sqlserver 从等待状态判断系统资源瓶颈
一、 相关视图
2005、2008提供了以下三个视图供获取连接详细信息:
| DMV |
用处 |
参考 |
| Sys.dm_exec_requests |
返回有关在SQL Server中执行的每个请求的信息,包括当前的等待状态 |
https://docs.microsoft.com/zh-cn/sql/relational-databases/system-dynamic-management-views/sys-dm-exec-requests-transact-sql?view=sql-server-ver15 |
| Sys.dm_exec_sessions |
对于每个通过身份验证的会话都返回相应的一行。它是服务器范围的视图,显示所有活动用户连接和内部任务信息,还可查看当前系统负荷并标识相关会话。 |
https://docs.microsoft.com/zh-cn/sql/relational-databases/system-dynamic-management-views/sys-dm-exec-sessions-transact-sql?view=sql-server-ver15 |
| Sys.dm_exec_connections |
返回与SQL Server 实例建立的每个连接的详细信息(如验证方式、endpoint等) |
https://docs.microsoft.com/zh-cn/sql/relational-databases/system-dynamic-management-views/sys-dm-exec-connections-transact-sql?view=sql-server-ver15 |
注意:sys.sysprocesses是为了向后兼容,不支持多个活动结果集(MARS,应该了解同时开启多个结果集),建议使用以上3个DMV。
sys.dm_os_wait_stats可以返回SQL Server启动以来所有等待状态总的等待数和等待时间,是个累积值。
| 列名 | 描述 |
|---|---|
| wait_type | 等待类型的名称。有关详细信息,请参阅"等待类型"。 |
| waiting_tasks_count | 该等待类型的等待数,该计数器在每开始一个等待时便会增加。 |
| wait_time_ms | 该等待类型的总等待时间(毫秒)。该时间包括 signal_wait_time_ms。 |
| max_wait_time_ms | 该等待类型的最长等待时间。 |
| signal_wait_time_ms | 正在等待的线程从收到信号通知到其开始运行之间的时间差。 |
| pdw_node_id | 此分发所在节点的标识符。 |
下面整理一些工作中最常见的几种等待类型,完整版参考
https://docs.microsoft.com/zh-cn/sql/relational-databases/system-dynamic-management-views/sys-dm-os-wait-stats-transact-sql?view=sql-server-ver15
二、 LCK_XX类型
如果SQL Server有阻塞发生,经常会看到以“LCK_”开头的等待状态:
| 等待名称 |
说明 |
| LCK_M_BU |
正在等待获取大容量更新锁(BU) |
| LCK_M_IS |
等待获取意向共享锁(IS) |
| LCK_M_IU |
等待获取意向更新锁(IU) |
| LCK_M_IX |
等待意向排它锁(IX) |
| LCK_M_RIn_NL |
等待获取当前键值上的NULL锁以及当前键和上一个键之间的插入范围锁 |
| LCK_M_RIn_S |
等待获取当前键值上的共享锁以及当前键和上一个键之间的插入范围锁 |
| LCK_M_RIn_U |
等待获取当前键值上的更新锁以及当前键和上一个键之间的插入范围锁 |
| LCK_M_RIn_X |
等待获取当前键值上的排他锁以及当前键和上一个键之间的插入范围锁 |
| LCK_M_RS_S |
等待获取当前键值上的共享锁以及当前键和上一个键之间的共享范围锁 |
| LCK_M_RS_U |
等待获取当前键值上的更新锁以及当前键和上一个键之间的共享范围锁 |
| LCK_M_RX_S |
等待获取当前键值上的共享锁以及当前键和上一个键之间的排他范围锁 |
| LCK_M_RX_S |
等待获取当前键值上的共享锁以及当前键和上一个键之间的排他范围锁 |
| LCK_M_RX_U |
等待获取当前键值上的更新锁以及当前键和上一个键之间的排他范围锁 |
| LCK_M_RX_X |
等待获取当前键值上的排他锁以及当前键和上一个键之间的排他范围锁 |
| LCK_M_S |
等待获取共享锁 |
| LCK_M_SCH_M |
等待架构修改锁 |
| LCK_M_SCH_S |
等待获取架构共享锁 |
| LCK_M_SIU |
等待共享意向更新锁 |
| LCK_M_SIX |
等待获取共享意向排他锁 |
| LCK_M_U |
等待更新锁 |
| LCK_M_UIX |
等待更新意向排他锁 |
| LCK_M_X |
等待排他锁 |
三、 PAGEIOLATCH_%与WRITELOG
这类等待发生在内存缓冲池中的数据页要与磁盘上数据文件的数据页进行交互时,所以闩锁名称中包含IO。为保证不会有多个用户同时读取/修改内存中的数据页,SQL Server会对内存中的数据页加闩锁,称为PAGEIOLATCH_%。
根据不同的等待资源,%的值也不同,可能出现以下不同的等待:
- PAGEIOLATCH_NL:Null buffer page I/O latch
- PAGEIOLATCH_KP:Keep buffer page I/O latch
- PAGEIOLATCH_SH:Shared buffer page I/O latch
- PAGEIOLATCH_UP:Update buffer page I/O latch
- PAGEIOLATCH_EX:Exclusive buffer page I/O latch
- PAGEIOLATCH_DT:Destroy buffer page I/O latch
1. 等待发生过程示例
这里以最容易发生的PAGEIOLATCH_SH为例,看看这种等待是怎么发生的。
1)有一个用户请求,必须读取整张X表,由Worker X执行
2)Worker X在表扫描过程中发现要读取page 1:100
3)sqlserver发现page 1:100不在内存的数据缓冲池里
4)sqlserver在数据缓冲池找到一个page的空间,Worker X在上面申请EX模式latch,防止将数据加载入内存前有人读写该page
5)Worker X发起一个异步的IO请求,要求从数据文件中读取page 1:100
6)Worker X需要从内存中读取page 1:100,读取动作需要申请SH模式latch
7)由于Worker X之前申请的EX模式latch还没释放,因此申请SH模式latch的操作将被阻塞(自己阻塞自己)。由于Worker X在等待获取SH模式latch,等待类型即为PAGEIOLATCH_SH

8)当异步IO结束后,系统会通知Worker X,page 1:100已写入内存
9)Worker X释放EX模式latch,此时即可获得SH模式latch
10)Worker X在内存中读page 1:100,读取结束后,进行之后的工作

2. PAGEIOLATCH_%等待小结
可以看到,当发生PAGEIOLATCH类型的等待时,SQL Server一定是在等待某个I/O动作的完成。如果经常出现这类等待,说明磁盘速度不能满足要求,已经成为SQL Server的瓶颈。
更要强调的是,PAGEIOLATCH等待最常见分两大类:PAGEIOLATCH_SH和PAGEIOLATCH_EX
PAGEIOLATCH_SH
经常发生在用户想要访问一个数据页,但该数据页不在缓存中,SQL Server需要先把该页从磁盘读往内存。如果这个问题经常发生,说明内存很可能不够大,触发了SQL Server做了很多读取页面的工作,进而引发了磁盘读的瓶颈。此时主要是内存有瓶颈,磁盘只是内存压力的副产品。
PAGEIOLATCH_EX
经常发生在用户对数据页面做了修改,SQL Server要向磁盘回写时,意味着磁盘写的速度跟不上,和内存没直接关系。
WRITELOG
和磁盘有关的另一个等待状态是WRITELOG,说明任务当前正在等待将日志记录写入日志文件,通常也意味着磁盘写入速度跟不上。
四、 PAGELATCH_%
首先注意PAGELATCH_%虽然跟PAGEIOLATCH_%名字很像,但它们的成因是完全不一样的,可以说除了名字像其他没啥像了(类似buffer busy wait和free buffer wait)。
1. 成因
SQLServer为了解决在插入数据时物理层的插入冲突,引入了PAGELATCH_%类的latch。当任务要修改page时,必须先申请一个EX的latch,只有得到这个latch,才能修改page内容。
数据页的修改都是在内存中完成,所以时间应该非常短,可以忽略不计,而PAGELATCH只在修改过程中才出现,所以正常生存周期应该很短。如果在数据库中经常遇到,说明:
- SQLServer没有明显的内存和磁盘瓶颈。
- 可能有Hot Page:大量并发语句在修改同一张表,且修改集中在一个或少量几个页面,具体可以通过wait_resource字段看到
- 这种瓶颈无法通过提高硬件配置解决,只能通过修改表设计或者业务逻辑,让修改分散,提高并发性。
2. Hot page的缓解方法
- 对于频繁插入的表,避免在Identity的字段上建聚集索引,使同一时间插入有机会分散到不同的页面上。
- 如果一定要在Identity的字段上建聚集索引,建议在其他某个列上建若干个分区。
详细参考
https://support.microsoft.com/en-us/help/4460004/how-to-resolve-last-page-insert-pagelatch-ex-contention-in-sql-server
3. tempdb上的PAGELATCH:
这也是很常见的一种情况,数据库不仅在数据页修改时加latch,在数据文件的系统页(例如SGAM、PFS、GAM)发生修改时也会加latch,这些latch在某些情况下也会成为系统瓶颈。
在创建新表需要分配空间时,SQLServer同时要修改SGAM、PFS和GAM页面,把已分配的页面标志成已使用,所以这些页面都会有所修改。用户数据库一般不会出现频繁删表建表的情况,但在tempdb中,就很有可能出现。例如一个存储过程使用了临时表,这个存储过程被很多用户调用,就会有很多用户在tempdb创建临时表、处理完后又删除临时表,此时SGAM、PFS和GAM等页面上的latch就会成为系统瓶颈。
数据页的hot page可以通过调整表设计解决,那么系统页呢?
假设所有的cpu都在执行用户任务,最大任务数其实也不会超过服务器CPU核数。也就是说,同一时间最多只能有服务器CPU核数个任务并发访问tempdb,所以只要将任务尽量平均地分配到tempdb各个数据文件,就能尽量避免该问题。
总结一下,解决方法的要点是:
- 建立多个tempdb文件(建议同CPU核数),并且大小必须相同,打散IO压力。
- 严格防止tempdb空间用尽引发数据文件自动增长。因为自动增长只会增长其中一个文件,造成只有一个文件有空闲(相当于只有一个文件可用),此后所有任务又集中到这个文件上,它又变成了瓶颈。
- 使用sp_helpfile可以查看数据文件情况
- 启用1117跟踪标记,sqlserver在自动增长数据文件时会尝试对所有文件进行同样大小的增长。
五、 其他资源等待
除了上面的最常见的资源等待,用户还可能遇到以下等待。
1. LATCH_%
在sqlserver中,除了buffer latch,其他资源上也会出现latch。正常情况下,这些latch的申请和释放都是很快的,用户应该不会看到相应等待。
Latch等待常见原因:
1)某个先前的任务出现了访问越界异常(Access Violation),SQLServer强制终止了该任务,但是没有完全将它申请的资源释放干净,使某些latch成为孤儿,导致后面任何任务要申请同样的资源都会被阻塞。这类问题容易判断:只要打开sqlserver错误看看之前有没有出现过Access Violation即可,但是一般无法从用户层面解决,只能重启sqlserver服务。
2)同时发生其他资源瓶颈,如内存、线程调用、磁盘等,而latch等待只是一个衍生的等待。
3)当某个数据文件空间用尽,做自动增长的时候,其他任务必须等待,这时也会出现latch资源等待。
4)在一些特殊情况下,可能是SQLServer自己没有处理好,没有使用比较优化的算法(相当于bug),使得用户比较容易遇到等待,一些补丁就曾修复过这类问题。
可以看到,一般latch等待都是由其他问题衍生而来。当数据库中出现大量latch等待时,首先要检查SQLServer是否健康运行,看错误日志是否有出现过异常,是否有其他资源瓶颈。另外,将sqlserver升级到最新版本,通常是推荐的做法。
2. ASYNC_NETWORK_IO
当sqlserver要返回结果集给客户端时,会先将结果集填充到输出缓存(output cache),同时网络层会开始将输出缓存里的数据打包,由客户端接收。如果sqlserver返回结果集的速度快过客户端接收速度,当结果集较大时,就会出现输出缓存被填满,sqlserver没地方填充结果集的问题。此时,任务就会进入ASYNC_NETWORK_IO的等待。注意这个等待一般不是数据库的问题,而是客户端由于各种各样的没有及时取走数据,因此调整数据库配置一般不会有大的帮助。
ASYNC_NETWORK_IO等待常见原因及优化建议:
- 网络层瓶颈当然是一个可能的原因
- 是否真有必要返回如此大量的结果集。通常大结果集对应用程序的影响远远大于sqlserver,如果应用要返回上百万千万行结果展示给用户,先崩溃的不会是sqlserver而是应用程序和用户。
- 应用程序端的性能问题。其实这才是最常见的问题,sqlserver将结果集打包好发向客户端后,要等客户端确认收到,才会接着发下一个包。如果客户端确认很慢,sqlserver也不得不慢慢发。至于为什么客户端确认很慢,可能是客户端有意只取开头的一部分数据(这就回到前一个问题,是否真有必要返回如此大量的结果集),或者客户端遇到CPU、内存、磁盘等资源瓶颈,运行得很慢
- 分布式死锁。常见于长时间的ASYNC_NETWORK_IO等待并且在sql内部造成了阻塞。
3. 内存相关等待
当用户任务申请内存暂时申请不到时,会出现一些特殊的等待状态:
- CMEMTHREAD
- SOS_RESERVEDMEMBLOCKLIST
- RESOURCE_SEMAPHORE_QUERY_COMPLIE
1)CMEMTHREAD
在一个时间点,只有一个连接能往一块缓存区申请/释放内存,当多个用户想要同时往同一块缓存区申请/释放内存时,只有一个连接能成功,其他的必须等待,等待的事件就是CMEMTHREAD。
这种等待通常只发生在并发特别高的sqlserver里,这些并发的连接通常大量使用每次执行都需编译的动态t-sql语句。
解决方法
- 看能否降低并发量
- 修改客户端行为,使用存储过程或参数化sql以减少编译量,增加执行计划重用度
2)SOS_RESERVEDMEMBLOCKLIST
如果sql语句包含大量参数、或者in子句包含大量值,它的执行计划可能超过8KB,需要申请multi-page区域来存储,当申请暂时不能得到满足时,等待的就是这个事件。这个问题更常见于32位机器,因为32位机器multi-page区域很小而且远小于buffer pool,如果multi-page有内存压力而buffer pool没有,并不会触发lazy writer刷数据清理内存。
解决方法
- 避免使用包含大量参数、或者in子句包含大量值的sql,这能从根本上解决问题
- 定期运行DBCC FREEPROCCACHE语句,手动清除缓存的执行计划。能暂时缓解,在生产环境谨慎操作。
- 扩展multi-page区域大小或使用64位机器,能延迟问题发生时间
3)RESOURCE_SEMAPHORE_QUERY_COMPLIE
如果sql或存储过程过于复杂,编译所需的内存可能超乎你的想象。sqlserver为编译内存设了一个上限,当在编译的sql使用内存达到这个上限后,后面的语句只能等前面的语句编译完释放内存后才能继续编译,此时等待的事件就是RESOURCE_SEMAPHORE_QUERY_COMPLIE。
解决方法
- 修改客户端行为,使用存储过程或参数化sql以减少编译量,增加执行计划重用度
- 避免使用过于复杂的sql,降低编译需要的内存量
- 定期运行DBCC FREEPROCCACHE语句,手动清除缓存的执行计划。能暂时缓解,在生产环境谨慎操作。
4. SQLTRACE_%
对于繁忙的SQLServer,开启SQL Trace很可能对性能产生负面影响。如果经常出现这种等待,除非迫不得已,否则应该立刻停止SQL Trace。
六、 最后一道瓶颈:SOS_SCHEDULER_YIELD
这个问题最明显的特征就是大量任务处于runnable状态,等待类型为SOS_SCHEDULER_YIELD。如果出现这种状态,说明很多任务可以运行但没在运行,这同样会严重影响sqlserver性能。
任务的状态可以通过sys.dm_exec_requests的task_state列和sys.sysprocesses的status列查看,如果经常看到很多任务状态是runnable,就要严肃对待了。正常的SQLServer哪怕很忙,也不该经常看到runnable的任务,连running的状态都不应该很多。
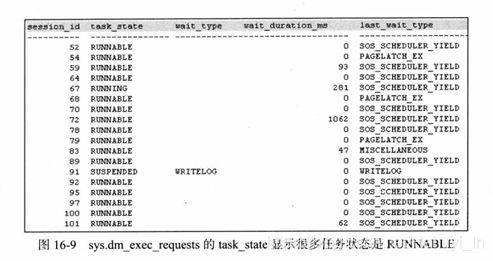
如果遇到没有报17883/17884之类的警告,出现非常多的runnable任务通常可能有两种原因:
1. SQLServer CPU接近100%
此时真的是没有足够cpu来及时处理用户的并发任务。应该优化最耗CPU资源的语句,或者紧急加CPU。
2. 自旋锁(2008后基本不会有)
此时CPU并不高,小于50%,为什么还有CPU资源但任务无法运行呢?这是因为SQLServer除了lock和latch之外,还有一种更轻量级的spinlock(自旋锁)。对于一些通常很快就能得到和释放资源,SQLServer会选择让线程在cpu上稍微等待一下(即所谓的自旋),而不是cpu资源让出来。由于很快就能得到等待的资源,这样的处理能减少CPU上线程的切换,更高效。
运行以下语句可查看sqlserver在所有自旋锁上的等待次数
DBCC SQLPERF(SPINLOCKSTATS)在2005版本64位SQL Server上,当内存比较充裕时,会缓存很多执行计划和很多执行计划安全上下文。在memory clerk里用TokenAndPermUserStore表示,当这段内存比较大时,并发用户会容易遇到一种叫MUTEX的自旋锁。可以参考:http://suppot.microsoft.com/kb/927396。这种问题只在安全上下文缓存得太多时才容易发生,所以定期运行以下语句能有效防止,并且对系统性能也没什么坏的影响:
DBCC FREESYSTEMCACHE(TokenAndPermUserStore)也可以以-T4618和-T4610两个参数启动SQLServer,让SQLServer使用另一种缓存管理机制。
2008开始的版本对安全上下文管理已经改进,自旋锁问题基本已很少遇到。
七、 用户请求生命周期及各阶段常见等待
最后总结一下一个用户请求在其生命周期中大致会经过哪些阶段,以及在各阶段可能需要等待的资源。
1. 客户端发出请求指令,经过网络层,SQL Server接收到
如果指令比较长或者比较多,客户端发指令的快慢就会影响SQLServer接收的速度,网络传输速度也会有影响。
对第一条,将上百个小指令合并成几个大的批处理可能提升性能;对第二条,把大的批处理/语句写成存储过程,减少网络传输,也会对性能有所帮助。
2. SQL Server进行检查、编译,生成执行计划或找到缓存的计划重用
这一步耗费资源的种类比较多:
- CPU:做检查、编译、生成计划都需要计算,这一步耗费CPU资源比较多,尤其是sql复杂需要大量计算时。
- 内存:对于非常长sql,或者由几万几十万语句组成的批处理,要耗费大量内存。如果内存紧张,一般就会出现前面提到的内存等待,或者直接报701错误。
- 表上的架构锁(schema lock):在编译时,要防止对架构进行修改。如果大量用户并发做编译操作或者有操作申请了级别很高的锁,编译时可能遇到阻塞。

- 确认缓存中是否有执行计划可用时,要在内存中进行搜索,可能会产生自旋锁。
3. 运行指令
得到执行计划后就进入运行阶段,通常这步耗时最长,用到的资源也最多。在这一步要做很多事情:
- SQLServer首先为指令的运行申请内存。
需要的内存大小与sql的长度、复杂度有关,如果同时需要执行很多复杂sql,可能新sql在申请内存时就会遇到上面所说的内存等待。
- 如果发现要访问的数据不在内存中。
要将数据从磁盘读到内存,如果发现内存没有足够的空闲页面存放所有数据,通常的等待状态是:PAGEIOLATCH_%。
- 按照执行计划scan或seek内存中的数据页面,找定需要的记录。
这一步需要申请各种各样的锁,以实现事务隔离,可能会引起阻塞,遇到LCK_%相关等待。
- 指令可能还要做一些连接或者计算工作(sum、max、sort等)
这一步主要使用CPU。如果执行计划不够优化、计算量庞大,而又没有等待其他资源,通常CPU使用率会较高。
- 根据指令内容、执行计划和数据量,可能还会在tempdb创建临时对象
此时有可能出现tempdb瓶颈。
- 如果指令需要修改数据记录,SQLServer会修改内存缓冲区里的页面内容。
由于对象在内存中,不会触发磁盘写入,若大量修改同一页面,容易导致hot page,出现PAGELATCH_%等待。
- 在提交事务之前,SQLServer必须将相应的日志记录按照顺序写入日志文件,此时可能出现WRITELOG等待。
- 将结果集返回给客户端,此时容易出现ASYNC_NETWORK_IO等待
以上动作都要先在sqlos中拿到Worker(Thread),这个Worker能还要排上scheduler,才能在CPU上运行。如果:
- 如果所有的Worker都在忙,没有空闲Worker,那么任务就要等待一个Worker出现。此时等待状态是THREADPOOL。而sys.dm_os_schedulers.work_queue_count的值会不等于0。
- 任务拿到worker,但scheduler正在运行其他Worker,任务会进入等待队列。此时任务状态是runnable,而sys.dm_os_schedulers.runnable_tasks_count>1。
- 任务拿到scheduler,进入running状态,如果非常耗CPU,会出现CPU使用率高的现象。
总之,从任务当前等待状态可以大概知道它当前运行到哪一步,也可以分析出sqlserver可能存在的资源瓶颈。在遇到性能问题时,先查看sys.dm_exec_requests这类DMV中各连接的状态,对定位问题很有帮助。
参考:《sqlserver 2012 实施与管理实战指南》