dota2无法最小化_在DITA中专门化主题类型
dota2无法最小化
基于XML的达尔文信息键入体系结构(DITA)的要点是创建模块化的技术文档,该文档易于使用各种显示和交付机制(例如帮助集,手册,小屏幕设备的分层摘要)进行重用。 本文介绍了如何在创建DTD和转换方面将DITA原则付诸实践,以支持您的特定信息类型,而不仅仅是使用基本的DITA概念,任务和参考集。
主题专业化是作者和架构师定义新主题类型的过程,同时保持与现有样式表,转换和过程的兼容性。 新主题类型被定义为相对于现有主题类型的扩展或增量,从而减少了定义和维护新类型所需的工作。
本文档假定您已经知道DITA是什么。 如果您需要基本的介绍,请参阅随附的路线图文章“达尔文信息打字体系结构介绍” 。 本文使用的示例使用XML DTD语法和XSLT。 如果您需要这些主题的背景知识,请参阅参考资料 。
建筑环境
在SGML中,架构形式是提供从一种文档类型到另一种文档类型的映射的经典方法。 专门化是一种类似于架构形式的解决方案,用于解决更受约束的问题:提供从更具体的主题类型到更一般的主题类型的映射。 因为特定主题类型是在考虑通用主题类型的基础上开发的,所以专业化可以忽略体系结构形式解决的许多棘手问题。 这种受限制的领域使专业化过程相对易于实施和维护。 专业化还提供了对多层次或分层专业化的支持,这些专业化允许更通用的主题类型充当不同专业化类型的共同点。
创建专业化流程是为了与DITA合作,尽管其原理和流程也适用于其他领域。 如果考虑一个示例,这将更有意义:给定专门化和通用DTD(例如HTML),您可以创建新的文档类型(称为MyHTML)。 在MyHTML中,您可以执行公司的站点标准,包括有关表单布局,标题级别以及字体和闪烁标签使用的特定规则。 此外,您可以为产品和订购信息提供更具体的结构,以使搜索引擎和其他应用程序可以更有效地使用数据。
通过专业化,可以将MyHTML定义为HTML DTD的扩展,仅在必要时声明新的元素类型,并为共享元素引用HTML的DTD。 无论MyHTML在哪里声明新元素,它都包含一个映射回现有HTML元素的映射。 此映射允许创建样式表和HTML转换,这些样式表和转换在MyHTML文档上同样有效。 当您想以不同的方式处理结构(例如,以特定方式格式化产品信息)时,可以定义一个新样式表或包含扩展行为的转换,然后导入标准样式表或转换以处理其余行为。 换句话说,新行为被添加为对原始样式表的扩展,就像新约束被添加为对原始DTD或架构的扩展一样。
专门信息类型
达尔文信息键入体系结构与信息类型有关的不是文档类型。 一个文档被认为由许多主题组成,每个主题都有自己的信息类型。 简单来说,主题就是由标题和一些文本组成的大量信息,可以选择将其划分为多个部分。 信息类型描述主题的内容:例如,给定主题的类型可以是“概念”或“任务”。
DITA具有三种类型的主题:通用主题,或信息类型的概念,任务和参考主题。 概念,任务和参考主题都可以视为主题的专业化:
图1.三种信息类型,作为主题的专长

可以将其他信息类型添加为体系结构,作为这三种基本类型中的任一种的专业化,或者作为主题之外的对等专业化-并且这些其他专业化中的任何一种都可以专门化:
图2.扩展了架构以包含更多专业类型
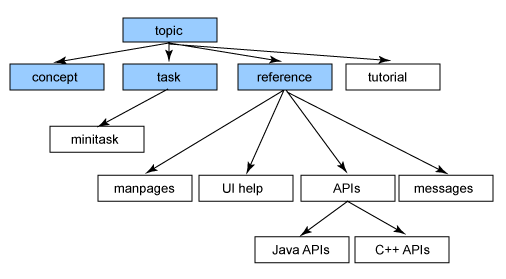
每个新的信息类型都定义为现有信息类型的扩展:专门化类型继承(不重复)任何公共结构; 专门类型提供其新元素和常规类型的现有元素之间的映射。 每种信息类型都在其自己的DTD模块中定义,该模块仅定义该类型的新元素。 仅由一种信息类型组成的文档(例如,帮助网站中的任务文档)具有由信息类型的专业化层次结构中的所有模块(例如task.mod和topic.mod)定义的文档类型。 具有多种信息类型的文档类型(例如,一本由概念,任务和参考主题组成的书)包括所使用的每种信息类型的模块以及其祖先的模块(concept.mod,task.mod ,reference.mod以及其祖先topic.mod)。
因为信息类型声明被分成模块,所以您可以定义新的信息类型而不影响祖先类型。 这种分离为您带来以下好处:
- 降低维护成本:每个创作组仅维护其唯一需要的元素
- 增加兼容性:可以集中维护核心信息类型,并且对核心类型的更改将反映在所有专业类型中
- 分发控制:可重用性由重用者控制,而不是由作者控制; 添加新类型不会影响核心类型的维护,也不会影响其他不同类型的用户
任何信息类型的主题都属于多种类型。 例如,在更笼统的意义上,API描述是参考主题。
专业化示例:参考主题
考虑参考主题的专业化层次结构:
图3.一个简单的专业化层次结构
表1表示topic的一般元素与reference的特定元素之间的关系。 在表中,列,行和单元格指示信息类型,元素映射和元素。 表2详细说明了这些关系,以帮助您解释表1。
表1.主题与基于该主题的专业化之间的关系
| 话题 | 参考 |
|---|---|
| (topic.mod) | (reference.mod) |
| 话题 | 参考 |
| 标题 | |
| 身体 | 反射体 |
| 简单表 | 属性 |
| 部分 | refsyn |
表2.如何解释表1。
| 结构体 | 社团协会 |
|---|---|
| 列 | Topic列显示了基本的topic结构,该结构由标题和带有可选部分的正文组成,如在名为topic.mod的DTD模块中声明的topic.mod 。 参考列显示了更专门的结构, reference替换topic , refbody替换body ,和refsyn替换section ; 这些新元素在称为reference.mod的DTD模块中声明。 |
| 行数 | 每行表示该行中元素之间的映射。 “ 参考”列中的元素专门用于“ 主题”列中的元素。 每个常规元素还充当同一行中更多专业元素的类别。 例如, reference的refsyn是一个section 。 |
| 细胞 | 列中的每个单元格代表与左侧单元格有关的以下可能性:
|
引用类型模块
清单1展示不是实际reference.mod内容,而是基于表1中的内容模型支持域专门使用实体的简化版本,作为域专门文章中描述(见相关主题 )。
清单1
此处声明的大多数内容模型都取决于topic.mod声明的元素或实体。 因此,如果topic的结构得到增强或更改,则大多数更改将自动通过reference 。 另外, reference的定义仍然很简单:不必重新声明与topic共享的任何内容。
添加专业化属性
要公开元素映射,可以向每个元素添加一个属性,以显示其到更通用类型的映射。
清单2
稍后,我将讨论编写XSL转换时如何利用这些属性。 有关类属性的更深入描述,请参见附录。
创建创作DTD
现在,您已经定义了类型模块(用于声明新键入的元素及其属性)并添加了特殊化属性(用于将新类型映射到其祖先),您可以组装创作DTD。
清单3
%topic-type;
%reference-type;专业化示例:API描述
现在,我将向您展示如何创建一种更加专业的信息类型:API描述,这是一种(因此是专门化的)参考主题。
图4.更专业的信息类型,API描述

表3显示了用于API描述的称为APIdesc的信息类型的部分专业化。 如前所述,每一列代表一种信息类型,其特殊性从左到右发生。 也就是说,每种信息类型都是其左侧邻居的特化。 每行表示一组映射的元素,右侧有更多特定元素,而左侧有更通用的等价物。
和以前一样,每个单元格专门将单元格的内容放在其左侧:
- 一个空白单元格:左侧的元素将由新类型保持不变。 例如,API描述中提供了
simpletable和refsyn。 - 完整单元格:左侧元素替换为更具体的元素。 例如,
APIname替换title。 - 带有空白单元格的拆分行:新元素添加到左侧的元素。 例如,API描述添加了一个
usage部分作为refsyn和section元素的对等体。
表3. APIdesc专业化摘要
| 话题 | 参考 | APIdesc |
|---|---|---|
| (topic.mod) | (reference.mod) | (APIdesc.mod) |
| 话题 | 参考 | APIdesc |
| 标题 | API名称 | |
| 身体 | 反射体 | API主体 |
| 简单表 | 属性 | 参数 |
| 部分 | refsyn | |
| 用法 |
APIdesc模块
在这里,您可以看到API描述的内容实际上比一般参考主题的内容受到更多的限制。 现在强加了语法顺序,然后是用法,然后是参数,随后是可选的附加部分。 此序列是参考主题中允许的结构的子集,它允许语法,属性和节的任何序列。 此外,用法section的标签现在固定为Usage ,从而利用了该部分的spectitle属性(正是这种用法):通过spectitle属性提供部分标题,您还可以摆脱使用的内容模型中的title元素,它使用预定义的section.notitle.cnt实体。
清单4
添加专业化属性
现在,每个新元素都具有一个与其所有祖先元素的映射。
清单5
请注意,即使在两种情况下它们都是相同的(标题), APIname在参考和主题中明确标识其等效项。 以同样的方式,用法明确地映射到参考和主题中的部分。 这种明确的标识使过程更容易跟踪复杂的映射。 即使您的专业化层次结构的深度为10层或更多,这些属性仍将允许到每个祖先信息类型的明确映射。
编写DTD
现在,您已经定义了类型模块(用于声明新键入的元素及其属性)并添加了特殊化属性(用于将新类型映射到其祖先),您可以组装创作DTD。
清单6
%topic-type;
%reference-type;
%APIdesc-type;专业化工作
定义专用类型并声明必要的属性后,它们可以为以下操作提供基础:
- 应用常规样式表或转换为专用主题类型
- 泛化特殊类型的主题(将其转换为更通用的主题类型)
- 专门化一般类型的主题(将其转换为更具体的主题类型-仅在最初以专门形式创作主题并且经过一般阶段而不破坏其原始形式的约束时才使用)
应用常规样式表或变换
由于以新信息类型(例如APIdesc)编写的内容具有到现有信息类型(例如reference和topic )中等效或限制较少的结构的映射,因此可以将现有转换和过程安全地应用于新内容。 默认情况下,新信息类型中的每个专用元素都将被视为其一般等效项的实例。 例如,在APIdesc , 元素,该元素恰好具有固定标签"Usage" 。
要覆盖此默认行为,作者可以简单地为该元素类型创建一个新的,更具体的规则,然后导入默认样式表或转换,从而扩展了行为而无需直接编辑原始样式表或转换。 这种通过引用的重用减少了维护成本(每个站点仅维护其唯一需要的规则)并提高了一致性(因为可以集中维护核心转换规则,并且对核心规则的更改将反映在导入它们的所有其他转换中)。 对重用的控制已从转换的作者转移到转换的重用者。
本节的其余部分假定您掌握XSLT(XSL转换语言)的知识。
要求
仅当启用了常规转换以处理专用元素并且专用元素包含足够的信息以用于常规转换来处理它们时,此过程才有效。
- 要求1:映射属性要提供专业化信息,您需要添加专业化属性,如前所述。 在文档中包含属性后,即可通过专业化感知转换来处理它们。
- 要求2:可识别专业化的转换对于转换,您需要模板规则,以检查元素名称和属性值是否匹配。
清单7
示例:覆盖转换
要覆盖特定元素的常规转换,新信息类型的作者可以创建一个转换,以声明特定元素的新行为,并导入该常规转换以提供其他元素的默认行为。
例如, APIdesc专用转换可以允许对除parameters之外的所有专用元素进行默认处理:
清单8
先前存在的reference properties模板规则和新parameters模板规则在遇到parameters元素时都会匹配(因为parameters元素是reference properties元素的一种特殊类型,并且其class属性包含两个值)。 但是,因为parameters模板在导入样式表中,所以新模板具有优先权。
概括话题
由于专用信息类型也是其祖先类型的实例(APIdesc是参考主题是主题),因此您可以安全地将专用主题转换为其更通用的祖先之一。 当您要合并来自两个来源的文档集(每个来源具有不同的专门性)时,此向上兼容性很有用。 祖先类型提供了可以安全地转换为两者的公共分母。 当您必须通过不具备专业意识的流程来提供主题时,这种兼容性也可能很有用:例如,向每个文档类型收费或使用非DDT感知流程的发布中心可以收到一组通用的文档,因此它们仅支持一种文档类型或一组标记。 但是,在任何可能的地方,您都应使用专业化感知的过程和转换,以便避免以更具描述性的专业化形式对文档进行概括和处理。
为了安全地概括主题,您需要一种从信息类型映射到目标信息类型的方法。 您还需要一种保留原始类型的方法,以防日后需要往返。
先前引入的class属性有两个用途。 它提供:
- 映射所需的信息
- 保存信息以允许往返的方式
每个专业化级别都有其自己的类属性集,这些属性最终为所有专业化元素提供完整的专业化层次结构。
考虑清单9中的APIdesc主题。
清单9
AnAPI
AnAPI (parm1, parm2)
Use AnAPI to pass parameters to your process.
...
公开class属性(DTD将所有值作为默认值提供):
清单10
AnAPI
AnAPI(parm1,
parm2)
Use AnAPI to pass parameters to your process.
...
从这里开始,单个模板规则可以将整个APIdesc主题转换为reference主题或通用主题。 模板规则只是在class属性中查找祖先元素名称,然后重命名当前元素以进行匹配。
转换为主题之后,代码应类似于清单11。
清单11
AnAPI
AnAPI(parm1,
parm2)
Use AnAPI to pass parameters to your process.
...
甚至在归纳之后,能够感知专业化的转换也可以继续将该主题视为APIdesc因为这些转换可以在class属性中查找有关元素类型层次结构的信息。
从这里开始,可以通过反转转换来进行往返(在class属性中查找特殊元素名称,并重命名当前元素以进行匹配)。 每当class属性未列出目标时(第一section没有APIdesc值),该元素就会更改为列出的最后一个值(因此第一section准确地成为refsyn )。
但是,如果有人更改了内容的结构,而该内容却是一个通用topic (例如,通过更改各节的顺序),则结果在专门的信息类型下可能不再有效(在APIdesc情况下,它强制执行特定的信息序列)在APIbody )。 因此,尽管映射到更通用的类型始终是安全的,但映射回专用类型可能会出现问题:专用类型具有更多的规则,这些规则使内容变得专用。 但是,在对内容进行更一般的编码时,不会强制执行这些规则。
专业化话题
如果内容最初是作为特殊类型创作的,则对一般主题进行特殊化比较简单。 但是,如果您现在想更精确地键入一般级别的内容,则可能导致更复杂的情况。
例如,假设您创建了一组参考主题。 然后,在分析了内容之后,您意识到自己拥有一致的模式。 现在,您要强制执行此模式,并使用专门的信息类型(例如,API描述)对其进行描述。 为了专业化,您需要首先创建目标DTD,然后将足够的信息添加到您的内容中以使其能够被迁移。
您可以将专业化信息放在两个位置之一:
- 将其添加到
class属性。 您需要小心以使顺序正确并包括所有祖先类型值。 - 在
outputclass属性中给出目标元素的名称,根据该值进行迁移,然后再添加class属性值。
无论哪种情况,在迁移之前,您都可以运行验证转换以查找适当的属性,然后检查该元素的内容在专用内容模型下是否有效。 您可以使用诸如Schematron之类的工具来生成验证转换和迁移转换,或者可以先进行迁移并使用专用DTD来验证迁移是否成功。
专门研究模式
像XML DTD语法一样,XML Schema语言是一种定义词汇表(元素和属性)以及对该词汇表进行约束的方法(例如内容模型或固定与隐含属性)。 它具有内置的专业化机制,其中包括限制允许的专业化的功能。 使用XML Schema语言而不是DTD可以更轻松地验证专用信息类型代表通用类型的有效子集,从而确保通过通用转换和发布转换进行平滑处理。
与DTD不同,XML模式表示为XML文档。 结果,可以用DTD无法处理的方式对其进行处理。 例如,您可以维护一个XML模式,然后使用XSL生成两个版本:
- 它的创作版本,消除了任何固定的属性和任何覆盖的元素
- 它的处理器就绪版本,其中包括驱动翻译和发布转换的类属性
但是,XML模式尚未流行到可以全心全意采用。 主要问题是缺乏创作工具以及不断发展的标准之间的不兼容性。 随着标准的最终确定和模式的更广泛采用和支持,业界应在明年左右纠正这些问题。
摘要
您可以使用以下常规过程创建专门的信息类型:
- 确定您需要的元素。
- 确定到更通用类型元素的映射。
- 验证专用元素的内容模型是否比其通用等效性更具限制性。
- 创建一个类型模块文件,其中包含您的专用元素和属性声明(包括
class属性)。 - 创建一个导入适当类型模块的创作DTD文件。
您可以使用以下常规过程创建专门的XSL转换:
- 为您的信息类型创建一个新的转换。
- 导入要扩展的现有转换。
- 确定您需要特别对待的元素。
- 根据其元素的
class属性内容添加与这些元素匹配的模板规则。
附录:专业规则
尽管您可以为通用DTD中的任何标签创建等效的新元素,但是作为作者,这项工作对您毫无用处,除非包含该标签的内容模型也专门化。 在APIdesc示例中, parameters元素在topic或reference任何地方都不是有效内容。 要使用它,您需要为参数创建有效的上下文,一直到主题级别的容器。 要将parameters元素公开给您的作者,您需要专门研究以下几部分:
- 一个
body元素,允许参数作为有效内容(为我们提供APIbody) - 一个
topic元素,以允许专门机构使用(为我们提供APIdesc)
通过使用域专门化可以避免这种多米诺骨牌效应。 如果你真的只是想一些新的变体结构添加到现有的信息类型,使用领域的专业化,而不是主题专门化(见“专业DITA域” 相关主题 )。
为了确保专用元素比它们的一般等效物受到更多的约束(即,它们允许通用等效物允许的结构的适当子集),您需要查看常规元素的内容模型。 您可以安全地更改专用元素的内容模型,如表4所示:
表4.专业化规则摘要
| 内容类型 | 示例(特殊专业通用) | |
|---|---|---|
| 需要 | 仅重命名 | |
| 可选的 (?) | 重命名,设置为必填项或删除 | |
| 一个或多个(+) | 重命名,设为必填,拆分为必填元素和其他元素,拆分为一个或多个元素以及其他元素。 | |
| 零个或多个(*) | 重命名,设为必填,设为可选,拆分为必填元素加其他元素,拆分为可选元素加其他元素,拆分为一个或多个加其他元素,拆分为零个或多个加其他元素或删除 | |
| 两者任一 | 重命名或选择一个 | |
扩展示例
您有一个通用元素General ,其内容模型为(a,b?,(c | d +))。 此定义意味着General始终包含元素a ,可选地后面跟元素b ,并且始终以c或一个或多个d结尾。
清单A.常规元素General的内容模型
当您使General专用于创建Special ,其内容模型必须具有或更高的限制:它不能比General允许更多的事情,否则您将无法向上映射或保证General流程,变换或样式表的正确行为。
除了重命名(始终允许重命名,这总是意味着您还专门化了Special可以包含的某些元素),这是您可以对Special的内容模型进行的一些有效更改,从而导致相同或更多的限制内容规则:
清单B.对特殊模型的有效更改,使b为强制性
Special现在要求存在b ,而不是可选的,并且只允许一个d 。 它安全地映射到General 。
清单C.对特殊模型的有效更改,使c为必需,不允许d
Special现在需要存在c ,而不再允许d 。 它安全地映射到General 。
清单D.对Special模型的有效更改,使d的三个专业化成为必需
现在Special需要提供d三个专业化,并且不允许c 。 它安全地映射到General 。
类属性的详细信息
每个元素必须具有一个class属性。 class属性以空格开头和结尾,并包含一个用空格分隔的值的列表。 每个值都有两个部分:第一部分标识主题类型,第二部分(在/之后)标识元素类型。 class属性值应在DTD中声明为默认属性值。 通常,它不应由作者修改。
例:
A specialized
step 当特殊类型声明新元素时,它必须为新元素提供类属性。 class属性必须包括专用类型祖先中每个主题类型的映射,即使其中没有发生元素重命名的主题也是如此。 映射应从主题开始,并以当前元素类型结束。
例:
这是必要的,以便泛化和专用化转换可以简单而准确地映射值。 例如,如果缺少task/kwd作为值,并且我决定将此bctask映射到任务主题,则转换将不得不猜测是否要映射到kwd (如果task更通用,则适当)或保留为appname (如果适当task更专业,它是不是)。 通过始终为更通用的值提供映射,我们可以应用简单的规则,即默认情况下缺失映射必须是更专业的值,这意味着列表中的最后一个值是合适的。 尽管此示例很简单,但更复杂的层次结构(例如,深五个层次,重命名仅出现在两个和四个层次上)使这种映射必不可少。
专用类型不需要更改其未专用元素的class属性,而只需从更通用的级别按引用重用即可。 例如,由于task和bctask使用p元素而没有对其进行专门化,因此它们不需要为其声明映射。
专用类型仅为其唯一声明的元素声明class属性。 它不需要为重用或继承的元素声明class属性。
使用class属性
根据class属性值应用XSLT模板,可以将转换应用于元素类型的整个分支,而不仅仅是单个元素类型。
无论在何处检查元素名称(任何包含元素名称值的XPath语句),都需要对其进行增强,以检查元素的class属性的内容。 即使无法识别元素, class属性也可以让转换知道该元素属于已知元素的类,并可以根据其规则对其进行安全处理。
例:
该match语句将在遇到的任何li元素上工作。 即使不知道具体是什么,它也可以在step和appstep元素上工作,因为class属性告诉模板它们通常是什么。
该match语句不适用于通用li元素,但对step元素和appstep元素均适用; 即使它不知道appstep是什么,也知道将其视为step 。
确保在类属性字符串检查中包括前导和尾随空白。 否则,您可能会得到错误的匹配项(没有空格, notatask/stepaway在不应该的情况下, task/step将在notatask/stepaway上匹配)。
域专业化中的class属性
创建域专业化时,新元素仍需要class属性,但应以“ +”而不是“-”开头。 这标志着任何泛化转换将元素区别对待:领域感知的泛化转换可能具有与域主题处理不同的逻辑来处理域。
领域专业化应从主题(根主题类型)或另一个领域专业化衍生而来。 不要通过专门化已经专门化的主题类型来创建域:这可能导致不可预测的概括行为,并且体系结构当前不支持该行为。
告示
本文档中提供的信息尚未提交任何正式的IBM测试,而是“按原样”分发,没有任何明示或暗示的保证。 使用此信息或本文档中描述的任何这些技术的实现是读者的责任,并且取决于读者评估它们并将其集成到其操作环境中的能力。 尝试将这些技术应用于自己的环境的读者需要自己承担风险。
©版权所有International Business Machines Corp.,2002。保留所有权利。
翻译自: https://www.ibm.com/developerworks/xml/library/x-dita2/index.html
dota2无法最小化