https://docs.microsoft.com/en-us/azure/architecture/patterns/health-endpoint-monitoring
Implement functional checks in an application that external tools can access through exposed endpoints at regular intervals. This can help to verify that applications and services are performing correctly.
使用外部工具定期通过应用暴露的端点执行功能检查,有助于验证应用程序和服务是否正确执行。
Context and problem 问题和背景
It's a good practice, and often a business requirement, to monitor web applications and back-end services, to ensure they're available and performing correctly. However, it's more difficult to monitor services running in the cloud than it is to monitor on-premises services. For example, you don't have full control of the hosting environment, and the services typically depend on other services provided by platform vendors and others.
监控Web应用程序和后端服务以确保它们可用和正常运行,是一个很好的实践,通常是业务需求。 但是,监控云服务比监视本地服务更为困难。 例如,您没有完全控制托管环境,而且服务通常依赖于平台供应商和其他供应商提供的其他服务。
There are many factors that affect cloud-hosted applications such as network latency, the performance and availability of the underlying compute and storage systems, and the network bandwidth between them. The service can fail entirely or partially due to any of these factors. Therefore, you must verify at regular intervals that the service is performing correctly to ensure the required level of availability, which might be part of your service level agreement (SLA).
影响云托管应用程序的因素有很多,如网络延迟,底层计算和存储系统的性能和可用性以及它们之间的网络带宽。 由于任何这些因素,服务可能完全或部分失败。 因此,您必须定期验证服务是否正常执行,以确保所需的可用性级别,这可能是您的服务级别协议(SLA)的一部分。
Solution
Implement health monitoring by sending requests to an endpoint on the application. The application should perform the necessary checks, and return an indication of its status.
通过向应用程序的端点发送请求来实现健康监控。 应用程序应执行必要的检查,并返回其状态信息。
A health monitoring check typically combines two factors:
健康监测检查通常结合两个因素:
The checks (if any) performed by the application or service in response to the request to the health verification endpoint.
应用程序或服务响应健康验证端点的请求并执行的检查(如果有)。
Analysis of the results by the tool or framework that performs the health verification check.
分析健康验证检查的工具或框架的执行结果。
The response code indicates the status of the application and, optionally, any components or services it uses. The latency or response time check is performed by the monitoring tool or framework. The figure provides an overview of the pattern.
响应代码指示应用程序的状态,以及可选地使用的任何组件或服务。 延迟或响应时间检查由监视工具或框架执行。 该图提供了模式的概述。
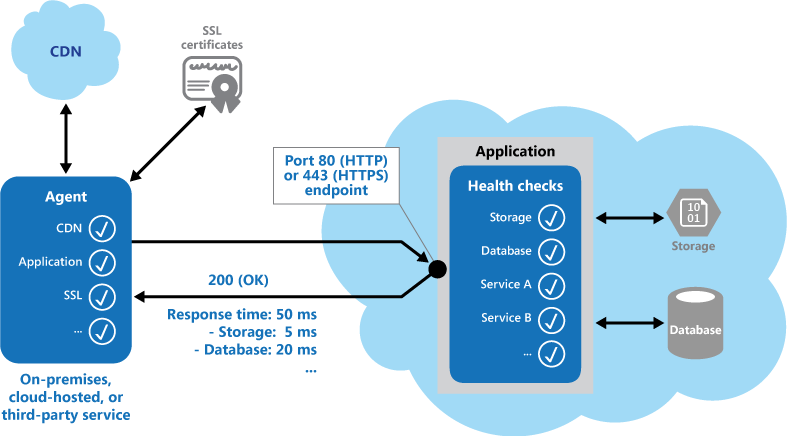
Other checks that might be carried out by the health monitoring code in the application include:
Checking cloud storage or a database for availability and response time.
Checking other resources or services located in the application, or located elsewhere but used by the application.
Services and tools are available that monitor web applications by submitting a request to a configurable set of endpoints, and evaluating the results against a set of configurable rules. It's relatively easy to create a service endpoint whose sole purpose is to perform some functional tests on the system.
应用程序中健康监控代码可能执行的其他检查包括:
检查云存储或数据库的可用性和响应时间。
检查位于应用程序中的其他资源或服务,或位于应用程序使用的其他资源或服务。
提供的服务和工具可通过向可配置的端点集提交请求来监视Web应用程序,并根据一组可配置规则评估结果。 创建服务端点相对容易,其唯一目的是对系统执行一些功能测试。
Typical checks that can be performed by the monitoring tools include:
Validating the response code. For example, an HTTP response of 200 (OK) indicates that the application responded without error. The monitoring system might also check for other response codes to give more comprehensive results.
Checking the content of the response to detect errors, even when a 200 (OK) status code is returned. This can detect errors that affect only a section of the returned web page or service response. For example, checking the title of a page or looking for a specific phrase that indicates the correct page was returned.
Measuring the response time, which indicates a combination of the network latency and the time that the application took to execute the request. An increasing value can indicate an emerging problem with the application or network.
Checking resources or services located outside the application, such as a content delivery network used by the application to deliver content from global caches.
Checking for expiration of SSL certificates.
Measuring the response time of a DNS lookup for the URL of the application to measure DNS latency and DNS failures.
Validating the URL returned by the DNS lookup to ensure correct entries. This can help to avoid malicious request redirection through a successful attack on the DNS server.
典型的检查包括:
验证响应代码。例如,HTTP响应为200(OK)表示应用程序无错误地响应。监控系统还可以检查其他响应代码,以获得更全面的结果。
检查响应的内容以检测错误,即使返回200(OK)状态代码。这可以检测到仅影响返回的网页或服务响应的一部分的错误。例如,检查页面的标题或查找指示正确页面的特定短语。
测量响应时间,这表示网络延迟与应用程序执行请求所花费的时间的组合。越来越多的价值可能表明应用程序或网络正在出现问题。
检查位于应用程序外部的资源或服务,例如应用程序使用的内容传递网络,以从全局缓存中传递内容。
检查SSL证书是否到期。
测量应用程序URL的DNS查找的响应时间,以测量DNS延迟和DNS故障。
验证DNS查找返回的URL以确保输入正确。这可以帮助避免恶意请求重定向通过成功的攻击DNS服务器。
It's also useful, where possible, to run these checks from different on-premises or hosted locations to measure and compare response times. Ideally you should monitor applications from locations that are close to customers to get an accurate view of the performance from each location. In addition to providing a more robust checking mechanism, the results can help you decide on the deployment location for the application—and whether to deploy it in more than one datacenter.
在可能的情况下,从不同的内部部署或托管位置运行这些检查来测量和比较响应时间也很有用。 理想情况下,您应该从靠近客户的位置监控应用程序,以准确地查看每个位置的性能。 除了提供更强大的检查机制之外,结果可以帮助您决定应用程序的部署位置,以及是否将其部署到多个数据中心。
Tests should also be run against all the service instances that customers use to ensure the application is working correctly for all customers. For example, if customer storage is spread across more than one storage account, the monitoring process should check all of these.
还应针对客户使用的所有服务实例运行测试,以确保应用程序正确地为所有客户运行。 例如,如果客户存储分布在多个存储帐户中,监控过程应检查所有这些。
Issues and considerations
Consider the following points when deciding how to implement this pattern:
在决定如何实现此模式时,请考虑以下几点:
How to validate the response
. For example, is just a single 200 (OK) status code sufficient to verify the application is working correctly? While this provides the most basic measure of application availability, and is the minimum implementation of this pattern, it provides little information about the operations, trends, and possible upcoming issues in the application.
如何验证响应。 例如,只是一个200(OK)状态代码足以验证应用程序是否正常工作? 虽然这提供了应用程序可用性的最基本测量,并且是此模式的最小实现,但它提供了关于应用程序中的操作,趋势和可能的即将到来的问题的少量信息。
Make sure that the application correctly returns a 200 (OK) only when the target resource is found and processed. In some scenarios, such as when using a master page to host the target web page, the server sends back a 200 (OK) status code instead of a 404 (Not Found) code, even when the target content page was not found.
确保应用程序仅在找到并处理目标资源时才正确返回200(OK)。 在某些情况下,例如,当使用母版页来托管目标网页时,即使没有找到目标内容页面,服务器也会发回200(OK)状态代码而不是404(未找到)代码。
The number of endpoints to expose for an application.
One approach is to expose at least one endpoint for the core services that the application uses and another for lower priority services, allowing different levels of importance to be assigned to each monitoring result. Also consider exposing more endpoints, such as one for each core service, for additional monitoring granularity. For example, a health verification check might check the database, storage, and an external geocoding service that an application uses, with each requiring a different level of uptime and response time. The application could still be healthy if the geocoding service, or some other background task, is unavailable for a few minutes.
应用程序对外的端点数。 一种方法是将应用程序所使用的核心服务的至少一个端点公开,另一种用于优先级较低的服务,从而允许将不同级别的重要性分配给每个监控结果。 还要考虑暴露更多的端点,例如每个核心服务的端点,以获得更多的监控粒度。 例如,健康验证检查可能会检查应用程序使用的数据库,存储和外部地理编码服务,每个需要不同级别的正常运行时间和响应时间。 如果地理编码服务或其他后台任务几分钟内不可用,应用程序仍然可以正常运行。
Whether to use the same endpoint for monitoring as is used for general access, but to a specific path designed for health verification checks, for example, /HealthCheck/{GUID}/ on the general access endpoint.
This allows some functional tests in the application to be run by the monitoring tools, such as adding a new user registration, signing in, and placing a test order, while also verifying that the general access endpoint is available.
不使用与通用访问相同的端点进行监控,而是使用专门设计用于健康验证检查的特定路径,例如通用访问端点上的/ HealthCheck / {GUID} /。 这允许应用程序中的一些功能测试由监视工具运行,例如添加新的用户注册,登录和放置测试订单,同时还验证普通访问端点是否可用。
The type of information to collect in the service in response to monitoring requests, and how to return this information. Most existing tools and frameworks look only at the HTTP status code that the endpoint returns. To return and validate additional information, you might have to create a custom monitoring utility or service.
响应监控请求在服务中收集的信息类型,以及如何返回此信息。 大多数现有的工具和框架仅查看端点返回的HTTP状态代码。 要返回并验证其他信息,您可能必须创建自定义监视实用程序或服务。
How much information to collect.
Performing excessive processing during the check can overload the application and impact other users. The time it takes might exceed the timeout of the monitoring system so it marks the application as unavailable. Most applications include instrumentation such as error handlers and performance counters that log performance and detailed error information, this might be sufficient instead of returning additional information from a health verification check.
要收集多少信息。 在检查期间执行过多的处理可能使应用程序过载,并影响其他用户。 它所需的时间可能超过监视系统的超时时间,因此将应用程序标记为不可用。 大多数应用程序包括诸如错误处理程序和性能计数器之类的工具,用于记录性能和详细的错误信息,这可能足以从健康验证检查返回附加信息。
Caching the endpoint status.
It could be expensive to run the health check too frequently. If the health status is reported through a dashboard, for example, you don't want every request from the dashboard to trigger a health check. Instead, periodically check the system health and cache the status. Expose an endpoint that returns the cached status.
缓存端点状态。 运行健康检查太频繁可能是昂贵的。 例如,如果通过仪表板报告运行状况,则不需要仪表板的每个请求来触发运行状况检查。 而是定期检查系统运行状况并缓存状态。 显示返回缓存状态的端点。
How to configure security for the monitoring endpoints to protect them from public access,
which might expose the application to malicious attacks, risk the exposure of sensitive information, or attract denial of service (DoS) attacks. Typically this should be done in the application configuration so that it can be updated easily without restarting the application. Consider using one or more of the following techniques:
如何配置监控端点的安全性以保护其免受公共访问,这可能会使应用程序暴露于恶意攻击,冒着敏感信息的暴露或吸引拒绝服务(DoS)攻击。 通常这应该在应用程序配置中完成,以便可以轻松更新,而无需重新启动应用程序。 考虑使用以下一种或多种技术:
Secure the endpoint by requiring authentication. You can do this by using an authentication security key in the request header or by passing credentials with the request, provided that the monitoring service or tool supports authentication.
通过要求身份验证来保护端点。 您可以通过在请求头中使用身份验证安全密钥或通过传递请求的凭据来进行此操作,前提是监视服务或工具支持身份验证。
Use an obscure or hidden endpoint. For example, expose the endpoint on a different IP address to that used by the default application URL, configure the endpoint on a nonstandard HTTP port, and/or use a complex path to the test page. You can usually specify additional endpoint addresses and ports in the application configuration, and add entries for these endpoints to the DNS server if required to avoid having to specify the IP address directly.使用模糊或隐藏的端点。 例如,将端点暴露在与默认应用程序URL使用的不同IP地址上,在非标准HTTP端口上配置端点和/或使用复杂d饿路径到测试页。 通常可以在应用程序配置中指定其他端点地址和端口,如果需要,可以将这些端点的条目添加到DNS服务器,以避免直接指定IP地址。
Expose a method on an endpoint that accepts a parameter such as a key value or an operation mode value. Depending on the value supplied for this parameter, when a request is received the code can perform a specific test or set of tests, or return a 404 (Not Found) error if the parameter value isn't recognized. The recognized parameter values could be set in the application configuration.在端点上暴露一个接收key/value或操作模式值参数的方法。 根据为此参数提供的值,当接收到请求时,代码可以执行特定的测试或一组测试,或者如果参数值未被识别,则返回404(未找到)错误。 识别的参数值可以在应用程序配置中设置。
DoS attacks are likely to have less impact on a separate endpoint that performs basic functional tests without compromising the operation of the application. Ideally, avoid using a test that might expose sensitive information. If you must return information that might be useful to an attacker, consider how you'll protect the endpoint and the data from unauthorized access. In this case just relying on obscurity isn't enough. You should also consider using an HTTPS connection and encrypting any sensitive data, although this will increase the load on the server. DoS攻击可能对执行基本功能测试的单独端点的影响较小,而不会影响应用程序的操作。 理想情况下,避免使用可能暴露敏感信息的测试。 如果您必须返回可能对攻击者有用的信息,请考虑如何保护端点和数据免遭未经授权的访问。 在这种情况下,只是依靠模糊性是不够的。 您还应考虑使用HTTPS连接和加密任何敏感数据,尽管这将增加服务器上的负载。
How to access an endpoint that's secured using authentication. Not all tools and frameworks can be configured to include credentials with the health verification request. For example, Microsoft Azure built-in health verification features can't provide authentication credentials. Some third-party alternatives are Pingdom
, Panopta
, NewRelic
, and Statuscake
.如何访问使用身份验证保护的端点。 并不是所有的工具和框架都可以配置为包含健康验证请求的凭据。 例如,Microsoft Azure内置的健康验证功能无法提供身份验证凭据。 一些第三方的选择是Pingdom,Panopta,NewRelic和Statuscake。
How to ensure that the monitoring agent is performing correctly. One approach is to expose an endpoint that simply returns a value from the application configuration or a random value that can be used to test the agent. 如何确保监控代理正常运行。 一种方法是公开一个简单地从应用程序配置返回值的端点或可用于测试代理的随机值。
Also ensure that the monitoring system performs checks on itself, such as a self-test and built-in test, to avoid it issuing false positive results.还要确保监控系统对自身进行检查,如自检和内置测试,以避免发生假阳性结果。
When to use this pattern
This pattern is useful for:
Monitoring websites and web applications to verify availability.
Monitoring websites and web applications to check for correct operation.
Monitoring middle-tier or shared services to detect and isolate a failure that could disrupt other applications.
Complementing existing instrumentation in the application, such as performance counters and error handlers. Health verification checking doesn't replace the requirement for logging and auditing in the application. Instrumentation can provide valuable information for an existing framework that monitors counters and error logs to detect failures or other issues. However, it can't provide information if the application is unavailable.
这种模式可用于:
监控网站和网络应用程序以验证可用性。
监控网站和网络应用程序以检查正确的操作。
监控中间层或共享服务,以检测和隔离可能会中断其他应用程序的故障。
补充应用程序中的现有工具,如性能计数器和错误处理程序。 健康验证检查不能取代应用程序中记录和审核的要求。 工具可以为监视计数器和错误日志以检测故障或其他问题的现有框架提供有价值的信息。 但是,如果应用程序不可用,则无法提供信息。
Example
The following code examples, taken from the HealthCheckController
class (a sample that demonstrates this pattern is available on GitHub
), demonstrates exposing an endpoint for performing a range of health checks.
从HealthCheckController类获取的以下代码示例(演示此模式的示例可在GitHub上获取)演示了一个端点,用于执行一系列健康检查。
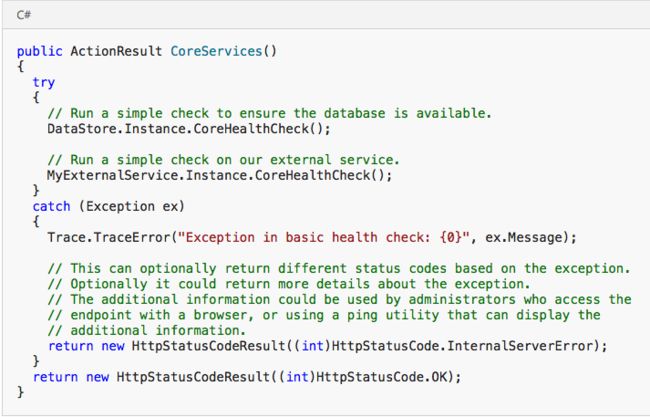
The CoreServices method, shown below in C#, performs a series of checks on services used in the application. If all of the tests run without error, the method returns a 200 (OK) status code. If any of the tests raises an exception, the method returns a 500 (Internal Error) status code. The method could optionally return additional information when an error occurs, if the monitoring tool or framework is able to make use of it.
CoreServices方法,如下面的C#所示,对应用程序中使用的服务执行一系列检查。 如果所有的测试运行没有错误,该方法返回200(OK)状态代码。 如果任何测试引发异常,该方法返回500(内部错误)状态代码。 如果监视工具或框架能够使用该方法,则该方法可以在发生错误时返回附加信息。
The ObscurePath method shows how you can read a path from the application configuration and use it as the endpoint for tests. This example, in C#, also shows how you can accept an ID as a parameter and use it to check for valid requests.

The TestResponseFromConfig method shows how you can expose an endpoint that performs a check for a specified configuration setting value.

Monitoring endpoints in Azure hosted applications
Some options for monitoring endpoints in Azure applications are:
Use the built-in monitoring features of Azure.
Use a third-party service or a framework such as Microsoft System Center Operations Manager.
Create a custom utility or a service that runs on your own or on a hosted server.
Even though Azure provides a reasonably comprehensive set of monitoring options, you can use additional services and tools to provide extra information. Azure Management Services provides a built-in monitoring mechanism for alert rules. The alerts section of the management services page in the Azure portal allows you to configure up to ten alert rules per subscription for your services. These rules specify a condition and a threshold value for a service such as CPU load, or the number of requests or errors per second, and the service can automatically send email notifications to addresses you define in each rule.
Azure应用程序中监视端点的一些选项有:
使用Azure的内置监视功能。
使用第三方服务或框架,如Microsoft System Center Operations Manager。
创建自定义实用程序或在您自己或托管服务器上运行的服务。
即使Azure提供了相当全面的监控选项,您可以使用其他服务和工具来提供额外的信息。 Azure管理服务提供内置的警报规则监视机制。 Azure门户中的管理服务页面的警报部分允许您为每个订阅服务配置最多十个警报规则。 这些规则为服务(如CPU负载)或每秒请求或错误数量指定条件和阈值,并且服务可以自动向每个规则中定义的地址发送电子邮件通知。
The conditions you can monitor vary depending on the hosting mechanism you choose for your application (such as Web Sites, Cloud Services, Virtual Machines, or Mobile Services), but all of these include the ability to create an alert rule that uses a web endpoint you specify in the settings for your service. This endpoint should respond in a timely way so that the alert system can detect that the application is operating correctly.
Read more information about
creating alert notifications
The ObscurePath method shows how you can read a path from the application configuration and use it as the endpoint for tests. This example, in C#, also shows how you can accept an ID as a parameter and use it to check for valid requests.
The TestResponseFromConfig method shows how you can expose an endpoint that performs a check for a specified configuration setting value.
监控的条件取决于您为应用程序选择的主机机制(如Web站点,云服务,虚拟机或移动服务),但所有这些机制都包括在您服务配置项中创建Web端点警报规则的功能 。 该端点应及时响应,以便警报系统可以检测到应用程序正常运行。
阅读更多有关creating alert notifications
的信息。
If you host your application in Azure Cloud Services web and worker roles or Virtual Machines, you can take advantage of one of the built-in services in Azure called Traffic Manager. Traffic Manager is a routing and load-balancing service that can distribute requests to specific instances of your Cloud Services hosted application based on a range of rules and settings.
如果您在Azure Cloud Services Web和worker roles或虚拟机中托管应用程序,则可以利用Azure中的一种内置服务称为流量管理器。 流量管理器是路由和负载均衡服务,可以根据一系列规则和设置将请求分发到云服务托管应用程序的特定实例。
In addition to routing requests, Traffic Manager pings a URL, port, and relative path that you specify on a regular basis to determine which instances of the application defined in its rules are active and are responding to requests. If it detects a status code 200 (OK), it marks the application as available. Any other status code causes Traffic Manager to mark the application as offline. You can view the status in the Traffic Manager console, and configure the rule to reroute requests to other instances of the application that are responding.
除了路由请求之外,流量管理器会定期定义您指定的URL,端口和相对路径,以确定其规则中定义的应用程序的哪些实例是活动的并且响应请求。 如果它检测到状态码200(OK),它将应用程序标记为可用。 任何其他状态码都会导致流量管理器将应用程序标记为脱机。 您可以在流量管理器控制台中查看状态,并配置规则将请求重新路由到正在响应的应用程序的其他实例。
However, Traffic Manager will only wait ten seconds to receive a response from the monitoring URL. Therefore, you should ensure that your health verification code executes in this time, allowing for network latency for the round trip from Traffic Manager to your application and back again.
Read more information about using
Traffic Manager to monitor your applications
. Traffic Manager is also discussed in Multiple Datacenter Deployment Guidance
.
但是,流量管理器只会等待十秒钟从监控URL接收到响应。 因此,您应该确保在此时间内执行完您的健康验证码,并允许从流量管理器到应用程序的网络延迟。
阅读有关使用Traffic Manager to monitor your applications
的更多信息。流量管理器还讨论了Multiple Datacenter Deployment Guidance
。
Related guidance
The following guidance can be useful when implementing this pattern:
Instrumentation and Telemetry Guidance
. Checking the health of services and components is typically done by probing, but it's also useful to have information in place to monitor application performance and detect events that occur at runtime. This data can be transmitted back to monitoring tools as additional information for health monitoring. Instrumentation and Telemetry Guidance explores gathering remote diagnostics information that's collected by instrumentation in applications. 检查服务和组件的运行状况通常是通过探测来完成的,但是也可以使用信息来监控应用程序性能并检测运行时发生的事件。 该数据可以作为健康监测的附加信息传回监控工具。 仪器和遥测指导探索收集仪器在应用程序中收集的远程诊断信息。
Receiving alert notifications
.
This pattern includes a downloadable sample application
.