一些重要的概念
Servables
- Servables 是客户端请求执行计算的基础对象,大小和粒度是灵活的。
- Servables 不会管理自己的运行周期。
- 典型的Servables包括:
- a TensorFlow SavedModelBundle (tensorflow::Session)
- a lookup table for embedding or vocabulary lookups
Servable Versions
- Tensorflow servables 可以管理多个版本的servable,可以通过版本管理来更新算法配置和模型参数;
- 可以支持同时加载多个servable
Servable Streams
- servable的版本序列。
Models
- TensorFlow Serving 将 model 表示为一个或者多个Servables,一个Servable可能对应着模型的一部分,例如,a large lookup table 可以被许多 TensorFlow Serving 共享。
Loaders
- Loaders 管理着对应的一个servable的生命周期
Source
- Sources 是可以寻找和提供 servables 的模块,每个 Source 提供了0个或者多个servable streams,对于每个servable stream,Source 都会提供一个Loader实例;
- Sources 可以保存在多个服务或者版本之间共享的state;
Aspired Versions
- Aspired Versions 是可以被加载服务版本集合;
Managers
- 管理 Servable 的整个的生命周期,包括:
- loading Servables
- serving Servables
- unloading Servables
- 如果服务要求的资源不足,Manager 可能会拒绝加载新的模型;
流程
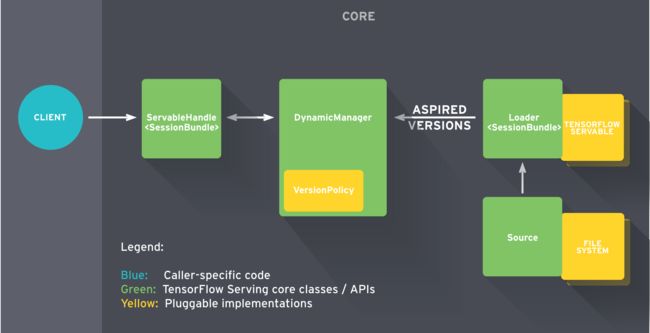
流程图
简单来说:
- Source 为 Servable 创建 Loader 对象;
- Loader 被作为 Aspired Versions 发送给 Manager,之后 Manager 加载指定的服务去处理客户端的请求;
具体来说:
- Source 为指定的服务创建Loader,Loader里包含了服务所需要的元数据(模型);
- 之后 Source 使用 回掉函数通知 Manager 的 Aspired Version(servable version的集合);
- Manager 根据配置的Version Policy决定下一步的操作(是否 unload 之前的servable,或者 load 新的servable);
- 如果 Manager 判定是操作安全的,就会给 Loader 要求的resource并让 Loader 加载新的版本;
- 客户端向 Manager 请求服务,可以指定服务版本或者只是请求最新的版本。Manager 返回服务端的处理结果;
Source 可以看作不断更新weights的graph,weights 存储在磁盘中
例如:
- Source 选择了一个新版本的模型,创建了一个Loader,Loader包含指向模型文件路径的指针;
- Source 使用回掉函数通知 Manager 的 Aspired Version;
- 根据 Version Policy ,Manager 决定加载新的模型;
- Manager 通知 Loader 有足够的内存用于模型加载,Loader 使用新的weights将graph实例化;
- 客户端发送请求,Manager 返回处理结果;
生成可用于tensorflow serving的模型
环境:Tensorflow 1.0.1
模型:基于LSTM的文本情感分类的模型:
import os,time
import tensorflow as tf
import online_lstm_model
from utils import data_utils,data_process
from lib import config
#载入词向量,生成字典
embedding_matrix, word_list = data_utils.load_pretained_vector(config.WORD_VECTOR_PATH)
data_utils.create_vocabulary(config.VOCABULARY_PATH, word_list)
#数据预处理
for file_name in os.listdir(config.ORGINAL_PATH):
data_utils.data_to_token_ids(config.ORGINAL_PATH + file_name, config.TOCKEN_PATN + file_name,
config.VOCABULARY_PATH)
vocabulary_size = len(word_list) + 2
#获取训练数据
x_train, y_train, x_test, y_test = data_process.data_split(choose_path=config.choose_car_path,
buy_path=config.buy_car_path,
no_path=config.no_car_path)
with tf.Graph().as_default():
#build graph
model = online_lstm_model.RNN_Model(vocabulary_size, config.BATCH_SIZE, embedding_matrix)
logits = model.logits
loss = model.loss
cost = model.cost
acu = model.accuracy
prediction = model.prediction
train_op = model.train_op
saver = tf.train.Saver()
#GPU设置
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=1.0)
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) as sess:
count = 0
init = tf.global_variables_initializer()
sess.run(init)
while count启动服务
在这里采用默认的 tensorflow_model_server 启动服务
bazel-bin/tensorflow_serving/model_servers/tensorflow_model_server --port=8000 --model_name=your_model_name --model_base_path=your_model_path
例如:
bazel-bin/tensorflow_serving/model_servers/tensorflow_model_server --port=8000 --model_name=sentiment_classification --model_base_path=/home/liyonghong/sentiment_analysis/builder_last
注意事项:
- 在实验过程中,采用保存checkpoint的方式(每n轮保存一次)保存serving模型时,进行本地调用时出错,所以最好在训练过程中只保存一次模型。
Tensorflow Serving Client端(在这里使用第三方包tensorflow_serving_client)
固定request_input的shape,向request中放一条数据
(如果构建模型时输入的维度是固定的,应该将shape字段设置为模型输入的shape)
from tensorflow_serving_client.protos import predict_pb2, prediction_service_pb2
from grpc.beta import implementations
import tensorflow as tf
import time
from keras.preprocessing.sequence import pad_sequences
from utils import data_utils,data_process
from lib import config
#文件读取和处理
vocb, rev_vocb = data_utils.initialize_vocabulary("./vocab")
test_sentence_ = ["我", "讨厌", "这", "车"]
test_token_sentence = [[vocb.get(i.encode('utf-8'), 1) for i in test_sentence_]]
#将多条数据放到一个request中:
# for i in range(128):
# test_token_sentence.append([vocb.get(i.encode('utf-8'), 1) for i in test_sentence_])
padding_sentence = pad_sequences(test_token_sentence, maxlen=config.MAX_SEQUENCE_LENGTH)
#计时
start_time = time.time()
#建立连接
channel = implementations.insecure_channel("服务的IP地址", 端口号)
stub = prediction_service_pb2.beta_create_PredictionService_stub(channel)
request = predict_pb2.PredictRequest()
#这里由保存和运行时定义,第一个启动tensorflow serving时配置的model_name,第二个是保存模型时的方法名
request.model_spec.name = "sentiment_classification"
request.model_spec.signature_name = "serving_default"
#入参参照入参定义
request.inputs["input_sentence"].ParseFromString(tf.contrib.util.make_tensor_proto(padding_sentence,
dtype=tf.int64,
shape=[1, 50]).SerializeToString())
#第二个参数是最大等待时间,因为这里是block模式访问的
response = stub.Predict(request, 10.0)
results = {}
for key in response.outputs:
tensor_proto = response.outputs[key]
nd_array = tf.contrib.util.make_ndarray(tensor_proto)
results[key] = nd_array
print("cost %ss to predict: " % (time.time() - start_time))
print(results["predict_classification"])
# print(results["predict_scores"])
结果:
cost 0.7014968395233154s to predict:
predict label is: [0]
不固定request_input的shape,将 n 条数据放在同一个请求中(实验中n=128)
from tensorflow_serving_client.protos import predict_pb2, prediction_service_pb2
from grpc.beta import implementations
import tensorflow as tf
import time
from keras.preprocessing.sequence import pad_sequences
from utils import data_utils,data_process
from lib import config
#文件读取和处理
vocb, rev_vocb = data_utils.initialize_vocabulary(config.VOCABULARY_PATH)
test_sentence_ = ["我", "讨厌", "这", "车"]
test_token_sentence = [[vocb.get(i.encode('utf-8'), 1) for i in test_sentence_]]
#将多条数据放到一个request中:
for i in range(128):
test_token_sentence.append([vocb.get(i.encode('utf-8'), 1) for i in test_sentence_])
padding_sentence = pad_sequences(test_token_sentence, maxlen=config.MAX_SEQUENCE_LENGTH)
#计时
start_time = time.time()
#建立连接
channel = implementations.insecure_channel("部署服务的IP地址", 端口号)
stub = prediction_service_pb2.beta_create_PredictionService_stub(channel)
request = predict_pb2.PredictRequest()
#这里由保存和运行时定义,第一个启动tensorflow serving时配置的model_name,第二个是保存模型时的方法名
request.model_spec.name = "sentiment_classification"
request.model_spec.signature_name = "serving_default"
#入参参照入参定义
request.inputs["input_sentence"].ParseFromString(tf.contrib.util.make_tensor_proto(padding_sentence,
dtype=tf.int64).SerializeToString())
#第二个参数是最大等待时间,因为这里是block模式访问的
response = stub.Predict(request, 10.0)
results = {}
for key in response.outputs:
tensor_proto = response.outputs[key]
nd_array = tf.contrib.util.make_ndarray(tensor_proto)
results[key] = nd_array
print("cost %ss to predict: " % (time.time() - start_time))
print("predict label is:",results["predict_classification"])
# print(results["predict_scores"])
结果:
cost 0.7941889762878418s to predict:
predict label is: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
第二种调用方式处理的数据远多于第一种调用方式处理的数据,但是所用的时间跟第一种方式差不多,这可能是由于Tensorflow Serving 在处理请求时,采用了并行计算的方式,降低了计算耗时。
注意事项
- 对request.inputs进行定义时,数据类型
dtype要与保存模型时对应的tensor的数据类型保持一致。例如:定义graph中tensor的数据类型为tf.int64,那么request.inputs也应该定义为tf.int64,如果定义为别的数据类型,可能会损失精度; - 客户端调用成功后,建议将客户端请求结果与本地调用模型的结果进行对比,验证结果是否正确;