1. Python编码解码
将文本转换为二进制数据就是编码,将二进制数据转换为文本就是解码。编码和解码要按照一定的规则进行,这个规则就是字符集。
# -*- coding: utf-8 -*-
# 本文件应该保存为utf-8编码,否则会报错
str = "中文测试"
print(f'Unicode字符串为"{str}"')
byte0 = str.encode("utf-8")
print(f'Unicode字符串"{str}"以utf-8编码得到字节串[{byte0}]')
str0 = byte0.decode("utf-8")
print(f'将utf-8字节串[{byte0}]解码得到字符串"{str0}"')
byte1 = str.encode("gbk")
print(f'Unicode字符串"{str}"以gbk编码得到字节串[{byte1}]')
str1 = byte1.decode("gbk")
print(f'将gbk字节串[{byte1}]解码得到Unicode字符串"{str1}"')
print(f'以文本方式将Unicode字符串"{str}"写入a.txt')
with open("a.txt", "w", encoding="gbk") as f:
f.write(str)
print("以文本方式读取a.txt的内容")
with open("a.txt", "r", encoding="gbk") as f:
print(f.read())

默认编码可以通过sys.getdefaultencoding()来查看Python解释器会用的默认编码:
import sys
encoding = sys.getdefaultencoding()
print(f"{encoding}")
2. 文件操作
2.1 普通文件操作
f = open("a.txt") #打开文件,得到一个文件句柄,并赋值给一个变量
print(f.read()) #打印读取文件的内容
f.close() #关闭文件
open函数原型如下:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
其中:
(1)参数file是一个表示文件名称的字符串,如果文件不在程序当前的路径下,就需要在前面加上相对路径或绝对路径。
(2)参数mode是一个可选字参数,指示打开文件的方式,若不指定,则默认为以读文本的方式打开文件。
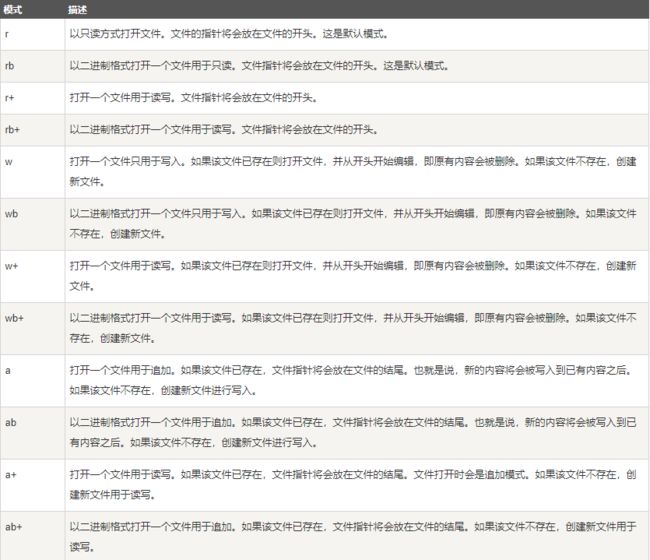
默认的打开方式是'rt'(mode='rt')。Python是区分二进制方式和文本方式的,当以二进制方式打开一个文件时(mode参数后面跟'b'),返回一个未经解码的字节对象:当以文本方式打开文件时(默认是以文本方式打开,也可以mode参数后面跟't'),返回一个按系统默认编码或参数encoding传入的编码来解码的字符串对象。
(3)buffering是一个可选的参数,buffering=0表示关闭缓冲区(仅在二进制方式打开时可用):buffering=1表示选择行缓冲区(仅在文本方式打开时可用):buffering大于1时,其值代表固定大小的块缓冲区的大小。当不指定该参数时,默认的缓冲策略是这样的:二进制文件使用固定大小的块缓冲区,文本文件使用行缓冲区。
# -*- coding: utf-8 -*-
f = open("wb.txt", "w", encoding="utf-8")
f.write("测试w方式写入,如果文件存在,则清空内容后写入:如果文件不存在,则创建\n")
f.close()
f = open("wb.txt", "a", encoding="utf-8")
f.write("测试a方式写入,如果文件存在,则在文件内容后最后追加写入;如果文件不存在,则创建")
f.close()
f = open("wb.txt", "r", encoding="utf-8")
# 以文本方式读,f.read()返回字符串对象
data = f.read()
print(type(data))
print(data)
f.close()
f = open("wb.txt", "rb")
# 以文本方式读,f.read()
data = f.read()
print(type(data))
print(data)
print('将读取的字符对象解码:')
print(data.decode('utf-8'))
f.close()

从上面的例子可以看出,以二进制读取文件时,读取的是文件字符串的编码(以encoding指定的编码格式进行的编码),将读取的字节对象解码,可以得出原字符串。
需要注意以下几点:
(1)记得使用完毕后及时关闭文件,释放资源,如f.close(),否则就会导致操作系统打开的文件还没有关闭,白白占用资源。使用with关键字来帮我们管理上下文,系统会自动为我们关闭文件和处理异常,如下面两行代码即可完成安全的写操作。
with open('a.txt', 'w') as f:
f.write("hello word")
(2)open()函数是由操作系统打开文件,如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统默认的编码:在Windows下是gbk,在Linux下是utf-8。若要保证不乱码,就必须让读取文件和写入文件使用的编码一致。
常见的文件操作方法:
f.readable():判断有读取文件的方法
f.read([size]):size为读取的长度,以byte为单位,如果未给定或为负则读取所有
f.readline([size]) :读取整行,包括 "\n" 字符
f.readlines([size]) : 返回一个list,其实内部是调用readline()实现的
f.write(str) : 把str写到文件中,write()不主动加换行符
f.writelines(str) : 把多行内容一次写入
f.close() : 关闭文件
f.flush() : 把缓冲区的内容写入硬盘
f.tell() : 当前文件操作标记的位置
f.next() : 返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的
f.seek(offset[,whence]) :将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。whence参数,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾
在文件中定位示例:
f = open("tmp.txt", "rb+")
a = f.write(b"abcdefghi")
print(f"一共有{a}个字节")
b = f.seek(5) #移动到文件的第六个字节
print(f"第六个字节:{b}")
print(f.read(1))
c = f.seek(-3,2) #移动到文件的倒数第三个字节
print(f"倒数第三个字节:{c}")
print(f.read(1))

基于seek实现类似Linux命令tail -f的功能:
# encoding=utf-8
import time
with open('tmp.txt', 'rb') as f:
f.seek(0, 2) # 将光标移动到文件末尾
while True: # 实时显示文件新增加的内容
line = f.read()
if line:
print(line.decode('utf-8'), end='')
else:
time.sleep(0.2) # 读取完毕后短暂的睡眠
当tmp.txt追加新的内容时,新内容会被程序立刻打印出来。
2.2 大文件的读取
当文件较小时,我们可以一次性全部读入内存,对文件的内容作出任意修改,再保存至磁盘,这一过程会非常快。
将文件a.txt中的字符串str1替换为str2:
with open('a.txt') as read_f,open('.a.txt.swap', 'w') as write_f:
data=read_f.read() #全部读入内存,如果文件很大,则会很卡
data=data.replace('str1', 'str2') #在内存中完成修改
write_f.write(data) #一次性写入新文件
os.remove('a.txt')
os.rename('.a.txt.swap', 'a.txt')
当文件很大时,如GB级的文本文件,上面的代码运行将会非常缓慢,此时我们需要使用文件的可迭代方式将文件的内容逐行读入内存,再逐行写入新文件,最后用新文件覆盖源文件。
对大文件进行读写:
import os
with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
for line in read_f: #对可迭代对象f逐行操作,防止内存溢出
line=line.replace('str1', 'str2')
write_f.write(line)
os.remove('a.txt')
os.rename('.a.txt.swap', 'a.txt')
大文件为a.txt,当打开文件时,会得到一个可迭代对象read_f,对可迭代对象进行逐行读取,可防止内存溢出,也会加快处理速度。
处理大数据还有多种方法:
(1)通过read(size)增加参数,指定读取的字节数。
while True:
block = f.read(1024)
if not block:
break
(2)通过readline,每次只读一行。
while True:
line = f.readline()
if not line:
break

3. 序列化和反序列化
- 序列化:将数据结构或对象转换成二进制串的过程。
- 反序列化:将在序列化过程中所生成的二进制串转换成数据结构或对象的过程。
序列化实例:
# encoding:utf-8
import pickle
# 使用pickle模块将数据对象保存到文件
# 字符串
data0 = "hello world"
# 列表
data1 = list(range(20))[1::2]
# 元组
data2 = ("x", "y", "z")
# 字典
data3 = {"a": data0, "b": data1, "c": data2}
print(data0)
print(data1)
print(data2)
print(data3)
output = open("data.pkl", "wb")
# 使用默认的protocol
pickle.dump(data0, output)
pickle.dump(data1, output)
pickle.dump(data2, output)
pickle.dump(data3, output)
output.close()

反序列化实例:
# encoding=utf-8
import pickle
# 使用pickle模块从文件中重构Python对象
pkl_file = open("data.pkl", "rb")
data0 = pickle.load(pkl_file)
data1 = pickle.load(pkl_file)
data2 = pickle.load(pkl_file)
data3 = pickle.load(pkl_file)
print(data0)
print(data1)
print(data2)
print(data3)
pkl_file.close()

可以看出运行结果与序列化实例运行的结果完全一致。