1-2、自定义Partitioner代码
1-2、自定义Partitioner代码
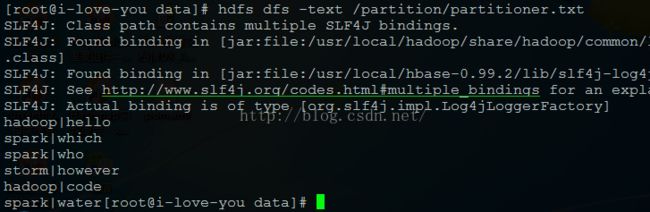
1、输入数据:
|
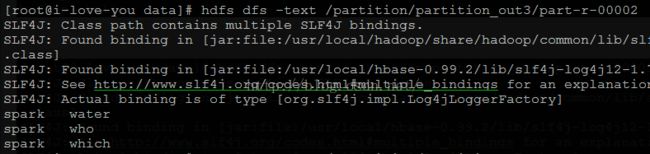
hadoop|hello
spark|which
spark|who
storm|however
hadoop|code
spark|water[
|
HDFS上:
2、代码:
|
package 自定义分区;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* main
* @author Administrator
*
*/
public class PartitionerDemo {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf, PartitionerDemo.class.getSimpleName());
job.setJarByClass(PartitionerDemo.class);
job.setNumReduceTasks(3);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setPartitionerClass(MyPartitionerPar.class);
// job.setCombinerClass(MyReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, "hdfs://192.168.1.10:9000"+args[0]);
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.1.10:9000"+args[1]));
job.waitForCompletion(true);
}
/**
* map
* @author Administrator
*
*/
public static class MyMapper extends Mapper
Text v2=new Text();
Text k2=new Text();
@Override
protected void map(LongWritable key, Text value,
Mapper
throws IOException, InterruptedException {
String line=value.toString();
String[] splited=line.split("\\|");
k2.set(splited[0]);
v2.set(splited[1]);
context.write(k2, v2);
System.out.println(splited[0]+"-->"+splited[1]);
}
}
/**
* reducer
* @author Administrator
*
*/
public static class MyReduce extends Reducer
Text v3=new Text();
@Override
protected void reduce(Text k2, Iterable
Reducer
throws IOException, InterruptedException {
for (Text str : v2) {
v3.set(str);
context.write(k2, v3);
}
}
}
/**
* 输入的是Map的输出
* @author Administrator
*
*/
public static class MyPartitionerPar extends Partitioner
@Override
public int getPartition(Text key, Text value, int numPartitions) {
String str1=key.toString();
int result=1;
if(str1.equals("hadoop")){
result = 0 % numPartitions; //0%3==0
// result = 0 ; //0%3==0
}else if(str1.equals("storm")){
result = 1 % numPartitions; //0%3==0
// result = 1 ; //1%3==1
}else if (str1.equals("spark")) {
result = 2 % numPartitions; //0%3==0
// result = 2 ; //2%3==2
}
return result;
}
}
}
|
自定义分区关键代码:
|
public static class MyPartitionerPar extends Partitioner
@Override
public int getPartition(Text key, Text value, int numPartitions) {
String str1=key.toString();
int result=1;
if(str1.equals("hadoop")){
result = 0 % numPartitions; //0%3==0
// result = 0 ; //0%3==0
}else if(str1.equals("storm")){
result = 1 % numPartitions; //0%3==0
// result = 1 ; //1%3==1
}else if (str1.equals("spark")) {
result = 2 % numPartitions; //0%3==0
// result = 2 ; //2%3==2
}
return result;
}
|
3、输出结果:

part-r-00000:
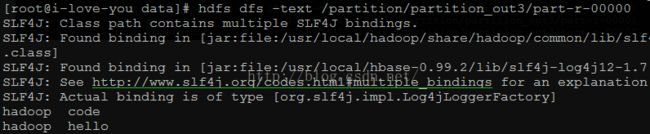
part-r-00001:

part-r-00002: