epub图书_使用EPUB构建数字图书
epub图书
在你开始前
本教程将指导您创建EPUB格式的电子书。 EPUB是一种基于XML的,对开发人员友好的格式,它已成为数字图书的事实上的标准。 但是EPUB不仅适合书籍:有了它,您可以:
- 捆绑文档以供离线阅读或轻松分发
- 打包博客文章或其他Web本地内容
- 使用常见的开源工具进行构建,搜索和重新混合
关于本教程
您可以通过手动生成EPUB书籍来开始本教程,以帮助您学习所有组件和所需的文件。 接下来,该教程显示了如何捆绑完成的数字书并根据规范对其进行验证,以及如何在各种阅读系统中对其进行测试。
然后,它涵盖了从DocBook XML(技术文档使用最广泛的标准之一)生成EPUB的方法,以及如何使用Python从头到尾完全自动化DocBook的EPUB创建。
目标
在本教程中,您:
- 了解什么是EPUB,它的背后是谁,以及谁在采用它
- 探索EPUB捆绑包的结构,包括其所需的文件及其架构
- 使用简单的内容从头开始创建有效的EPUB文件
- 使用开源工具从DocBook(用于技术文档和书籍的广泛使用的架构)生成EPUB文件
- 使用Python和DocBook自动执行EPUB转换
先决条件
尽管您应该熟悉创建文件和目录的机制,但是本教程假定没有特定的操作系统。 强烈建议使用XML编辑器或集成开发环境(IDE)。
对于本教程有关自动创建EPUB的后续部分,本教程假定您了解一种或多种基本XML处理技能(基于XSLT,DOM或SAX的解析),以及如何使用XML原生API构造XML文档。
完成本教程无需熟悉EPUB文件格式。
系统要求
要完成本教程中的示例,您需要一个Java解释器(1.5或更高版本)和一个Python解释器(2.4或更高版本),以及各自的必需XML库。 但是,经验丰富的XML开发人员应该能够使示例适用于具有XML库的任何编程语言。
关于EPUB格式
了解EPUB的背景,最常使用的EPUB,以及EPUB与可移植文档格式(PDF)有何不同。
什么是EPUB?
EPUB是由国际数字出版论坛(IDPF)(用于数字出版行业的贸易和标准协会)标准化的可重用数字书籍和出版物的XML格式。 IDPF于2007年10月正式采用了EPUB,到2008年,主要发行商Swift采用了EPUB。 您可以在所有主要操作系统,Sony PRS等电子墨水设备以及Apple iPhone等小型设备上使用各种开源软件和商业软件来读取EPUB格式。
谁在生产EPUB? 仅书籍吗?
尽管传统印刷出版商最先采用EPUB,但格式上没有任何限制将其用于电子书。 使用免费提供的软件工具,您可以将网页作为EPUB捆绑,转换纯文本文件或将现有DocBook XML文档转换为格式正确且有效的EPUB。 (我将在“ 从DocBook到EPUB”中介绍后者。)
EPUB与PDF有何不同?
PDF仍然是世界上使用最广泛的电子文档格式。 从书籍出版商的角度来看,PDF具有以下优点:
- PDF文件允许对布局进行完美的像素控制,包括复杂的易于打印的布局,例如多列和备用的正/反样式。
- PDF可以通过多种基于GUI的文档工具生成,例如Microsoft®Office Word或Adobe®InDesign®。
- PDF阅读器无处不在,并已安装在大多数现代计算机上。
- 可以将特定字体嵌入PDF中,以精确控制最终输出。
从软件开发人员的角度来看,PDF与理想情况相去甚远:
- 这不是学习的标准。 因此,将您自己的PDF生成代码放在一起并不是一件容易的事。
- 尽管PDF现在是国际标准化组织(ISO)标准(ISO 32000-1:2008),但传统上它是由一家公司控制的:Adobe Systems。
- 尽管PDF库可用于大多数编程语言,但许多库是商业的或嵌入在GUI应用程序中,并且不易受外部过程控制。 并非所有免费库都继续得到积极维护。
- 可以通过编程方式提取和搜索PDF原生文本,但是很少有PDF带有标签,因此转换为Web友好格式既简单又可靠。
- PDF文档不易回流 ,这意味着它们无法很好地适应小屏幕或布局的根本变化。
为什么EPUB对开发人员友好
EPUB解决了PDF中与开发人员友好相关的所有缺陷。 EPUB是一个简单的ZIP格式文件(扩展名为.epub ),其中包含以禁止方式排序的文件。 关于ZIP归档的准备方式,存在一些棘手的要求,稍后将在将EPUB文件打包为ZIP归档中进行详细讨论。 否则,EPUB很简单:
- EPUB中几乎所有内容都是XML。 可以使用标准XML工具包来构建EPUB文件,而无需任何特殊或专有软件。
- EPUB内容(电子书的实际文本)几乎始终是XHTML 1.1版。 (另一种格式是DTBook的,用于编码的书籍为视障。见标准相关主题有关DTBook的更多信息,这是不包括在本教程)。
- 大多数EPUB XML模式均取自可免费获得的现有已发布规范。
两个关键点是EPUB元数据是XML , EPUB内容是XHTML 。 如果您的文档构建系统生成Web的输出和/或基于XML,那么它也非常接近能够生成EPUB。
建立您的第一个EPUB
最低限度的EPUB捆绑包包含几个必需的文件。 该规范对于EPUB档案中这些文件的格式,内容和位置可能非常严格。 本部分说明使用EPUB标准时必须了解的内容。
EPUB束的解剖
最小EPUB文件的基本结构遵循清单1中的模式。 准备分发时,此目录结构会捆绑在一起成为ZIP格式的文件,在将EPUB文件作为ZIP归档捆绑在一起时,有一些特殊要求。
清单1.一个简单的EPUB档案的目录和文件布局
mimetype
META-INF/
container.xml
OEBPS/
content.opf
title.html
content.html
stylesheet.css
toc.ncx
images/
cover.png注意:可以从Downloadable resources中获得遵循此模式的样本书,但是我建议您按照教程来创建自己的书。
要开始构建您的EPUB图书,请为EPUB项目创建目录。 打开文本编辑器或IDE(例如Eclipse)。 我建议使用具有XML模式,特别是一个可以验证对编辑的RELAX NG模式中列出的相关主题 。
模仿文件
这很简单:mimetype文件是必需的,并且必须命名为mimetype。 该文件的内容始终为:
application/epub+zip请注意,mimetype文件不能包含任何换行符或回车符。
此外,mimetype文件必须是ZIP存档中的第一个文件,并且本身不能被压缩。 您将在将EPUB文件作为ZIP归档文件打包时看到如何使用常见的ZIP参数包含它。 现在,只需创建此文件并保存,并确保它位于您的EPUB项目的根目录下即可。
META-INF / container.xml
在EPUB的根级别,必须有一个META-INF目录,并且必须包含一个名为container.xml的文件。 EPUB阅读系统将首先查找此文件,因为它指向数字图书的元数据的位置。
创建一个名为META-INF的目录。 在其中打开一个名为container.xml的新文件进行写入。 容器文件很小,但是其结构要求很严格。 将清单2中的代码粘贴到META-INF / container.xml中。
清单2.示例container.xml文件
full-path的值(粗体)是该文件中唯一会变化的部分。 目录路径必须相对于EPUB文件本身的根目录,而不是相对于META-INF目录。
MIME类型和容器文件是在EPUB档案中位置受到严格控制的仅有两个文件。 根据建议(尽管不是必需的),将其余文件存储在EPUB的子目录中。 (按照惯例,对于开放式电子书出版结构 ,这通常称为OEBPS ,但可以是您喜欢的任何东西。)
接下来,在您的EPUB项目中创建名为OEBPS的目录。 本教程的以下部分介绍了OEBPS中的文件-数字书的真正内容:元数据和页面。
打开包装格式元数据文件
尽管此文件可以命名为任何名称,但OPF文件通常称为content.opf。 它指定了书的所有内容的位置,从书的文本到图像等其他媒体。 它还指向另一个元数据文件,即导航中心扩展(NCX)目录。
OPF文件是EPUB规范中最复杂的元数据。 创建OEBPS / content.opf,并将清单3的内容粘贴到其中。
清单3.具有示例元数据的OPF内容文件
Hello World: My First EPUB
My Name
urn:uuid:0cc33cbd-94e2-49c1-909a-72ae16bc2658
en-US
OPF模式和名称空间
OPF文档本身必须使用名称空间http://www.idpf.org/2007/opf,元数据将在都柏林核心元数据计划(DCMI)名称空间中,即http://purl.org/dc/elements/ 1.1 /。
这是将OPF和DCMI模式添加到XML编辑器的好时机。 可从可下载资源中获得EPUB中使用的所有模式。
元数据
Dublin Core定义了一组通用的元数据术语,您可以用它们来描述各种各样的数字资料。 它不是EPUB规范本身的一部分。 OPF元数据部分中允许使用任何这些术语。 在构建用于分发的EPUB时,请在此处尽可能多地包含细节,尽管清单4中提供的摘录足以开始。
清单4. OPF元数据的摘录
...
Hello World: My First EPUB
My Name
urn:uuid:12345
... 必需的两个术语是标题和标识符。 根据EPUB规范,标识符必须是唯一值,尽管数字图书的创建者需要定义该唯一值。 对于图书出版商,此字段通常包含ISBN或国会图书馆编号。 对于其他EPUB创建者,请考虑使用URL或随机生成的大型唯一用户ID(UUID)。 请注意,属性unique-identifier的值必须与dc:identifier元素的ID属性匹配。
如果与您的内容相关的其他要考虑添加的元数据包括:
- 语言(如
dc:language)。 - 发布日期(如
dc:date)。 - 发布者(作为
dc:publisher)。 (这可以是您的公司或个人名称。) - 版权信息(如
dc:rights)。 (如果根据知识共享许可发布作品,请在此处放置许可的URL。)
请参阅相关主题关于DCMI的更多信息。
包括一meta与该元素name包含属性cover不直接EPUB规范的一部分,但是是使封面和图像的可移植性,建议这样做。 一些EPUB渲染器喜欢使用图像文件作为封面,而另一些渲染器则使用包含嵌入式封面图像的XHTML文件。 本示例显示了两种形式。 meta元素的content属性的值应为清单中清单的封面ID,该清单是OPF文件的下一部分。
表现
OPF清单列出了在EPUB中找到的所有资源,这些资源是内容的一部分(不包括元数据)。 这通常意味着构成电子书文本的XHTML文件列表以及一些相关媒体(例如图像)。 EPUB鼓励使用CSS来对书籍内容进行样式设置,因此清单文件中也包含CSS文件。 电子书中的每个文件都必须在清单中列出。
清单5显示了提取的清单部分。
清单5. OPF清单的摘录
...
... 您必须包括第一项toc.ncx (在下一节中讨论)。 请注意,所有项目均具有适当的media-type值,并且XHTML内容的媒体类型为application/xhtml+xml 。 此确切值是必需的, 不能为text/html或其他某种类型。
EPUB支持四种图像文件格式作为核心类型:联合图像专家组(JPEG),便携式网络图形(PNG),图形交换格式(GIF)和可伸缩矢量图形(SVG)。 如果提供对核心类型的后备支持,则可以包括不支持的文件类型。 有关后备项的更多信息,请参见OPF规范。
href属性的值应该是相对于OPF文件的统一资源标识符(URI) 。 (这很容易与container.xml文件中对OPF文件的引用相混淆,该引用必须相对于整个EPUB。)在这种情况下,OPF文件与您的内容位于同一OEBPS目录中,因此这里不需要路径信息。
脊柱
尽管清单告诉EPUB读者哪些文件是归档文件的一部分,但书脊会指示它们的出现顺序,或者用EPUB术语表示数字书籍的线性阅读顺序 。 想到OPF脊椎的一种方法是,它定义了本书“页面”的顺序。 将按文档顺序从上至下读取书脊。 清单6显示了OPF文件的摘录。
清单6. OPF脊柱摘录
...
... 每个itemref元素都有一个必需的属性idref ,该属性必须与清单中的ID之一匹配。 toc属性也是必需的。 它在清单中引用一个ID,该ID必须指示NCX目录的文件名。
脊柱中的linear属性指示该项目是否被视为线性阅读顺序的一部分,而不是无关紧要的前或后事项。 我建议您将任何封面定义为linear=no 。 符合标准的EPUB阅读系统会将书打开到书脊中未设置为linear=no的第一项。
指南
OPF内容文件的最后一部分是指南。 此部分是可选的,但建议使用。 清单7显示了一个指南文件的摘录。
清单7. OPF指南的摘录
...
...该指南是向EPUB阅读系统提供语义信息的一种方式。 清单定义了EPUB中的物理资源,而书脊提供了有关其顺序的信息,而指南则说明了各节的含义。 以下是OPF指南中允许的部分值列表:
-
cover:书的封面 -
title-page:包含作者和发布者信息的页面 -
toc:目录
有关完整列表,请参阅OPF 2.0规范,可从相关主题 。
NCX目录
尽管OCF文件被定义为EPUB本身的一部分,但最后的主要元数据文件是从其他数字图书标准中借用的。 DAISY是一个联盟,主要为由于视觉障碍或无法操纵印刷品而无法使用传统书籍的读者开发数据格式。 EPUB借用了DAISY的NCX DTD。 NCX定义了数字书籍的目录。 在复杂的书中,它通常是分层的,包含嵌套的部分,章节和节。
使用XML编辑器,创建OEBPS / toc.ncx,并包含清单8中的代码。
清单8.简单的NCX文件
Hello World: My First EPUB
Book cover
Contents
NCX元数据
DTD在NCX 标记内需要四个meta元素:
-
uid:是电子书的唯一ID。 该元素应与OPF文件中的dc:identifier匹配。 -
depth:反映目录中层次结构的级别。 此示例只有一个级别,因此该值为1 。 -
totalPageCount和maxPageNumber:仅适用于纸质书,可以保留为0 。
docTitle/text的内容是作品的标题,并且与OPF中dc:title的值匹配。
NCX导航地图
navMap是NCX文件中最重要的部分,因为它定义了实际书籍的目录。 navMap包含一个或多个navPoint元素。 每个navPoint必须包含以下元素:
-
playOrder属性,它反映文档的阅读顺序。 这遵循与OPFitemref元素列表相同的顺序。 - 一个
navLabel/text元素,它描述了本书这一部分的标题。 这通常是章节标题或编号,例如“第一章”或(在本示例中)“封面”。 - 一个
content元素,其src属性指向包含该内容的物理资源。 这将是在OPF清单中声明的文件。 (也可以在此处使用片段标识符指向XHTML内容中的锚点,例如content.html#footnote1。) - (可选)一个或多个子
navPoint元素。 嵌套点是在NCX中如何表达层次结构文档。
样本书的结构很简单:只有两页,并且没有嵌套。 这意味着您将有两个navPoint元素, playOrder值从1开始递增。 在NCX中,您可以命名这些部分,以使读者跳入电子书的不同部分。
添加最终内容
现在您已经了解了EPUB中所需的所有元数据,现在该输入实际的书本内容了。 您可以使用可下载资源中提供的样本内容,也可以创建自己的样本内容,只要文件名与元数据匹配即可。
接下来,创建以下文件和文件夹:
- title.html:此文件将是该书的标题页。 创建此文件,并包括一个引用封面图像的
img元素,其中src属性的值为images/cover.png。 - images:在OEBPS中创建此文件夹,然后复制示例图像(或创建自己的图像),并将其命名为cover.png。
- content.html:这将是本书的实际文本。
- stylesheet.css:将此文件与XHTML文件放在同一OEBPS目录中。 该文件可以包含您喜欢的任何CSS声明,例如设置字体样式或文本颜色。 有关此类CSS文件的示例,请参见清单10 。
EPUB书中的XHTML和CSS
清单9包含有效的EPUB内容页面的示例。 将此示例用于您的书名页(title.html),将类似的示例用于书的主要内容页(content.html)。
清单9.示例标题页面(title.html)
Hello World: My First EPUB
Hello World: My First EPUB

EPUB中的XHTML内容遵循一些常规Web开发可能不熟悉的规则:
- 内容必须经过XHTML 1.1验证: XHTML 1.0 Strict和XHTML 1.1之间唯一的重要区别是
name属性已被删除。 (使用ID来引用内容中的锚点。) -
img元素只能引用电子书本地的图像:元素不能引用Web上的图像。 - 应避免使用
script块: EPUB阅读器不需要支持JavaScript代码。
EPUB支持CSS的方式存在一些细微的差异,但没有一个会影响样式的常见用法(有关详细信息,请咨询OPS规范)。 清单10演示了一个简单CSS文件,您可以将其应用于内容以设置基本字体准则和红色的颜色标题。
清单10.电子书的样例样式(stylesheet.css)
body {
font-family: sans-serif;
}
h1,h2,h3,h4 {
font-family: serif;
color: red;
} 有趣的一点是EPUB特别支持CSS 2 @font-face规则,该规则允许嵌入字体。 如果您创建技术文档,则可能无关紧要,但是使用多种语言或针对特定领域构建EPUB的开发人员将喜欢指定精确字体数据的功能。
现在,您拥有创建第一本EPUB图书所需的一切。 在下一部分中,您将根据OCF规范捆绑书籍,并了解如何进行验证。
包装并检查您的EPUB
至此,您应该已经准备好打包EPUB捆绑包。 该捆绑软件既可以是您自己创建的新书,也可以使用可下载资源中的原始文件。
将您的EPUB文件打包为ZIP存档
关于EPUB和ZIP,EPUB规范的OEBPS容器格式部分有几句话要说,但最重要的是:
- 存档中的第一个文件必须是mimetype文件(请参阅本教程中的Mimetype )。 不能压缩mimetype文件。 这样,非ZIP实用程序就可以通过读取EPUB捆绑包中位置30开始的原始字节来发现模仿类型。
- ZIP归档文件无法加密。 EPUB支持加密,但不支持ZIP文件级别的加密。
在类似UNIX®的操作系统下使用ZIP版本2.3,通过两个命令创建EPUB ZIP文件,如清单11所示 。 (这些命令假定您当前的工作目录是您的EPUB项目。)
清单11.将EPUB捆绑到一个有效的epub + zip文件中
$ zip -0Xq my-book.epub mimetype
$ zip -Xr9Dq my-book.epub * 在第一个命令中,创建新的ZIP存档并添加没有压缩的mimetype文件。 在第二个中,添加其余项。 标志-X和-D最小化.zip文件中的无关信息。 -r将递归包含META-INF和OEBPS目录的内容。
EPUB验证
尽管EPUB标准并不是特别困难,但是必须根据特定的架构验证其XML文件。 如果您使用可识别架构的XML编辑器来生成元数据和XHTML,那么您已经完成了一半。 对EpubCheck包进行最后检查(参见相关主题 )。
Adobe维护EpubCheck软件包,根据伯克利软件发行(BSD)许可,该软件包可作为开放源代码使用。 它是一个Java程序,可以作为独立工具或Web应用程序运行,也可以将其集成到在Java Runtime Environment(JRE)1.5或更高版本下运行的应用程序中。
从命令行运行它很简单。 清单12提供了一个示例。
清单12.运行EpubCheck实用程序
$ java -jar /path/to/epubcheck.jar my-book.epub如果您未能创建一些辅助文件或在元数据文件中引入了错误,则可能会收到类似于清单13的错误消息。
清单13.来自EpubCheck的样本错误
my-book.epub: image file OEBPS/images/cover.png is missing
my-book.epub: resource OEBPS/stylesheet.css is missing
my-book.epub/OEBPS/title.html(7): 'OEBPS/images/cover.png':
referenced resource missing in the package
Check finished with warnings or errors!您可能需要在此处设置CLASSPATH以指向EpubCheck安装的位置,因为它确实要导入一些外部库。 如果收到类似以下的消息,则可能需要设置CLASSPATH:
org.xml.sax.SAXParseException: no implementation available for schema language
with namespace URI "http://www.ascc.net/xml/schematron"如果验证成功,您将看到“未检测到错误或警告”。 在这种情况下,恭喜您制作了第一个EPUB!
查看EPUB
测试不仅涉及验证:还涉及确保本书看起来正确。 样式表是否正常工作? 这些部分的逻辑顺序是否正确? 这本书是否包含所有预期内容?
可以使用几种EPUB阅读器进行测试。 图1显示了最常用的EPUB阅读器Adobe Digital Editions(ADE)的屏幕截图。
图1. ADE中的EPUB
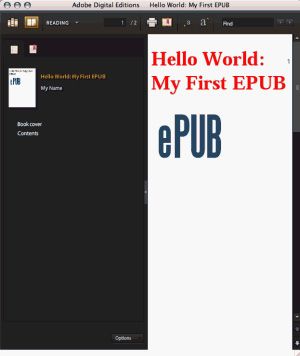
您的字体颜色和图像出现了,很好。 但是,ADE无法正确以Sans-Serif字体呈现标题,这可能是CSS的问题。 在此签到其他读者很有用。 图2显示了在我的基于Web的开源EPUB阅读器Bookworm中呈现的同一本书。
图2. Bookworm中的EPUB
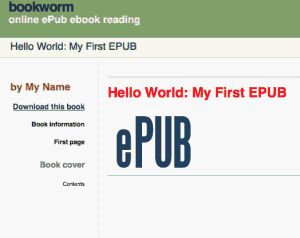
在这种情况下,只是ADE不支持该特定声明。 如果准确的格式在数字书中很重要,则必须具备个人阅读软件中的怪癖知识。
现在,您已经完成了从头开始创建简单EPUB的艰巨过程,现在看看将普通的XML文档架构DocBook转换为EPUB所需要的内容。
从DocBook到EPUB
DocBook是需要维护长期技术文档的开发人员的流行选择。 与传统文字处理程序生成的文件不同,您可以使用基于文本的版本控制系统来管理DocBook输出。 由于DocBook是XML,因此您可以轻松地将其转换为多种输出格式。 从2008年夏季开始,您可以从官方DocBook XSL项目中找到对EPUB的本机支持,作为输出格式。
使用XSLT运行从DocBook到EPUB的基本管道
从清单14中的一个简单的DocBook文档开始。 该文档被定义为类型book并包括一个序言,两章以及在标题页上显示的嵌入式图像。 将在与DocBook源文件相同的目录中找到该图像。 自己创建此文件和标题页图像,或者从可下载资源中下载样本。
清单14.一本简单的DocBook书
My EPUB book
Liza
Daly 1234
Title page
Our EPUB cover image icon
![]()
This is a pretty simple DocBook example
Not much to see here.
End notes
This space intentionally left blank.
接下来,请参阅参考资料以下载DocBook XSL样式表的最新版本,并确保您安装了XSLT处理器,例如xsltproc或Saxon。 本示例使用xsltproc,在大多数类似UNIX的系统上都可用。 要转换DocBook文件,只需针对DocBook XSL中包含的EPUB模块运行该文件,如清单15所示 。
清单15.将DocBook转换为EPUB
$ xsltproc /path/to/docbook-xsl-1.74.0/epub/docbook.xsl docbook.xml
Writing OEBPS/bk01-toc.html for book
Writing OEBPS/pr01.html for preface(preface)
Writing OEBPS/ch01.html for chapter(chapter1)
Writing OEBPS/ch02.html for chapter(end-notes)
Writing OEBPS/index.html for book
Writing OEBPS/toc.ncx
Writing OEBPS/content.opf
Writing META-INF/container.xml接下来,添加mimetype文件并自己构建epub + zip存档。 清单16显示了这三个快速命令以及通过EpubCheck验证器的结果。
清单16.从DocBook创建EPUB档案
$ echo "application/epub+zip" > mimetype
$ zip -0Xq my-book.epub mimetype
$ zip -Xr9D my-book.epub *
$ java -jar epubcheck.jar my-book.epub
No errors or warnings detected挺容易! 图3显示了您在ADE中的创建。
图3.在ADE中转换后的DocBook EPUB

使用python和lxml自动将DocBook转换为EPUB
DocBook XSL在使EPUB生成变得轻松的过程中有很长的路要走,但是您必须在XSLT之外执行一些步骤。 最后一部分演示了一个示例Python程序,该程序完成了有效EPUB捆绑包的创建。 我在教程中展示了各个方法; 您可以从可下载资源中获取完整的docbook2epub.py程序。
有几个Python XSLT库可用,但我的首选是lxml。 它不仅提供XSLT 1.0功能,而且还提供高性能的解析,完整的XPath 1.0支持以及用于处理HTML的特殊扩展。 如果您喜欢使用与Python不同的库或使用不同的编程语言,则这些示例应易于调整。
使用lxml调用DocBook XSL
使用lxml调用XSLT的最有效方法是预先解析XSLT,然后创建一个可重复使用的转换器。 这很有用,因为我的DocBook-to-EPUB脚本接受多个DocBook文件进行转换。 清单17演示了这种方法。
清单17.使用lxml运行DocBook XSL
import os.path
from lxml import etree
def convert_docbook(docbook_file):
docbook_xsl = os.path.abspath('docbook-xsl/epub/docbook.xsl')
# Give the XSLT processor the ability to create new directories
xslt_ac = etree.XSLTAccessControl(read_file=True,
write_file=True,
create_dir=True,
read_network=True,
write_network=False)
transform = etree.XSLT(etree.parse(docbook_xsl), access_control=xslt_ac)
transform(etree.parse(docbook_file))DocBook XSL中的EPUB模块本身会创建输出文件,因此此处的转换评估不会返回任何内容。 而是,DocBook在当前工作目录中创建两个文件夹(META-INF和OEBPS),其中包含转换结果。
将图像和其他资源复制到档案中
DocBook XSL对您可能提供用于文档的任何图像不做任何处理; 它仅创建元数据文件和呈现的XHTML。 因为EPUB规范要求在content.opf清单中列出所有资源,所以您可以检查清单以查找原始DocBook文件中引用的任何图像。 清单18显示了这种技术,它假设path变量包含DocBook XSLT创建的进行中的EPUB的路径。
清单18.解析OPF内容文件以查找任何缺少的资源
import os.path, shutil
from lxml import etree
def find_resources(path='/path/to/our/epub/directory'):
opf = etree.parse(os.path.join(path, 'OEBPS', 'content.opf'))
# All the opf:item elements are resources
for item in opf.xpath('//opf:item',
namespaces= { 'opf': 'http://www.idpf.org/2007/opf' }):
# If the resource was not already created by DocBook XSL itself,
# copy it into the OEBPS folder
href = item.attrib['href']
referenced_file = os.path.join(path, 'OEBPS', href):
if not os.path.exists(referenced_file):
shutil.copy(href, os.path.join(path, 'OEBPS'))自动创建mimetype文件
DocBook XSL也不会创建您的mimetype文件,但是清单19中的一小段代码就可以解决这个问题。
清单19.创建mimetype文件
def create_mimetype(path='/path/to/our/epub/directory'):
f = '%s/%s' % (path, 'mimetype')
f = open(f, 'w')
# Be careful not to add a newline here
f.write('application/epub+zip')
f.close()使用Python创建EPUB捆绑包
现在剩下的就是将文件捆绑到有效的EPUB ZIP归档文件中。 这需要两个步骤:在没有压缩的情况下将mimetype文件作为第一个添加到存档中,然后添加其余目录。 清单20显示了此过程的代码。
清单20.使用Python zipfile模块创建一个EPUB包
import zipfile, os
def create_archive(path='/path/to/our/epub/directory'):
'''Create the ZIP archive. The mimetype must be the first file in the archive
and it must not be compressed.'''
epub_name = '%s.epub' % os.path.basename(path)
# The EPUB must contain the META-INF and mimetype files at the root, so
# we'll create the archive in the working directory first and move it later
os.chdir(path)
# Open a new zipfile for writing
epub = zipfile.ZipFile(epub_name, 'w')
# Add the mimetype file first and set it to be uncompressed
epub.write(MIMETYPE, compress_type=zipfile.ZIP_STORED)
# For the remaining paths in the EPUB, add all of their files
# using normal ZIP compression
for p in os.listdir('.'):
for f in os.listdir(p):
epub.write(os.path.join(p, f)), compress_type=zipfile.ZIP_DEFLATED)
epub.close()而已! 记住要验证。
摘要
上一节中的Python脚本只是完全自动化任何类型的EPUB转换的第一步。 为了简洁起见,它不处理许多常见情况,例如任意嵌套的路径,样式表或嵌入的字体。 Ruby爱好者可以查看DocBook XSL发行版中包含的dbtoepub ,以使用该语言的类似方法。
由于EPUB是一种相对较年轻的格式,因此许多有用的转换路径仍在等待创建。 幸运的是,大多数类型的结构化标记(例如reStructuredText或Markdown)都具有已经生成HTML或XHTML的管道。 使它们适应以产生EPUB应该非常简单,尤其是使用DocBook-to-EPUB Python或Ruby脚本作为指南。
由于EPUB主要是ZIP和XHTML,因此没有理由不将文档包作为EPUB存档而不是简单的.zip文件分发。 使用EPUB阅读器的用户会从附加的元数据和自动目录中受益,但是没有EPUB阅读器的用户则可以将EPUB存档视为普通的ZIP文件,并在浏览器中查看XHTML内容。 考虑将EPUB生成的代码添加到任何类型的文档系统中,例如Javadoc或Perldoc。 EPUB专为书本而设计,因此对于越来越多的在线或正在进行中的编程书本来说,它是一种理想的发行格式。
翻译自: https://www.ibm.com/developerworks/xml/tutorials/x-epubtut/index.html
epub图书