Sparkstream小结
实时数据:根据自身的容忍性来定义实时,并没有一个准确的时间来形容这个概念。
Sparkstream与storm的区别
storm实时流计算框架是一条一条数据处理,sparkstream准实时流式框架,微批处理,延迟比storm高;两者都支持动态调整资源;sparkstream支持复杂的业务逻辑,storm相对来说逻辑简单一些(相对来说)。
SparkStream数据处理流程图
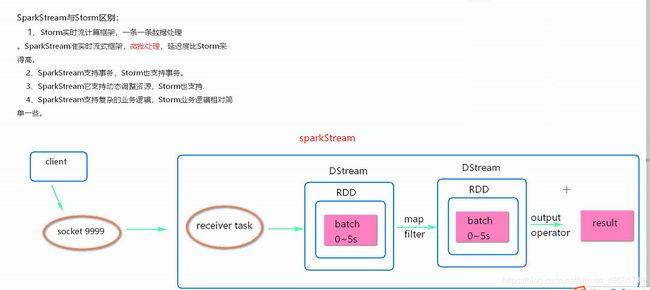
SparkStream的receiver task会7*24小时一直运行,将接收到的数据保存起来。每隔batchInterval的时间将数据封装费一个RDD,继而封装为RDD,最后变成一个DStream。
这其中还有一个问题,就是处理数据的时间比接受数据的时间长的话,那么就会随着时间的推移数据堆积越来越严重,最后总就会造成OOM。这个可以设置内存满了的话就保存在disk中。
* 1、local的模拟线程数必须大于等于2 因为一条线程被receiver(接受数据的线程)占用,另外一个线程是job执行
* 2、Durations时间的设置,就是我们能接受的延迟度,这个我们需要根据集群的资源情况以及监控每一个job的执行时间来调节出最佳时间。
* 3、 创建JavaStreamingContext有两种方式 (sparkconf、sparkcontext)
* 4、业务逻辑完成后,需要有一个output operator
* 5、JavaStreamingContext.start()straming框架启动之后是不能在次添加业务逻辑
* 6、JavaStreamingContext.stop()无参的stop方法会将sparkContext一同关闭,stop(false) 只会关闭SteamContext ,sparkcontext依然存在
* 7、JavaStreamingContext.stop()停止之后是不能在调用start
本地运行加载数据的时候,如果不需要HDFS,那就需要把conf文件恢复成普通文件夹
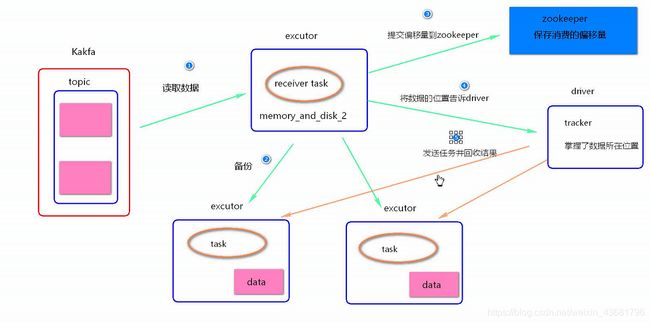
WAL机制会导致数据重复消费问题:当开启WAL机制时,若在数据存到HDFS后,提交偏移量到zookeeper之前,这个时间点driver挂掉,会造成数据重复计算,因为当driver重启之后,它会先读取hdfs的数据做计算,然后再去zookeeper读取偏移量,此时就造成了重复读取。
Sparkstream+kafka direct模式
此种模式,kafaka偏移量有spark自己保存到内存当中,也通过checkpoint进行持久化,放在磁盘里面;在direct模式下DStrem的分区数等于kafka topic的分区数
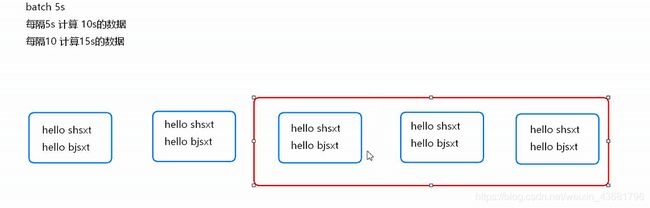
要有连续性,不然中间会楼道数据;每隔多久和计算的时间都是batch’的倍数,但不一定相等
WAL机制的问题会导致数据重复消费。
(并行度)Recive模式的task数量是由patition决定的,patition的数量是由blockInterval决定,blockInterrval(默认200ms)被batch(5s)除,就是有25个。200ms就有一个block块,所以并行度(或者说task数量)是由blockInteval决定的,这是在数据不间断的情况下。但是实际情况中间的时候可能不会有数据,而且如果只有10条数据的话,也不可能给他拆了呀。