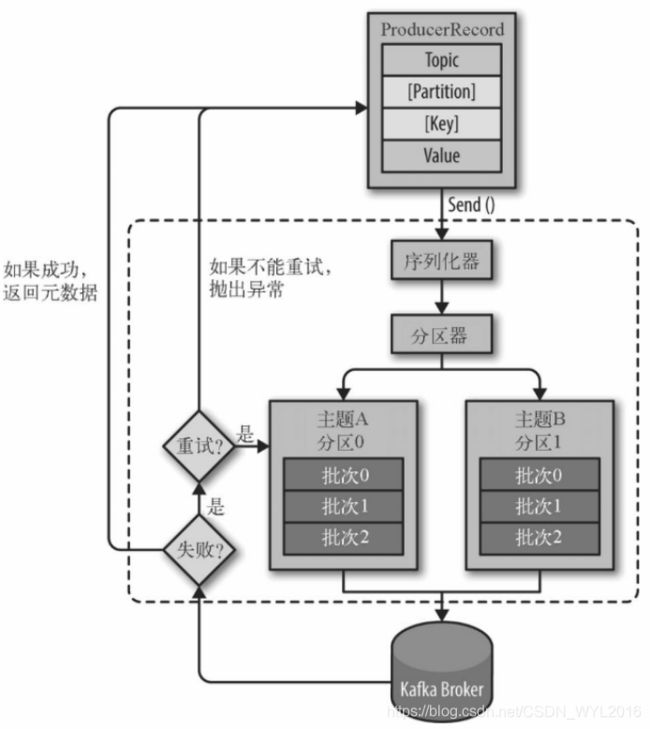
kafka生产者消息发送的流程与参数配置
kafka生产者发送消息的流程
1、消息首先会被封装成ProducerRecord对象,ProducerRecord的构造方法有多种。
可以指定要发送的分区
spring提供的kafkaTemplate也可以指定分区发送,比如这里指定了发送到分区为1
public String sendPartition() {
for (int i = 0; i < 10; i++) {
kafkaTemplate.send("test_topic", 1,"test_topic_key", String.valueOf(i));
}
return "ok";
}
消费者
@KafkaListener(topics = {"test_topic"})
public void listen(ConsumerRecord<?, ?> record) {
logger.info("get msg key: {}, value: {}, partition: {}", record.key(), record.value().toString(), record.partition());
}
打印收到的消息,全部是从为1的分区中获取到的消息

如果指定的分区不存在,比如我指定消息发送到分区10,则会报错
2020-05-22 15:10:58.300 ERROR 16100 --- [nio-8080-exec-2] o.s.k.support.LoggingProducerListener : Exception thrown when sending a message with key='test_topic_key' and payload='0' to topic test_topic and partition 10:
org.apache.kafka.common.errors.TimeoutException: Topic test_topic not present in metadata after 60000 ms.
默认等待元数据响应是60s,可以通过参数修改,比如配置成1秒。
props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 1000);
这时候我们再看报错信息
2020-05-22 15:31:11.855 ERROR 8264 --- [nio-8080-exec-4] o.s.k.support.LoggingProducerListener : Exception thrown when sending a message with key='test_topic_key' and payload='0' to topic test_topic and partition 10:
org.apache.kafka.common.errors.TimeoutException: Topic test_topic not present in metadata after 1000 ms.
2、确保元数据可用
上面的分区不正确,就是在这个地方校验并抛出异常的
// first make sure the metadata for the topic is available
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
3、序列化消息
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
4、计算消息应该发送到哪个分区?
int partition = partition(record, serializedKey, serializedValue, cluster);
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
如果没有指定分区器,则使用默认的分区器DefaultPartitioner,大概流程:
1、先根据topic获取分区数。
2、如果发送消息时指定了key,则根据key的hash值与分区数取模,获得分区。
3、如果没有指定key,则通过维护一个自增的int值再与分区数取模,获取分区,这就类似轮询的方式了。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
}
5、把一条消息放入一个批次中,按批次发送
默认条件一个批次大小是16kb,通过batch.size参数设置,当批次中的消息大小达到16kb时,才会发送到broker中,否则等待,那么等待的时间可以由linger.ms这个参数控制,如果超过等待时间后还未达到16kb,那么还是会发送到broker中,这个参数默认值是0,也就是不等待。
batch.size参数设置过小,可能会降低kafka的吞吐量,设置的过大又可能会占用过多的内存和延迟消息的发送时间。
batch.size参数一定要配合linger.ms使用,并且linger.ms默认值是0,所以默认情况下如果不设置linger.ms值等于还是一条一条发送消息的。
@RequestMapping(value = "/sendlinger")
public String sendlinger() throws ExecutionException, InterruptedException {
ListenableFuture future = kafkaTemplate.send("test_topic", "test_topic_key", "test");
long s = System.currentTimeMillis();
future.get();
long e = System.currentTimeMillis();
System.out.println("wait time: " + (e - s));
return "ok";
}
linger.ms设置为0,不等待
props.put(ProducerConfig.LINGER_MS_CONFIG, 0);
wait time: 1
2020-05-22 18:54:15.484 INFO 4860 --- [ntainer#0-1-C-1] com.wyl.service.MyListener : get msg key: test_topic_key, value: test, partition: 2
linger.ms设置为1000
props.put(ProducerConfig.LINGER_MS_CONFIG, 1000);
wait time: 1001
2020-05-22 18:55:18.591 INFO 20140 --- [ntainer#0-1-C-1] com.wyl.service.MyListener : get msg key: test_topic_key, value: test, partition: 2
一批次的消息会被放入Deque的队列中,然后唤醒sender线程,由sender线程负责把消息发送给broker。
//追加消息
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
//唤醒sender线程
this.sender.wakeup();
}
把消息按照批次发送,虽然提高了吞吐量,但是却带来了频繁申请内存空间再释放的过程,也就是说会造成频繁的GC。
针对上述问题,于是kafka就设计出了缓冲池的概念,kafka先将一片内存区域固定下来专门用于存放batch,每次从缓冲池申请batch,使用完后再还回缓冲池,这样就避免了每次对于batch的申请与回收,解决了JVM 频繁GC的问题
当缓冲池满了以后并且配置了阻塞模式(max.block.ms参数),也就是说消息写入的速度大于向broker发送的速度,那么就阻塞写入,直到缓冲池中有空余内存时为止。
分配过程
/**
* Allocate a buffer of the given size. This method blocks if there is not enough memory and the buffer pool
* is configured with blocking mode.
*
* @param size The buffer size to allocate in bytes
* @param maxTimeToBlockMs The maximum time in milliseconds to block for buffer memory to be available
* @return The buffer
* @throws InterruptedException If the thread is interrupted while blocked
* @throws IllegalArgumentException if size is larger than the total memory controlled by the pool (and hence we would block
* forever)
*/
public ByteBuffer allocate(int size, long maxTimeToBlockMs) throws InterruptedException {
if (size > this.totalMemory)
throw new IllegalArgumentException("Attempt to allocate " + size
+ " bytes, but there is a hard limit of "
+ this.totalMemory
+ " on memory allocations.");
ByteBuffer buffer = null;
this.lock.lock();
try {
// check if we have a free buffer of the right size pooled
if (size == poolableSize && !this.free.isEmpty())
return this.free.pollFirst();
// now check if the request is immediately satisfiable with the
// memory on hand or if we need to block
int freeListSize = freeSize() * this.poolableSize;
if (this.nonPooledAvailableMemory + freeListSize >= size) {
// we have enough unallocated or pooled memory to immediately
// satisfy the request, but need to allocate the buffer
freeUp(size);
this.nonPooledAvailableMemory -= size;
} else {
// we are out of memory and will have to block
int accumulated = 0;
Condition moreMemory = this.lock.newCondition();
try {
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
this.waiters.addLast(moreMemory);
// loop over and over until we have a buffer or have reserved
// enough memory to allocate one
while (accumulated < size) {
long startWaitNs = time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
try {
waitingTimeElapsed = !moreMemory.await(remainingTimeToBlockNs, TimeUnit.NANOSECONDS);
} finally {
long endWaitNs = time.nanoseconds();
timeNs = Math.max(0L, endWaitNs - startWaitNs);
recordWaitTime(timeNs);
}
if (waitingTimeElapsed) {
throw new TimeoutException("Failed to allocate memory within the configured max blocking time " + maxTimeToBlockMs + " ms.");
}
remainingTimeToBlockNs -= timeNs;
// check if we can satisfy this request from the free list,
// otherwise allocate memory
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {
// just grab a buffer from the free list
buffer = this.free.pollFirst();
accumulated = size;
} else {
// we'll need to allocate memory, but we may only get
// part of what we need on this iteration
freeUp(size - accumulated);
int got = (int) Math.min(size - accumulated, this.nonPooledAvailableMemory);
this.nonPooledAvailableMemory -= got;
accumulated += got;
}
}
// Don't reclaim memory on throwable since nothing was thrown
accumulated = 0;
} finally {
// When this loop was not able to successfully terminate don't loose available memory
this.nonPooledAvailableMemory += accumulated;
this.waiters.remove(moreMemory);
}
}
} finally {
// signal any additional waiters if there is more memory left
// over for them
try {
if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) && !this.waiters.isEmpty())
this.waiters.peekFirst().signal();
} finally {
// Another finally... otherwise find bugs complains
lock.unlock();
}
}
if (buffer == null)
return safeAllocateByteBuffer(size);
else
return buffer;
}
流程图