算法练习题之单向链表增删改查
一、前言
HaspMap的使用频率非常高,相信在每一个Java项目都能见到HashMap的身影。HashMap的重要性也成为了Java面试中必问的>数据结构,因此我们很有必要了解HashMap的原理结构。
HashMap可以看做为数组和链表组合而的数据结构,看下图:
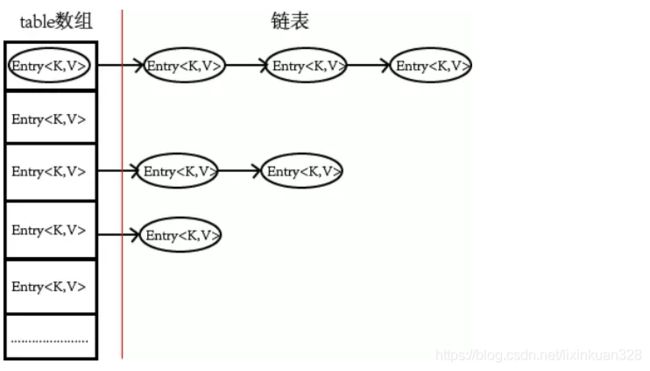
HashMap结构
想要弄清楚HashMap,首先数组和链表有一定的了解,相信大家都十分了解数组,那么下面重点实现一下单向链表的增,删,改,查功能。
二、单链表简介
-
概念介绍
链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素的映象) + 指针(指示后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。
以“结点的序列”表示线性表称作线性链表(单链表),单链表是链式存取的结构。 -
链接存储方法
链接方式存储的线性表简称为链表(Linked List)。链表的具体存储表示为:
① 用一组任意的存储单元来存放线性表的结点(这组存储单元既可以是连续的,也可以是不连续的)
② 链表中结点的逻辑次序和物理次序不一定相同。为了能正确表示结点间的逻辑关系,在存储每个结点值的同时,还必须存储指示其后继结点的地址(或位置)信息(称为指针(pointer)或链(link))
链式存储是最常用的存储方式之一,它不仅可用来表示线性表,而且可用来表示各种非线性的数据结构。 -
结点结构
┌───┬───┐
│data │next │
└───┴───┘
data域--存放结点值的数据域
next域--存放结点的直接后继的地址的指针域(链域)
链表通过每个结点的链域将线性表的n个结点按其逻辑顺序链接在一起的,每个结点只有一个链域的链表称为单链表(Single Linked List)。 -
头指针head和终端结点
单链表中每个结点的存储地址是存放在其前趋结点next域中,而开始结点无前趋,故应设头指针head指向开始结点。链表由头指针唯一确定,单链表可以用头指针的名字来命名。
终端结点无后继,故终端结点的指针域为空,即NULL。

三、实现单链表
1、创建单链表
public class SingleList {
private Node head; //头结点
/**
* 单链表结点类
*/
public class Node {
T value; //数据域
Node next; //指针域
public Node(T value) {
this.value = value;
next = null;
}
}
}
2、链表简单操作
-
头部插入结点
实现思路:如果链表没有头结点,新结点直接成为头结点;否则新结点的next直接指向当前头结点,并让新结点成为新的头结点。
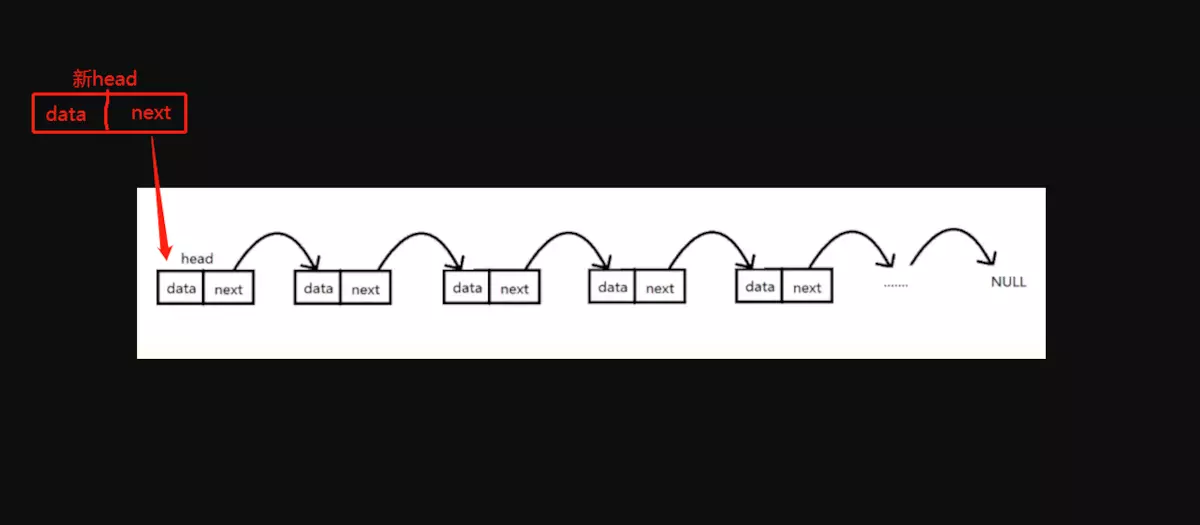
头部插入结点
/**
* 添加结点至链表头部
*
* @param value
*/
public void addHeadNode(T value) {
Node newNode = new Node(value);
//头结点不存在,新结点成为头结点
if (head == null) {
head = newNode;
return;
}
//新结点next直接指向当前头结点
newNode.next = head;
//新结点成为新的头结点
head = newNode;
}
-
尾部插入结点
实现思路:如果链表没有头结点,新结点直接成为头结点;否则需要先找到链表当前的尾结点,并将新结点插入到链表尾部。
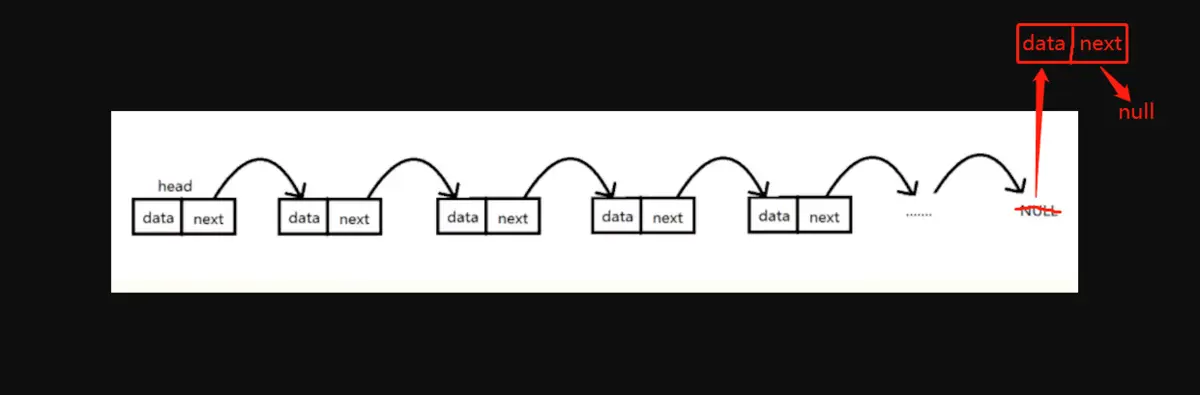
尾部插入结点
/**
* 添加结点至链表尾部
*
* @param value
*/
public void addTailNode(T value) {
Node newNode = new Node(value);
//头结点不存在,新结点成为头结点
if (head == null) {
head = newNode;
return;
}
//找到最后一个结点
Node last = head;
while (last.next != null) {
last = last.next;
}
//新结点插入到链表尾部
last.next = newNode;
}
-
指定位置插入结点
实现思路:先判断插入位置为头尾两端的情况,即index == 0插入到头部,index == size()插入到尾部;如果插入位置不是头尾两端,则先找出当前index位置的结点cur以及前一个结点 pre,然后cur成为新结点的下一个结点,新结点成为pre的后一个结点,这样就成功插入到index位置。
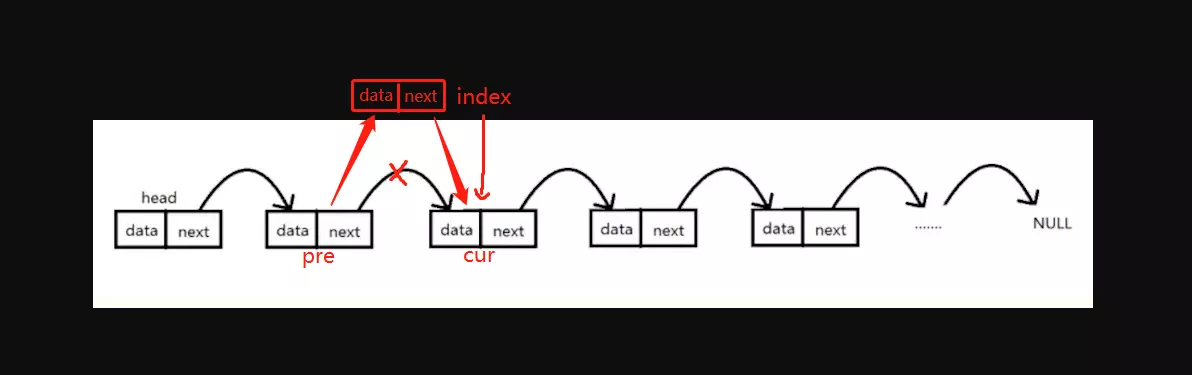
指定位置插入结点
/**
* 结点插入至指定位置
*
* @param value 结点数据
* @param index 插入位置
*/
public void addNodeAtIndex(T value, int index) {
if (index < 0 || index > size()) { //注意index是可以等于size()的
throw new IndexOutOfBoundsException("IndexOutOfBoundsException");
}
if (index == 0) { //插入到头部
addHeadNode(value);
} else if (index == size()) { //插入到尾部
addTailNode(value);
} else { //插到某个中间位置
Node newNode = new Node(value);
int position = 0;
Node cur = head; //标记当前结点
Node pre = null; //记录前置结点
while (cur != null) {
if (position == index) {
newNode.next = cur;
pre.next = newNode;
return;
}
pre = cur;
cur = cur.next;
position++;
}
}
}
-
删除指定位置结点
实现思路:找出当前index位置的结点cur以及前一个结点 pre,pre.next直接指向cur.next即可删除cur结点。

删除指定位置结点
/**
* 删除指定位置的结点
*
* @param index 指定位置
*/
public void deleteNodeAtIndex(int index) {
if (index < 0 || index > size() - 1) {
throw new IndexOutOfBoundsException("IndexOutOfBoundsException");
}
if (index == 0) { //删除头
head = head.next;
return;
}
int position = 0; //记录当前位置
Node cur = head; //标记当前结点
Node pre = null; //记录前置结点
while (cur != null) {
if (position == index) {
pre.next = cur.next;
cur.next = null; //断开cur与链表的连接
return;
}
pre = cur;
cur = cur.next;
position++;
}
}
-
链表反转
实现思路:在链表遍历的过程中将指针顺序置换,即每遍历一次链表就让cur.next指向pre,最后一个结点成为新的头结点。反转之后指针入下图红线所示。
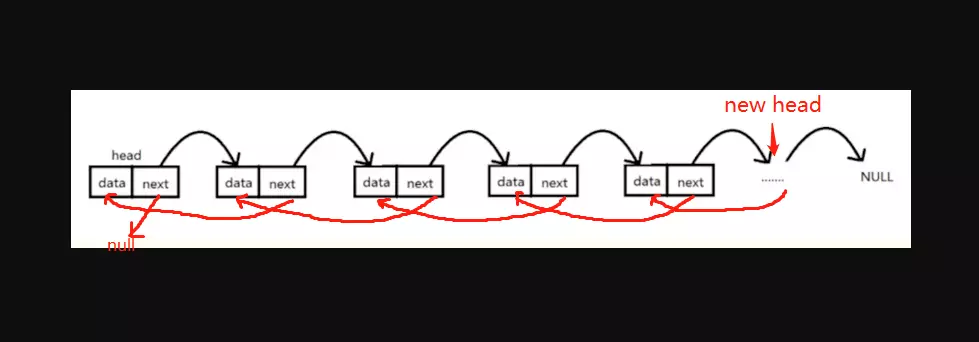
链表反转
/**
* 链表反转
*/
public void reverse() {
Node cur = head; //标记当前结点
Node pre = null; //标记当前结点的前一个结点
Node temp;
while (cur != null) {
//保存当前结点的下一个结点
temp = cur.next;
//cur.next指向pre,指针顺序置换
cur.next = pre;
//pre、cur继续后移
pre = cur;
cur = temp;
}
//最后一个结点变成新的头结点
head = pre;
}
-
求倒数第k个结点
实现思路:倒数第k个结点就是第size() - k + 1个结点,cur结点向后移动size() - k次就是倒数第k个结点。
/**
* 倒数第k个结点
*
* @param k
* @return
*/
public T getLastK(int k) {
if (k < 0 || k > size()) { //注意index是可以等于size()的
throw new IndexOutOfBoundsException("IndexOutOfBoundsException");
}
Node cur = head;
for (int i = 1; i < size() - k + 1; i++) {
cur = cur.next;
}
return cur.value;
}