, readTimeout, writeTimeout, connectionRetryEnabled);
//将这个路由从路由黑名单移除
routeDatabase().connected(result.route());
Socket socket = null;
synchronized (connectionPool) {
// 将新创建的连接放到连接池中
Internal.instance.put(connectionPool, result);
// 如果当前创建的连接是一个支持多路复用的连接(只要是HTTP/2连接,就可以同时用于多个HTTP请求,所有指向该地址的请求都应该基于同一个TCP连接),
//同时连接池里存在一个同样的连接,那就释放掉当前这个连接,复用连接池里的连接
if (result.isMultiplexed()) {
socket = Internal.instance.deduplicate(connectionPool, address, this);
result = connection;
}
}
//关闭新建连接的Socket
closeQuietly(socket);
//返回复用的连接
return result;
}
主要逻辑如下:
- 先判断当前已经存在的连接是否能使用,如果可以使用(也就是能创建stream),那就返回
- 根据路由从连接池中查找,如果能找到就返回
- 更换路由地址再次从连接池里查找,如果能找到就返回
- 到这里说明必须要实例化一个新的连接了,将自己关联到这个连接的allocations集合里,然后建立Socket连接,并将路由从黑名单移除
- 如果这个连接支持多路复用,那就从连接池中找到可以复用的连接,并释放这个新建的连接,关闭Socket,返回连接
acquire
这里调用到这个方法进行关联
public void acquire(RealConnection connection) {
assert (Thread.holdsLock(connectionPool));
if (this.connection != null) throw new IllegalStateException();
this.connection = connection;
connection.allocations.add(new StreamAllocationReference(this, callStackTrace));
}
将传进来的连接赋值给全局变量,同时将分配的流添加到这个连接的allocations集合里
StreamAllocationReference是一个内部类,继承WeakReference
接下来看看这个类的其它方法
release
private void release(RealConnection connection) {
for (int i = 0, size = connection.allocations.size(); i < size; i++) {
Reference reference = connection.allocations.get(i);
if (reference.get() == this) {
connection.allocations.remove(i);
return;
}
}
throw new IllegalStateException();
}
作用是从连接的StreamAllocation链表中删除当前StreamAllocation,解除连接和StreamAllocation的引用关系
deallocate
private Socket deallocate(boolean noNewStreams, boolean released, boolean streamFinished) {
assert (Thread.holdsLock(connectionPool));
//关闭流
if (streamFinished) {
this.codec = null;
}
//释放连接
if (released) {
this.released = true;
}
Socket socket = null;
if (connection != null) {
if (noNewStreams) {
//重置标志 不能在该连接上分配流
connection.noNewStreams = true;
}
if (this.codec == null && (this.released || connection.noNewStreams)) {
//从连接的StreamAllocation链表中删除当前StreamAllocation
release(connection);
//如果链表为空,说明是个空闲连接
if (connection.allocations.isEmpty()) {
connection.idleAtNanos = System.nanoTime();
//从连接池中清除该连接
if (Internal.instance.connectionBecameIdle(connectionPool, connection)) {
socket = connection.socket();
}
}
connection = null;
}
}
//返回该连接持有的Socket
return socket;
}
该方法主要是释放StreamAllocation持有的连接的资源并返回连接持有的Socket,通常该方法调用者需要关闭该Socket,比如
//释放连接,关闭Socket
public void release() {
Socket socket;
synchronized (connectionPool) {
socket = deallocate(false, true, false);
}
closeQuietly(socket);
}
//设置不能在此连接上创建新的流,同时关闭Socket
public void noNewStreams() {
Socket socket;
synchronized (connectionPool) {
socket = deallocate(true, false, false);
}
closeQuietly(socket);
}
streamFinished
public void streamFinished(boolean noNewStreams, HttpCodec codec) {
Socket socket;
synchronized (connectionPool) {
if (codec == null || codec != this.codec) {
throw new IllegalStateException("expected " + this.codec + " but was " + codec);
}
if (!noNewStreams) {
//对该连接使用计数+1
//大于0表示这不是一个新的连接
connection.successCount++;
}
socket = deallocate(noNewStreams, false, true);
}
closeQuietly(socket);
}
该方法是关闭流
cancel
这个方法就是取消流或者连接
public void cancel() {
HttpCodec codecToCancel;
RealConnection connectionToCancel;
synchronized (connectionPool) {
canceled = true;
codecToCancel = codec;
connectionToCancel = connection;
}
if (codecToCancel != null) {
codecToCancel.cancel();
} else if (connectionToCancel != null) {
connectionToCancel.cancel();
}
}
RealConnection
StreamAllocation内部维护了一个与它相关的连接RealConnection的引用,在连接拦截器的拦截方法里也是通过StreamAllocation获取这个引用,同时还有内部维护的流,然后交给下个拦截器处理;而RealConnection内部也有一个集合记录了哪些StreamAllocation在引用自己,那接下来就看看这个代表一个Socket链路的类真实面目
RealConnection实现了Connection接口,看看官网对这个接口的注释,这里摘取一部分
该连接可用于HTTP,HTTPS或HTTPS + HTTP / 2连接的Socket和streams,可用于多个HTTP请求/响应,拥有了它意味着你与服务器或代理服务器有了一条通信链路
每个Connection可以携带不同的数量的streams,具体取决于所使用的基础协议; HTTP / 1.x连接可以携带零个或一个流, HTTP / 2连接可以携带任意数量的流;
使用{@code SETTINGS_MAX_CONCURRENT_STREAMS}动态配置。当前承载零流的连接是空闲流。我们保持活着,因为重用现有连接通常比建立新连接更快
该接口提供了四个方法
- Route route():返回该连接使用的路由
- Socket socket():返回该连接正在使用的Socket;如果此连接使用的是HTTPS,则返回javax.net.ssl.SSLSocket;使用HTTP/2,则该Socket则可能由多个Call共享
- Handshake handshake():如果此连接使用的是HTTPS,则返回TLS handshake,否则返回null
- Protocol protocol():返回此连接使用的协议
接下来再具体看下RealConnection的实现,先从内部变量看
//连接池
private final ConnectionPool connectionPool;
//路由
private final Route route;
// 下面这些字段在connect方法初始化,不会在其它地方再赋值
/** 底层socket. */
private Socket rawSocket;
//应用层Socket
private Socket socket;
//握手
private Handshake handshake;
//协议
private Protocol protocol;
//负责Http/2的连接 支持多路复用,一个连接可以承载多个Http请求
private Http2Connection http2Connection;
//输入流
private BufferedSource source;
//输出流
private BufferedSink sink;
// 下面属于连接状态的字段,由连接池统一管理
/** 如果为true,表明不能在这个连接上创建新的流;如果被设置为true,后面就不会再被改变 */
public boolean noNewStreams;
//成功的次数,如果为0,说明是一个新建的连接
public int successCount;
/**
* 此连接可以承载的最大并发流数,默认Http/1.x是1,如果是Http/2,这个值会被重置
* 如果allocations.size()> allocations = new ArrayList<>();
- 该连接使用BufferedSource和BufferedSink和服务器进行I/O操作
- 只要noNewStreams设置为true,那这个连接就不能在使用了
- allocations记录了该连接关联的StreamAllocation,最大并发数是1;StreamAllocation可以通过acquire方法关联到连接,release方法移除关联关系
connect
除了ConnectionPool和Route,其它字段在connect方法初始化,那就看下该方法
public void connect(int connectTimeout, int readTimeout, int writeTimeout, boolean connectionRetryEnabled) {
//protocol只能在该方法后初始化
if (protocol != null) throw new IllegalStateException("already connected");
RouteException routeException = null;
List connectionSpecs = route.address().connectionSpecs();
ConnectionSpecSelector connectionSpecSelector = new ConnectionSpecSelector(connectionSpecs);
//SSLSocketFactory为空,也就是要求请求/响应明文传输,需要做安全性检查,以确认系统允许明文传输
if (route.address().sslSocketFactory() == null) {
if (!connectionSpecs.contains(ConnectionSpec.CLEARTEXT)) {
throw new RouteException(new UnknownServiceException(
"CLEARTEXT communication not enabled for client"));
}
String host = route.address().url().host();
if (!Platform.get().isCleartextTrafficPermitted(host)) {
throw new RouteException(new UnknownServiceException(
"CLEARTEXT communication to " + host + " not permitted by network security policy"));
}
}
//开始连接
while (true) {
try {
if (route.requiresTunnel()) {
//以隧道模式建立连接 用的少
connectTunnel(connectTimeout, readTimeout, writeTimeout);
} else {
//三次握手,使用Socket创建 TCP 连接 通用
connectSocket(connectTimeout, readTimeout);
}
//在 TCP 连接的基础上,开始根据不同版本的协议,来完成建立协议过程,
//主要有 HTTP/1.1,HTTP/2 和 SPDY ;如果是 HTTPS 类型的,则需要 TLS 建链
establishProtocol(connectionSpecSelector);
break;
} catch (IOException e) {
closeQuietly(socket);
closeQuietly(rawSocket);
socket = null;
rawSocket = null;
source = null;
sink = null;
handshake = null;
protocol = null;
http2Connection = null;
if (routeException == null) {
routeException = new RouteException(e);
} else {
routeException.addConnectException(e);
}
if (!connectionRetryEnabled || !connectionSpecSelector.connectionFailed(e)) {
throw routeException;
}
}
}
if (http2Connection != null) {
synchronized (connectionPool) {
//如果是Http/2连接,就重置最大连接数
allocationLimit = http2Connection.maxConcurrentStreams();
}
}
}
这个方法很重要,开始与服务器建立连接,总结如下:
第一步:
首先会通过protocol检查连接是否已经建立,protocol表示在整个连接建立及协商过程中所用到的协议,如果不为null,表明连接已经建立
第二步:
接下来对不安全的请求进行一些限制,这里要了解下ConnectionSpec这个类,直译为连接规格(做自定义View的肯定知道测量规格MeasureSpec这个类,差不多意思),这里摘取部分官网注释:
为HTTP数据通信指定一种Socket连接配置,对于HTTPS的请求,在协商一种安全的链接时包括TLS版本(TLS version )和密码套件(cipher suites)配置
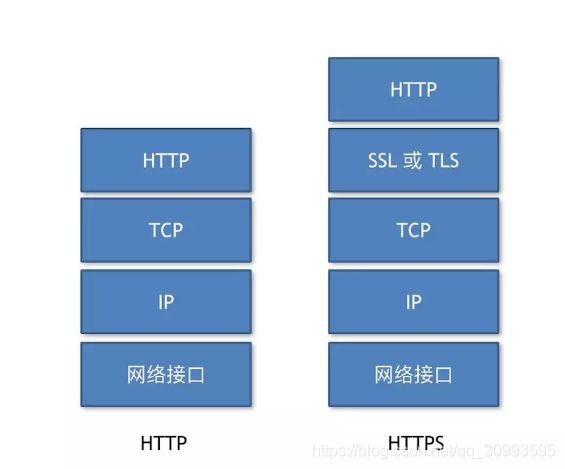
这里又出来了一个新的概念TLS,TLS是进行HTTPS请求的关键步骤,通过了TLS层的协商,后续的HTTP请求就可以使用协商好的对称密钥进行加密;与之对应的HTTP是明文传输,不安全的协议,而HTTPS是安全的协议,如图
HTTPS是在HTTP和TCP之间加了一层TLS,这个TLS协商了一个对称密钥来进行HTTP加密;TLS还有一个老哥,即SSL,SSL是Netscape开发的专门用来保护Web通讯的安全性,而TLS是IETF制定的新协议,建立在SSL3.0之上,所以TLS1.0可以认为是SSL3.1
再说回ConnectionSpec,它默认提供三种连接规格,如下:
- MODERN_TLS:可以使用SNI和ALPN等扩展的现代TLS连接
- COMPATIBLE_TLS:用于与过时服务器操作的向后兼容回退连接
- CLEARTEXT:未加密,未经身份验证的Http连接
OKHttp默认会先使用现代TLS连接的规格(ConnectionSepc.MODEN_TLS)进行连接,如果失败会采用回退策略(连接规格选择的策略由 ConnectSpecSelector 进行)选择下一个
再说回上面的connect方法,判断如果不是Https连接,会有如下两种判断
- 如果连接规格不包含CLEARTEXT,说明客户端未启用CLEARTEXT通信,那就没法使用了,抛出异常
- 如果服务器不允许明文(CLEARTEXT)传输,而客户端的连接又是非Https的,那也没法继续下去了,抛出异常
第三步:
这一步与服务器开始建链,如果以隧道模式建立连接,调用connectTunnel;否则就是调用connectSocket方法,使用Socket建立普通连接;判断条件是通过路由对象的requiresTunnel方法:
public boolean requiresTunnel() {
return address.sslSocketFactory != null && proxy.type() == Proxy.Type.HTTP;
}
如果一个请求要建立SSL/TLS加密通道 (http/1.1的https和http2),但是走Http代理服务器,这种情况下普通代理无法代理Https的报文,那这就需要走Http隧道代理实现;其实现步骤在《HTTP 权威指南》书中有介绍
客户端先发送 CONNECT 请求到隧道代理服务器,告诉它建立和服务器的 TCP 连接(因为是 TCP 连接,只需要 ip 和端口就行,不需要关注上层的协议类型)
代理服务器成功和后端服务器建立 TCP 连接
代理服务器返回 HTTP 200 Connection Established 报文,即响应码是HTTP_OK,告诉客户端连接已经成功建立
这个时候就建立起了连接,所有发给代理的 TCP 报文都会直接转发,从而实现服务器和客户端的通信
有人好奇为啥普通代理无法实现,因为Https报文都是经过加密处理,如果走普通代理,代理服务器无法解析Request请求头,获取目标服务器的地址信息,也就无法与其建链;所以Https请求必须首先使用Http CONNECT建立隧道(在下面创建隧道的时候会再讲到),CONNECT 请求的内容和其他 HTTP 方法的语法一样,只不过它在状态栏(status line)指定了真正服务器的地址;请求 URI 替换成了 hostname 和 port 的字符串,比如:
CONNECT realserver:443 HTTP/1.0
知道了hostname和port,代理服务器就能与目标服务器建链,才能够继续后面的访问;需要注意的是,客户端应该尽量少地暴露其他信息,最好只有状态栏一行的内容,因为 CONNECT 请求是没有经过加密的。如果想通过这种方式进行 HTTPS 安全访问,那么不要在 CONNECT 请求中暴露敏感数据(比如 cookie);如果代理服务器正确接受了 CONNECT 请求,并且成功建立了和后端服务器的 TCP 连接,它应该返回 200 状态码的应答,按照大多数的约定为 200 Connection Establised。应答也不需要包含其他的头部和 body,因为后续的数据传输都是直接转发的,代理不会分析其中的内容
第四步:
在完成了Socket连接后,就需要调用establishProtocol方法建立协议,其中协议的建立需要区分Http请求和Https请求
第五步:
如果是Http/2连接,就重置最大连接数,符合多路复用的特性
整个connect方法流程差不多是这样,接下来看看里面几个重要的方法调用,先看看普通连接connectSocket方法,因为隧道连接connectTunnel内部也会调用到该方法
connectSocket
//构建完整的Http/Https连接
private void connectSocket(int connectTimeout, int readTimeout) throws IOException {
Proxy proxy = route.proxy();
Address address = route.address();
rawSocket = proxy.type() == Proxy.Type.DIRECT || proxy.type() == Proxy.Type.HTTP
? address.socketFactory().createSocket()
: new Socket(proxy);
rawSocket.setSoTimeout(readTimeout);
try {
Platform.get().connectSocket(rawSocket, route.socketAddress(), connectTimeout);
} catch (ConnectException e) {
ConnectException ce = new ConnectException("Failed to connect to " + route.socketAddress());
ce.initCause(e);
throw ce;
}
source = Okio.buffer(Okio.source(rawSocket));
sink = Okio.buffer(Okio.sink(rawSocket));
}
第一步:
通过proxy.type判断代理类型,Proxy这个类比较简单,它不属于OKHttp,在 java.net包下,内部维护了两个变量:Type、SocketAddress;只需要代理类型和代理服务器地址即可描述代理服务器的全部
其中Type有三个选项
- DIRECT:表示直接连接或缺少代理
- HTTP:表示高级协议(如HTTP或FTP)的代理
- SOCKS:表示SOCKS代理
这里简单介绍下HTTP代理和SOCKS代理:
- HTTP代理:这种代理也是最常见的代理,基于HTTP协议的一种代理,代理客户机的http访问,主要代理浏览器访问网页,一般公司里都需要设置代理,才能从内网访问外网
- SOCKS代理:Socks代理是基于Socks协议的一种代理,Socks协议工作在会话层,它不关心应用层使用何种协议(比如FTP、HTTP和NNTP请求),Socks代理只是简单地传递数据包,所以SOCKS代理服务器比其他类型的代理服务器速度要快得多;SOCKS代理又分为SOCKS4和SOCKS5,SOCKS4代理只支持TCP协议(即传输控制协议),而SOCKS5代理既支持TCP协议又支持UDP协议(即用户数据包协议),还支持各种身份验证机制、服务器端域名解析等
Socks协议即防火墙安全会话转换协议,Socks协议提供一个框架,为在TCP和UDP域中的客户机/服务器应用程序能更方便安全地使用网络防火墙所提供的服务;
再回到connectSocket方法,当代理类型是SOCKS代理时,直接new一个Socket;否则通过SocketFactory创建,然后设置超时时间
第二步:
接下来就是使用创建好的Socket进行连接了,但是这里使用的是Platform.get().connectSocket,这主要是为了支持各种平台(包括Android版本和JDK版本),看这个类的注释就知道了;
其内部也是调用的socket.connect,跟我们平时使用是一样的
第三步:
接下来就是获取I/O操作的输入流和输出流,这里依赖于Okio这个库
connectTunnel
接下来就到隧道连接connectTunnel方法了
private void connectTunnel(int connectTimeout, int readTimeout, int writeTimeout)
throws IOException {
Request tunnelRequest = createTunnelRequest();
HttpUrl url = tunnelRequest.url();
int attemptedConnections = 0;
int maxAttempts = 21;
while (true) {
if (++attemptedConnections > maxAttempts) {
throw new ProtocolException("Too many tunnel connections attempted: " + maxAttempts);
}
connectSocket(connectTimeout, readTimeout);
tunnelRequest = createTunnel(readTimeout, writeTimeout, tunnelRequest, url);
if (tunnelRequest == null) break;
closeQuietly(rawSocket);
rawSocket = null;
sink = null;
source = null;
}
}
第一步:
通过createTunnelRequest方法创建一个隧道请求
private Request createTunnelRequest() {
return new Request.Builder()
.url(route.address().url())
.header("Host", Util.hostHeader(route.address().url(), true))
.header("Proxy-Connection", "Keep-Alive") // For HTTP/1.0 proxies like Squid.
.header("User-Agent", Version.userAgent())
.build();
}
上面在讲Http隧道代理的时候提到,客户端会先发送一个很简单的请求给代理服务器,在头部标出目标服务器的host信息,让代理服务器与目标服务器建链,而这里就是创建第一个请求
第二步:
定义了两个局部变量,当前尝试次数和总的尝试次数,然后就是在while循环中建立Socket连接,建立隧道
首先通过connectSocket方法建立Socket连接,这在上面讲过了;接下来就是调用createTunnel方法创建隧道,如果返回的隧道请求是null,说明隧道成功创建;如果不等于null,说明代理需要授权,就需要重新创建连接
createTunnel
接下来通过该方法看看是如何创建隧道的(真是无穷无尽的方法调用啊,看的我眼都花了)
private Request createTunnel(int readTimeout, int writeTimeout, Request tunnelRequest,
HttpUrl url) throws IOException {
// 拼接一个SSL隧道请求行
String requestLine = "CONNECT " + Util.hostHeader(url, true) + " HTTP/1.1";
while (true) {
//实例化I/O操作对象
Http1Codec tunnelConnection = new Http1Codec(null, null, source, sink);
//设置超时时间
source.timeout().timeout(readTimeout, MILLISECONDS);
sink.timeout().timeout(writeTimeout, MILLISECONDS);
//将请求发送到代理服务器,然后转发给目标服务器
tunnelConnection.writeRequest(tunnelRequest.headers(), requestLine);
tunnelConnection.finishRequest();
//获取代理服务器的响应,其实是目标服务器的响应,代理服务器转发
Response response = tunnelConnection.readResponseHeaders(false)
.request(tunnelRequest)
.build();
//来自CONNECT的响应主体应该是空的,但如果不是,那么我们应该在继续之前使用它
long contentLength = HttpHeaders.contentLength(response);
if (contentLength == -1L) {
contentLength = 0L;
}
Source body = tunnelConnection.newFixedLengthSource(contentLength);
Util.skipAll(body, Integer.MAX_VALUE, TimeUnit.MILLISECONDS);
body.close();
switch (response.code()) {
case HTTP_OK://建立成功
if (!source.buffer().exhausted() || !sink.buffer().exhausted()) {
throw new IOException("TLS tunnel buffered too many bytes!");
}
return null;
case HTTP_PROXY_AUTH:表示服务器要求客户端提供访问证书,进行代理认证,将认证信息合并到tunnelRequest中以便下次重试
//进行代理认证
tunnelRequest = route.address().proxyAuthenticator().authenticate(route, response);
//代理认证不通过
if (tunnelRequest == null) throw new IOException("Failed to authenticate with proxy");
//代理认证通过,但是响应要求close,则关闭TCP连接此时客户端无法再此连接上发送数据
if ("close".equalsIgnoreCase(response.header("Connection"))) {
return tunnelRequest;
}
break;
default:
throw new IOException(
"Unexpected response code for CONNECT: " + response.code());
}
}
}
该方法的作用就是:要想通过HTTP代理服务器建立HTTPS连接,就需要发送CONNECT请求以创建代理连接,但是可能会因为需要授权而失败,如果这样需要在下次请求时带上认证信息再次创建
到这里总算创建出来了Socket,与服务器或者代理服务器建立了连接,接下来需要建立协议了,让我们从establishProtocol一探究竟
establishProtocol
private void establishProtocol(ConnectionSpecSelector connectionSpecSelector) throws IOException {
//如果不是ssl,那就设置应用层协议为Http/1.1
if (route.address().sslSocketFactory() == null) {
protocol = Protocol.HTTP_1_1;
socket = rawSocket;
return;
}
//创建TLS连接
connectTls(connectionSpecSelector);
//如果应用层协议是Http/2,那就需要实例化http2Connection
if (protocol == Protocol.HTTP_2) {
socket.setSoTimeout(0); //设置读取数据时阻塞链路的超时时间,值为0意味着没有超时限制,无限等待
http2Connection = new Http2Connection.Builder(true)
.socket(socket, route.address().url().host(), source, sink)
.listener(this)
.build();
http2Connection.start();
}
}
该方法逻辑比较简单:对于明文传输,那就设置protocol和socket;否则需要创建TLS,如果是HTTP2,需要实例化一个http2Connection,然后和服务器建立连接
这里可能有人好奇,为啥是Https请求的时候才判断是否是Http/2协议,难道Http请求不使用Http/2协议吗?其实在目前实际使用中,Http2协议基本只用于HTTPS协议场景下,通过握手阶段ClientHello与ServerHello的extension字段协商而来,所以目前HTTP2的使用场景,都是默认安全加密的,主流的浏览器像chrome,firefox还是只支持基于 TLS 部署的HTTP/2协议
connectTls
接下来看看connectTls方法
private void connectTls(ConnectionSpecSelector connectionSpecSelector) throws IOException {
Address address = route.address();
SSLSocketFactory sslSocketFactory = address.sslSocketFactory();
boolean success = false;
SSLSocket sslSocket = null;
try {
// 在已连接的socket上再包装一个ssl
sslSocket = (SSLSocket) sslSocketFactory.createSocket(
rawSocket, address.url().host(), address.url().port(), true /* autoClose */);
// 给socket配置合适的连接规格
ConnectionSpec connectionSpec = connectionSpecSelector.configureSecureSocket(sslSocket);
if (connectionSpec.supportsTlsExtensions()) {
Platform.get().configureTlsExtensions(
sslSocket, address.url().host(), address.protocols());
}
// 握手协商 客户端正式向服务端发出数据包,内容为可选择的密码和请求证书。服务端会返回相应的密码套件,tls 版本,节点证书,本地证书等等,然后封装在 Handshake 类中
sslSocket.startHandshake();
Handshake unverifiedHandshake = Handshake.get(sslSocket.getSession());
// 验证Socket的证书是否可用于目标服务器
if (!address.hostnameVerifier().verify(address.url().host(), sslSocket.getSession())) {
X509Certificate cert = (X509Certificate) unverifiedHandshake.peerCertificates().get(0);
throw new SSLPeerUnverifiedException("Hostname " + address.url().host() + " not verified:"
+ "\n certificate: " + CertificatePinner.pin(cert)
+ "\n DN: " + cert.getSubjectDN().getName()
+ "\n subjectAltNames: " + OkHostnameVerifier.allSubjectAltNames(cert));
}
// 检查证书pinner是否满足所提供的证书
address.certificatePinner().check(address.url().host(),
unverifiedHandshake.peerCertificates());
// 协商成功, 保存握手和ALPN协议
String maybeProtocol = connectionSpec.supportsTlsExtensions()
? Platform.get().getSelectedProtocol(sslSocket)
: null;
socket = sslSocket;
//实例化输出输入流
source = Okio.buffer(Okio.source(socket));
sink = Okio.buffer(Okio.sink(socket));
handshake = unverifiedHandshake;
protocol = maybeProtocol != null
? Protocol.get(maybeProtocol)
: Protocol.HTTP_1_1;
success = true;
} catch (AssertionError e) {
if (Util.isAndroidGetsocknameError(e)) throw new IOException(e);
throw e;
} finally {
if (sslSocket != null) {
Platform.get().afterHandshake(sslSocket);
}
if (!success) {
closeQuietly(sslSocket);
}
}
}
总结
本篇文章结合StreamAllocation、RealConnection、ConnectionPool等分析了OKHttp中连接拦截器ConnectInterceptor的原理,了解了Http协议的发展历史及特点,HttpUrlConnection的缺陷,OKHttp设计的连接池概念,多路复用、普通代理、Http隧道代理以及对HTTP/2的支持,阅读源码让我们了解的更多,但是无穷无尽的方法调用,会让阅读者感到头晕,我的办法是抓住重点,一段时间分析一部分,分段进行,不要想着一股脑把所有源码都看完;阅读OKHttp源码也有利于对与其关系密切的Retrofit和Glide的理解
参考:
HTTP 2.0的那些事
HTTPS 与 HTTP2 协议分析