51.JNI和NDK
JNI是Java调用Native 语言的一种特性,属于Java,Java本地接口,使Java与本地其他类型语言交互(C++)
实现步骤:在Java中声明Native方法,编译该文件得到.class文件,通过javah命令导出JNI头文件(.h文件),使用Java需要交互的本地代码实现子啊Java中声明的Native方法,编译so文件,通过Java执行Java程序,最终实现Java调用本地代码
NDK(Native Develop Kit):Android开发工具包,属于Android。
作用:快速开发C、C++动态库,并自动将so文件和应用打包成APK,即可通过NDK在Android中使用JNI与本地代码(C、C++)交互(Android开发需要本地代码C、C++实现)
特点:运行效率高,代码安全性高,功能拓展性好,易于代码复用和移植。
使用步骤:①配置NDK环境;②创建Android项目,并于NDK进行关联;③在Android项目中声明所需调用的Native方法;④使用该Native方法;⑤通过NDK build命令编译产生so文件;⑥编译AS工程,实现调用本地代码。
JNI和NDK的关系:JNI实现目的,NDK是Android实现JNI的手段,即在AS开发环境中通过NDK从而实现JNI功能。
52.常用的设计模式及其实现思想和作用
转载文章:23种设计模式全解析 - codeTao - 博客园
①单例模式:单例对象能保证在一个JVM中,该对象只有一个实例存在。

②工厂模式
一个抽象产品类,可以派生出多个具体产品类。 一个抽象工厂类,可以派生出多个具体工厂类。每个具体工厂类只能创建一个具体产品类的实例。
抽象工厂模式:多个抽象产品类,每个抽象产品类可以派生出多个具体产品类。 一个抽象工厂类,可以派生出多个具体工厂类。 每个具体工厂类可以创建多个具体产品类的实例,也就是创建的是一个产品线下的多个产品。
③适配器模式
将某个类的接口转换成客户端期望的另一个接口表示,目的是消除由于接口不匹配所造成的类的兼容性问题。主要分为三类:类的适配器模式、对象的适配器模式、接口的适配器模式。
④装饰模式(Decorator)
顾名思义,装饰模式就是给一个对象增加一些新的功能,而且是动态的,要求装饰对象和被装饰对象实现同一个接口,装饰对象持有被装饰对象的实例。
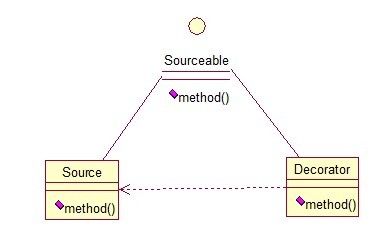
Source类是被装饰类,Decorator类是一个装饰类,可以为Source类动态的添加一些功能。
装饰器模式的应用场景:
1、需要扩展一个类的功能。
2、动态的为一个对象增加功能,而且还能动态撤销。(继承不能做到这一点,继承的功能是静态的,不能动态增删。)
缺点:产生过多相似的对象,不易排错!
⑤代理模式(Proxy):多一个代理类出来,替原对象进行一些操作。
⑥桥接模式(Bridge):桥接模式就是把事物和其具体实现分开,使他们可以各自独立的变化。桥接的用意是:将抽象化与实现化解耦,使得二者可以独立变化。
⑦观察者模式:一个目标物件管理所有相依于它的观察者物件,并且在它本身的状态改变时主动发出通知。这通常透过呼叫各观察者所提供的方法来实现。此种模式通常被用来实现事件处理系统。
⑧访问者模式:一种分离对象数据结构与行为的方法,通过这种分离,可达到为一个被访问者动态添加新的操作而无需做其它的修改的效果。
53.HashMap、 HashTable、HashSet的异同
转载文章:HashSet HashTable HashMap的区别 及其Java集合介绍 - ywl925 - 博客园
①HashSet是Set的一个实现类,HashMap是Map的一个实现类,同时HashMap是HashTable的替代品
②HashSet以对象作为元素,而HashMap以(key-value)的一组对象作为元素,且HashSet拒绝接受重复的对象。HashMap可以看作三个视图:key的Set,value的Collection,Entry的Set。 这里HashSet就是其实就是HashMap的一个视图。
HashSet内部就是使用HashMap实现的,和HashMap不同的是它不需要Key和Value两个值。
HashMap是一个数组和链表的结合体,新加入的放在链头,重复的key不同的alue被新value替代
③继承不同
public class Hashtable extends Dictionary<> implements Map<>
public class HashMap extends AbstractMap<> implements Map<>
④HashTable 方法同步,而HashMap需要自己增加同步处理。
⑤HashTable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。用containsKey()方法来判断是否存在某个键。
⑥两个遍历方式的内部实现上不同。
HashTable、HashMap都使用了 Iterator。而由于历史原因,HashTable还使用了Enumeration的方式 。
⑦哈希值的使用不同
HashTable直接使用对象的hashCode,HashTable中hash数组默认大小是11,增加的方式是 old*2+1。
而HashMap重新计算hash值,HashMap中hash数组的默认大小是16,而且一定是2的指数。
如何实现HashMap线程同步?
①使用 java.util.Hashtable 类,此类是线程安全的。
②使用 java.util.concurrent.ConcurrentHashMap,此类是线程安全的。
③使用 java.util.Collections.synchronizedMap() 方法包装 HashMap object,得到线程安全的Map,并在此Map上进行操作。
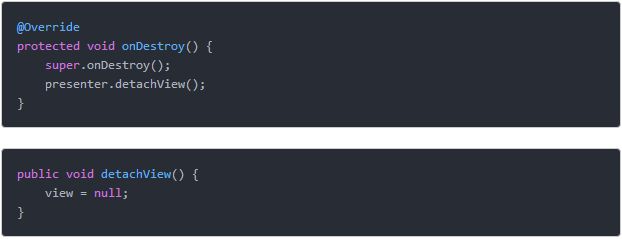
54.Android 中内存泄漏原因及优化方案?
文章转载:Android 中内存泄漏的原因和解决方案 -
①非静态内部类造成的内存泄漏 非静态类会持有外部类的引用,如果这个内部类比外部类的生命周期长,在外部类被销毁时,内部类无法回收,即造成内存泄漏;
②外部类中持有非静态内部类的静态对象 保持一致的生命周期,将内部类对象改成非静态;
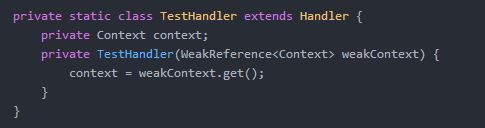
③Handler 或 Runnable 作为非静态内部类 Handler 和 Runnable 作为匿名内部类,都会持有 Activity 的引用,由于 Handler 和 Runnable 的生命周期比 Activity 长,导致Activity 无法被回收,从而造成内存泄漏。 解决办法:将Handler 和 Runnable 定义为静态内部类,在Activity 的onDestory()方法中调用Handler 的 removeCallbacks 方法来移除 Message。
还有一种特殊情况,如果 Handler 或者 Runnable 中持有 Context 对象,那么即使使用静态内部类,还是会发生内存泄漏。解决办法:使用弱引用
④其他内存泄漏情况:比如BraodcastReceiver 未注销,InputStream 未关闭,再代码中多注意注销或关闭。
55.LeakCanary内存优化
参考文章:LeakCanary原理解析 -
①项目如何使用LeakCanary

LeakCanary.enableDisplayLeakActivity(context);内存溢出图标,图标以通知的形式显示内存溢出
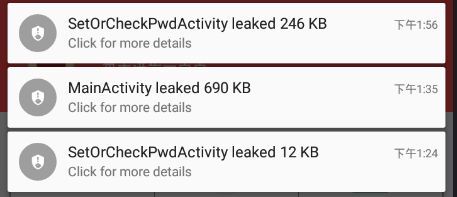
②工作机制
LeakCanary.install() 会返回一个预定义的 RefWatcher,同时也会启用一个 ActivityRefWatcher,用于自动监控调用Activity.onDestroy() 之后泄露的 activity。
1.RefWatcher.watch() 创建一个 KeyedWeakReference 到要被监控的对象。
2.然后在后台线程检查引用是否被清除,如果没有,调用GC。
3.如果引用还是未被清除,把 heap 内存 dump 到 APP 对应的文件系统中的一个 .hprof 文件中。
4.在另外一个进程中的 HeapAnalyzerService 有一个 HeapAnalyzer 使用HAHA 解析这个文件。
5.得益于唯一的 reference key, HeapAnalyzer 找到 KeyedWeakReference,定位内存泄露。
6.HeapAnalyzer 计算 到 GC roots 的最短强引用路径,并确定是否是泄露。如果是的话,建立导致泄露的引用链。
7.引用链传递到 APP 进程中的 DisplayLeakService, 并以通知的形式展示出来。
56.多线程、线程池
参考文章:Java中的多线程你只要看这一篇就够了 - Givefine - 博客园
线程的并行和并发
并行:多个cpu实例或者多台机器同时执行一段处理逻辑,是真正的同时。
并发:通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。并发往往在场景中有公用的资源,那么针对这个公用的资源往往产生瓶颈,我们会用TPS或者QPS来反应这个系统的处理能力。
线程安全:多个线程访问同一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他操作,调用这个对象的行为都可以获得正确的结果,那么这个对象就是线程安全的。
线程同步:即当有一个线程在对内存进行操作时,其他线程都不可以对这个内存地址进行操作,直到该线程完成操作, 其他线程才能对该内存地址进行操作,而其他线程又处于等待状态,实现线程同步的方法有很多,临界区对象就是其中一种。
Java通过Executors提供四种线程池(from 百度)
newCachedThreadPool——创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool——创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool——创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor——创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
参考文章:Java并发编程:线程池的使用 - Matrix海子 - 博客园
①线程池中的线程初始化
创建线程池后,线程池中没有线程,需要提交任务才会创建线程。
prestartCoreThread():初始化一个核心线程;
prestartAllCoreThreads():初始化所有核心线程
②workQueue,任务缓存队列,用来存放等待执行的任务
workQueue的类型为BlockingQueue
1)ArrayBlockingQueue:基于数组的先进先出队列,此队列创建时必须指定大小;
2)LinkedBlockingQueue:基于链表的先进先出队列,如果创建时没有指定此队列大小,则默认为Integer.MAX_VALUE;
3)SynchronousQueue:这个队列比较特殊,它不会保存提交的任务,而是将直接新建一个线程来执行新来的任务。
③任务拒绝策略
当线程池的任务缓存队列已满或线程数目达到maximumPoolSize,还有任务来时会采用任务拒绝策略
1)ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
2)ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
3)ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
4)ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
④线程池的关闭
1)shutdown():不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务
2)shutdownNow():立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务
⑤线程池容量的动态调整
1)setCorePoolSize:设置核心池大小
2)setMaximumPoolSize:设置线程池最大能创建的线程数目大小
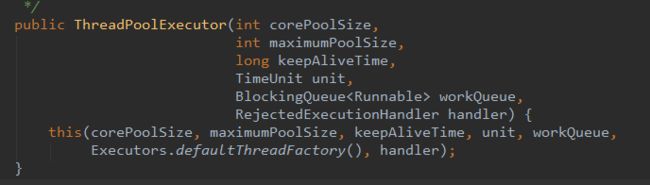
参考文章:由浅入深理解Java线程池及线程池的如何使用 - Janti - 博客园
corePoolSize :线程池的核心池大小,在创建线程池之后,线程池默认没有任何线程。
当有任务过来的时候才会去创建创建线程执行任务。换个说法,线程池创建之后,线程池中的线程数为0,当任务过来就会创建一个线程去执行,直到线程数达到corePoolSize之后,就会被到达的任务放在队列中。(注意是到达的任务)。换句更精炼的话:corePoolSize表示允许线程池中允许同时运行的最大线程数。
如果执行了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有核心线程。
maximumPoolSize :线程池允许的最大线程数,他表示最大能创建多少个线程。maximumPoolSize肯定是大于等于corePoolSize。
keepAliveTime :表示线程没有任务时最多保持多久然后停止。默认情况下,只有线程池中线程数大于corePoolSize时,keepAliveTime才会起作用。换句话说,当线程池中的线程数大于corePoolSize,并且一个线程空闲时间达到了keepAliveTime,那么就是shutdown。
Unit:keepAliveTime的单位。
workQueue:一个阻塞队列,用来存储等待执行的任务,当线程池中的线程数超过它的corePoolSize的时候,线程会进入阻塞队列进行阻塞等待。通过workQueue,线程池实现了阻塞功能
threadFactory:线程工厂,用来创建线程。
handler :表示当拒绝处理任务时的策略。
在java doc中,并不提倡我们直接使用ThreadPoolExecutor,而是使用Executors类中提供的几个静态方法来创建线程池:
Executors.newCachedThreadPool(); //创建一个缓冲池,缓冲池容量大小为Integer.MAX_VALUE
Executors.newSingleThreadExecutor(); //创建容量为1的缓冲池
Executors.newFixedThreadPool(int); //创建固定容量大小的缓冲池
57.腾讯 Bugly
腾讯公司为移动开发者开放的服务之一,面向移动开发者提供专业的 Crash 监控、崩溃分析等质量跟踪服务。Bugly 能帮助移动互联网开发者更及时地发现掌控异常,更全面的了解定位异常,更高效的修复解决异常。
针对移动应用,腾讯 Bugly 提供了专业的 Crash、Android ANR ( application not response)、iOS 卡顿监控和解决方案。移动开发者 ( Android / iOS ) 可以通过监控,快速发现用户在使用过程中出现的 Crash (崩溃)、Android ANR 和 iOS 卡顿,并根据上报的信息快速定位和解决问题。
58.Glide
github 地址
项目依赖Glide,在app build.gradle 中配置 compile'com.github.bumptech.glide:glide:3.7.0'
使用glide3.7版本,更高版本或出现异常:Error:Failed to resolve: com.android.support:support-annotations:27.0.2
Glide缓存机制
内存存缓存的 读存都在Engine类中完成。内存缓存使用弱引用和LruCache结合完成的,弱引用来缓存的是正在使用中的图片。图片封装类Resources内部有个计数器判断是该图片否正在使用。
Glide内存缓存的流程
读:是先从lruCache取,取不到再从弱引用中取;
存:内存缓存取不到,从网络拉取回来先放在弱引用里,渲染图片,图片对象Resources使用计数加一;
渲染完图片,图片对象Resources使用计数减一,如果计数为0,图片缓存从弱引用中删除,放入lruCache缓存。
参考文章:
Google推荐——Glide使用详解 -
Glide 系列(四) Glide缓存机制 - 野生的安卓兽 -
59.Fresco
github 地址
项目依赖Glide,在app build.gradle 中配置:implementation'com.facebook.fresco:fresco:1.9.0'
https://github.com/desmond1121/Fresco-Source-Analysis
参考文章:Fresco的使用小结 -
https://blog.csdn.net/yw59792649/article/details/78921025
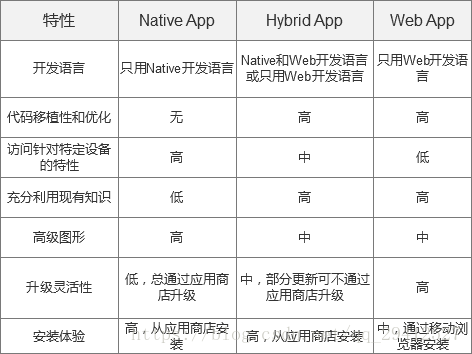
60.React Native
混合开发技术移动开发-混合App介绍 - Primise7的博客 - CSDN博客
上一篇:Android基础知识总结(五)
下一篇:Android GreenDao数据库
每天进步一点点。。。(2019-05-11)