return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Replacing columns cSerDe may be incompati
删除表字段会报数据不一致,报错如下
INFO : Executing command(queryId=hive_20190806170220_4bd826b5-21cc-4a31-9fe4-3fa14ada0ede): ALTER TABLE flume.biprod replace columns ( title string comment '影片名称',show_nums int comment '场次',people_nums decimal(20, 1) comment '人次(万)',box_office decimal(20, 2) comment '票房(万)')
INFO : Starting task [Stage-0:DDL] in serial mode
ERROR : FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Replacing columns cannot drop columns for table flume.biprod. SerDe may be incompatible
INFO : Completed executing command(queryId=hive_20190806170220_4bd826b5-21cc-4a31-9fe4-3fa14ada0ede); Time taken: 0.015 seconds
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Replacing columns cannot drop columns for table flume.biprod. SerDe may be incompatible (state=42000,code=1)
经核查创建内部表默认格式是ORC格式,把建表语句格式更改成其他或者按照下面的博客更改,我是更改成其他格式即可
create table biprod
(
title string comment '影片名称',
show_nums int comment '场次',
people_nums decimal(20, 1) comment '人次(万)',
box_office decimal(20, 2) comment '票房(万)'
) partitioned by (day string comment '操作时间') row format delimited fields terminated by '\t';
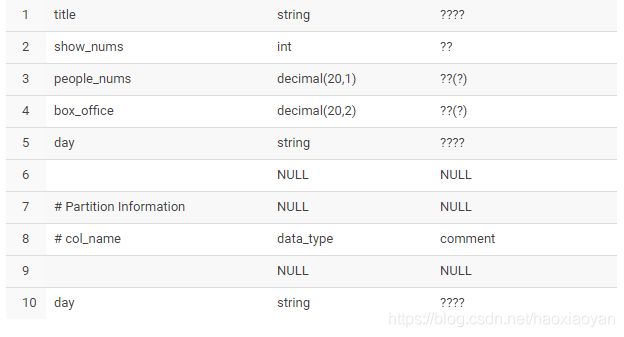
show create table biprod
create table biprod
(
title string comment '影片名称',
show_nums int comment '场次',
people_nums decimal(20, 1) comment '人次(万)',
box_office decimal(20, 2) comment '票房(万)'
) partitioned by (day string comment '操作时间')
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'='\t',
'serialization.format'='\t')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'/hive/warehouse/test.db/biprod'
TBLPROPERTIES (
'transient_lastDdlTime'='1565083359')

alter table biprod add columns (movie_code string) cascade
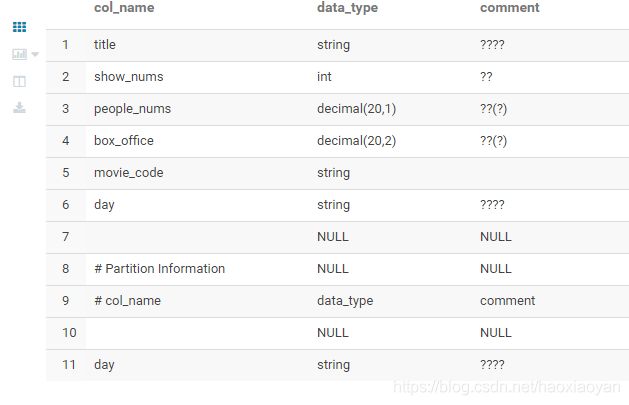
desc biprod
drop table biprod
ALTER TABLE product.biprod replace columns ( title string comment '影片名称',show_nums int comment '场次',people_nums decimal(20, 1) comment '人次(万)',box_office decimal(20, 2) comment '票房(万)');
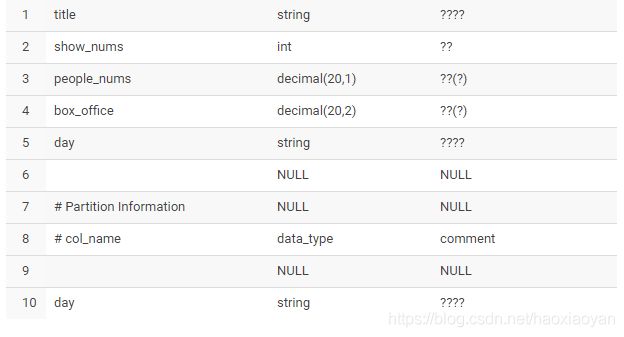
当我们修改hive表结构以后,mysql中元数据库中的SDS中该hive表对应的CD_ID会改变,但是该hive表旧的分区下面对应的CD_ID还是原来表的CD_ID
如下是根据网上找的方式给的理由
解决方案:1.改变存储格式,另外
该方法同样适用解决(对Hive分区表新增字段后,在执行插入分区的动作,会发现其实数据文件中已经有新字段值了,但是在查询的时候新字段的值还是显示为null)
测试表:biprod,
查看表的CD_ID:select CD_ID from SDS where LOCATION='hdfs://test/user/hive/warehouse/test.db/biprod',(假设新的CD_ID值为105749)
该hive表的新增字段后的分区的CD_ID:SELECT CD_ID FROM SDS WHERE LOCATION LIKE '%hdfs://test/user/hive/warehouse/test.db/biprod'(CD_ID值为105749)
该hive表的新增字段后的分区的CD_ID:SELECT CD_ID FROM SDS WHERE LOCATION LIKE '%hdfs://test/user/hive/warehouse/test.db/biprod''(CD_ID值为71806)
我们需要更新一下现有分区的CD_ID的值为表CD_ID的值:
UPDATE SDS SET CD_ID=105749 WHERE LOCATION LIKE '%hdfs://test/user/hive/warehouse/test.db/biprod%'
然后我们再去查询一下表biprod,字段的值就可以正常的显示出来了。
注意问题:
如果出现hive表不能修改,可直接更改hive元表
1、SELECT * FROM COLUMNS_V2 WHERE CD_ID=105749 ORDER BY INTEGER_IDX
2、INSERT INTO ?COLUMNS_V2 (CD_ID,COLUMN_NAME,TYPE_NAME,INTEGER_IDX) VALUES(105749,'adx','string',0)
3、禁止设置矢量查询
#矢量查询(Vectorized query) 每次处理数据时会将1024行数据组成一个batch进行处理,而不是一行一行进行处理,这样能够显著提高执行速度。
set hive.vectorized.execution.enabled = false;
4、如果在hive中执行 desc biprod依旧卡着不动,很有可能是表处于被锁的状态
执行 show locks biprod
查看表的状态,如果为 Exclusive(排他锁),继续执行 unlockbiprod命令解锁
参考如下博客
https://blog.csdn.net/u010010664/article/details/73379509
http://www.dbaglobe.com