未明学院:机器学习热门项目开始报名,一次收获数据挖掘&机器学习技能、行业项目经历!
机器学习是当前最为火爆的话题之一,很多公司都在讨论如何运用机器学习来改进技术并超越竞争对手,谁也不愿在大数据时代落于人后。
大数据高量(High Volume),高速(High Velocity),多样(High Variety),高疏(High Verasity)的4V特征,使得传统系统没有办法很好的处理、分析这些数据。但是庞大数据中包含着大量“隐含的,规律性的,事先未知,但又潜在有用的”信息。要能够得到这些信息,数据挖掘必不可少,新的系统解决方案应运而生,机器学习就是其中最重要的技术之一。这个领域也有着广阔的发展前景,比如产品推荐、自动驾驶汽车、语音理解、文本分析、面部识别、医学图像处理、搜索引擎等等,都有非常丰富的应用。
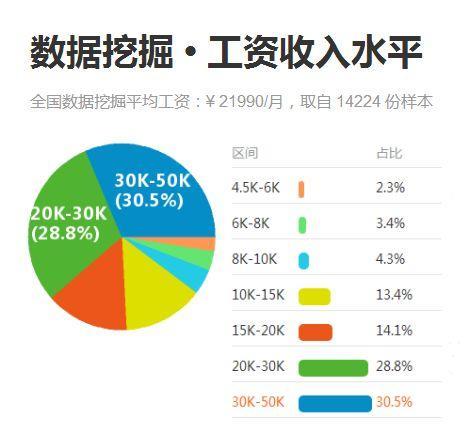
前景明朗的同时,市场供应却有所不足。根据数联寻英2016年发布的《大数据人才报告》,现阶段我国大数据人才仅有 46 万,在未来 3-5 年内大数据人才缺口将高达 150 万。缺口的逐渐增大,大数据人才的薪资也跟着水涨船高。据某权威招聘网站统计,目前数据挖掘岗位的全国平均薪资高达21990/月,其中80%在10K以上,主要薪资集中在20k—50k以上。
这样的趋势下,许多理工科同学都开始扎堆转行数据行业,但如何在激烈的竞争中脱颖而出,是面临的一大难题。
机器学习作为数据挖掘的核心支撑技术,在竞争中,有着非常关键的作用。是否拥有机器学习项目经历,能否展现出数据处理和机器学习算法等方面的能力,将会是求职者转岗数据挖掘的关键。
以下是一位未明学院的学员完成的《基于图像的电影推荐算法》项目,该项目可以完整地体现出学员在基础开发、数据处理、机器学习及编程工具使用等各方面的能力。
数据处理能力:学会基本的数据抽样和数据探索技巧,熟练运用python进行数据清洗,数据集成、数据变换和数据规约,保证取样数据质量并划分测试集和训练集。
机器学习理论:在学习概率与统计的基础上,掌握VC维、信息论、正则化、最优化等机器学习理论,了解有监督学习及无监督学习等基本机器学习模型。
基础开发能力:掌握机器学习算法工程师必备的开发技能,在项目中,将每个环节都反复迭代优化调试,能够将复杂任务进行模块划分,实现逻辑抽象复用。
编程能力:在项目实战过程中,掌握python的基础知识,并能熟练运用python搭建相应的机器学习框架。



至少一段机器学习的项目经历,将会成为简历中巨大的亮点,使求职者的背景与数据挖掘更加匹配,并帮助他们取得成功,我们往年的案例也在不断印证着这样的结论。
未明学院部分成功案例
01
南京大学 信息管理与信息系统
全职offer:阿里巴巴数据挖掘岗
项目名称:基于AI和机器学习构建信贷风险控制模型
合并高级机器学习算法,对信贷风险进行更精确的估算。
使用Python进行数据提取、数据清洗和数据降维。
建造随机森林,采用卡方自动交互检测(CHAID)算法分析每个变量,生成决策树的二进制变量。
将随机树输出结果输入逻辑回归,获得各权因子的风险权值。
02
同济大学 电子科学与技术
实习offer:今日头条数据挖掘岗
项目名称:《某金融机构交易流水预测》
收集某金融机构2017年一月至七月的交易数据。
使用Python进行数据预处理,解决数据丢失、数据噪声和数据异常等数据问题。
构建自回归积分滑动平均模型(ARIMA)、长短期记忆网络模型(LSTM)和射频模型(RF),分析数据特征,找出各模型的优缺点,算出预测值。
估测预测值的可靠性。
03
四川大学 计算机科学与技术
研究生录取offer:香港科技大学 大数据科技
项目名称:《基于机器学习构建的美国公民收入预测模型》
筛选出非数值,利用模型计算并填入缺失值,进行数据预处理,进行字符类型特点的整数编码。
建立随机森林、决策树、完全随机决策树和梯度提升决策树(GBDT)四种模型,实现模型效果可视化,使用网格搜索对模型的超参数进行序列调整。
采用调整后的参数更新四个决策树数据,采用堆叠集成学习方法将决策树转化为新模型,二次使用网格搜索寻找新模型的最优超参数。
回归到测试装置上模型的F1分数,输出可视化结果。
然而,机器学习起点高、难度大,在校生想要进行机器学习更是困难重重。其中最大的瓶颈在于,学校往往缺乏充足的资源与环境,没办法提供给学生有效且干净的数据。没有数据,一切算法将无从谈起。学生想要掌握核心算法也就举步维艰了。