第三十九期-ARM Linux内核的中断(9)
作者:罗宇哲,中国科学院软件研究所智能软件研究中心
上一期中工作队列相关的关键数据结构,这一期我们将介绍与工作队列相关的关键函数。
一、ARM Linux内核中与工作队列相关的关键函数
与工作队列相关的关键函数主要涉及工作项的添加、工作者线程的运行、工作的处理和工作者的调度等。
工作项的添加通过函数调用链queue_work()->queue_work_on()->__queue_work()完成。queue_work()函数的源码可以在openeuler/kernel/blob/kernel-4.19/include/linux/workqueue.h文件中找到,后两个函数的源码都可以在openeuler/kernel/blob/kernel-4.19/kernel/workqueue.c文件中找到。
queue_work()函数直接调用了queue_work_on()函数:

queue_work_on()函数关中断并调用__queue_work()将工作项加入特定处理器相关的工作队列(相关关系由工作队列是否绑定处理器决定)。WORK_STRUCT_PENDING_BIT这个位表示工作项是否处于pending状态,test_and_set_bit()函数将相关位置为一,并返回原值。这意味着只有工作项不处于pending状态时才会被加入工作队列。queue_work_on()函数的源码如下:
/**
* queue_work_on - queue work on specific cpu
* @cpu: CPU number to execute work on
* @wq: workqueue to use
* @work: work to queue
*
* We queue the work to a specific CPU, the caller must ensure it
* can't go away.
*
* Return: %false if \@work was already on a queue, %true otherwise.
*/
bool queue_work_on(int cpu, struct workqueue_struct *wq,
struct work_struct *work)
{
bool ret = false;
unsigned long flags;
local_irq_save(flags);
if (!test_and_set_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))) {
__queue_work(cpu, wq, work);
ret = true;
}
local_irq_restore(flags);
return ret;
}
EXPORT_SYMBOL(queue_work_on);
其中__queue_work()函数的代码如下:
static void __queue_work(int cpu, struct workqueue_struct *wq,
struct work_struct *work)
{
struct pool_workqueue *pwq;
struct worker_pool *last_pool;
struct list_head *worklist;
unsigned int work_flags;
unsigned int req_cpu = cpu;
/*
* While a work item is PENDING && off queue, a task trying to
* steal the PENDING will busy-loop waiting for it to either get
* queued or lose PENDING. Grabbing PENDING and queueing should
* happen with IRQ disabled.
*/
lockdep_assert_irqs_disabled();
debug_work_activate(work);//检查并设置工作项的状态,用于debug和对其生命周期的监控
/* if draining, only works from the same workqueue are allowed */
if (unlikely(wq->flags & __WQ_DRAINING) &&//正在执行排空操作
WARN_ON_ONCE(!is_chained_work(wq)))
return;
retry:
/* pwq which will be used unless @work is executing elsewhere */
if (wq->flags & WQ_UNBOUND) {/*工作队列没有与处理器核绑定*/
if (req_cpu == WORK_CPU_UNBOUND)//没有指定处理器
cpu =
wq_select_unbound_cpu(raw_smp_processor_id());/*选择处理器,优先选择当前正在执行的处理器*/
pwq = unbound_pwq_by_node(wq,
cpu_to_node(cpu));/*选择内存节点对应的pool_workqueue实例*/
} else {/*工作队列与处理器核绑定*/
if (req_cpu == WORK_CPU_UNBOUND)
cpu = raw_smp_processor_id();/*选择当前正在执行的处理器*/
pwq = per_cpu_ptr(wq->cpu_pwqs,
cpu);/*选择指定处理器对应的pool_workqueue实例*/
}
/*
* If \@work was previously on a different pool, it might still be
* running there, in which case the work needs to be queued on that
* pool to guarantee non-reentrancy.
*/
last_pool = get_work_pool(work);//获取工作之前所在的work_pool
if (last_pool && last_pool != pwq->pool)
{/*如果该work_pool存在且不是当前选择的pool_workqueue所在的work_pool*/
struct worker *worker;
spin_lock(&last_pool->lock);
worker = find_worker_executing_work(last_pool,
work);//在last_pool上找到正在执行工作项work的工作者
if (worker && worker->current_pwq->wq == wq) {
pwq = worker->current_pwq;
} else {
/* meh... not running there, queue here */
spin_unlock(&last_pool->lock);
spin_lock(&pwq-\>pool->lock);
}
} else {
spin_lock(&pwq->pool->lock);
}
……
}
该函数首先调用debug_work_activate()函数检查并设置工作项的状态,便于跟踪工作项的生命周期并debug。debug_work_activate()调用了debug_object_activate()函数,这个函数属于内核中用于调试的模块,其代码在openeuler/kernel/blob/kernel-4.19/lib/debugobjects.c文件中可以找到:
/**
* debug_object_activate - debug checks when an object is activated
* @addr: address of the object
* @descr: pointer to an object specific debug description structure
* Returns 0 for success, -EINVAL for check failed.
*/
int debug_object_activate(void *addr, struct debug_obj_descr *descr)
{
……
obj = lookup_object(addr, db);
if (obj) {
switch (obj->state) {
case ODEBUG_STATE_INIT:
case ODEBUG_STATE_INACTIVE:
obj->state = ODEBUG_STATE_ACTIVE;
ret = 0;
break;
case ODEBUG_STATE_ACTIVE:
debug_print_object(obj, "activate");
state = obj->state;
raw_spin_unlock_irqrestore(&db->lock, flags);
ret = debug_object_fixup(descr->fixup_activate, addr, state);
return ret ? 0 : -EINVAL;
case ODEBUG_STATE_DESTROYED:
debug_print_object(obj, "activate");
ret = -EINVAL;
break;
default:
ret = 0;
break;
}
raw_spin_unlock_irqrestore(&db->lock, flags);
return ret;
}
……
}
debug_object_activate()函数判断obj所处的状态,如果是ODEBUG_STATE_INIT或ODEBUG_STATE_INACTIVE则将obj的状态调整为ODEBUG_STATE_ACTIVE,否则会打印相关信息并可能返回错误值。
__WQ_DRAINING位表示工作队列正在进行排空操作,如果此时加入的工作项不是由正在排空的工作项触发的(is_chained_work()函数判定),那么直接返回不添加该工作项到工作队列中,否则允许添加。
在__queue_work()函数的retry段,代码首先选择工作项对应的pool_workqueue实例并按工作项是否与处理器(处理器核)绑定区分了两种情况。如果工作项没有与处理器绑定,即(wq->flags&WQ_UNBOUND)条件为真,那么使用指定的处理器对应的内存节点的pool_workqueue实例;否则选择指定的处理器对应的pool_workqueue实例。函数unbound_pwq_by_node()用于返回未绑定处理器的pool_workqueue实例,该实例属于unbound_pwq_by_node()输入参数列表中的内存节点ID号对应的内存节点。unbound_pwq_by_node()的代码在workqueue.c文件中可以找到:
/**
* unbound_pwq_by_node - return the unbound pool_workqueue for the given node
* @wq: the target workqueue
* @node: the node ID
*
* This must be called with any of wq_pool_mutex, wq->mutex or sched RCU
* read locked.
* If the pwq needs to be used beyond the locking in effect, the caller is
* responsible for guaranteeing that the pwq stays online.
*
* Return: The unbound pool_workqueue for @node.
*/
static struct pool_workqueue *unbound_pwq_by_node(struct workqueue_struct *wq,
int node)
{
assert_rcu_or_wq_mutex_or_pool_mutex(wq);
/*
* XXX: @node can be NUMA_NO_NODE if CPU goes offline while a
* delayed item is pending. The plan is to keep CPU -> NODE
* mapping valid and stable across CPU on/offlines. Once that
* happens, this workaround can be removed.
*/
if (unlikely(node == NUMA_NO_NODE))
return wq->dfl_pwq;
return rcu_dereference_raw(wq->numa_pwq_tbl[node]);
}
内存节点包含了处理器、总线和内存,处理器可以通过总线访问节点内的内存。在NUMA架构中,处理器访问不同的内存的延迟是不同的,它访问本地内存节点的延迟小,访问远端内存节点的延迟大。函数cpu_to_node()可以返回处理器ID对应的内存节点编号,这是通过调用per_cpu机制实现的。cpu_to_node()函数的代码在openeuler/kernel/blob/kernel-4.19/include/linux/topology.h文件中可以找到:
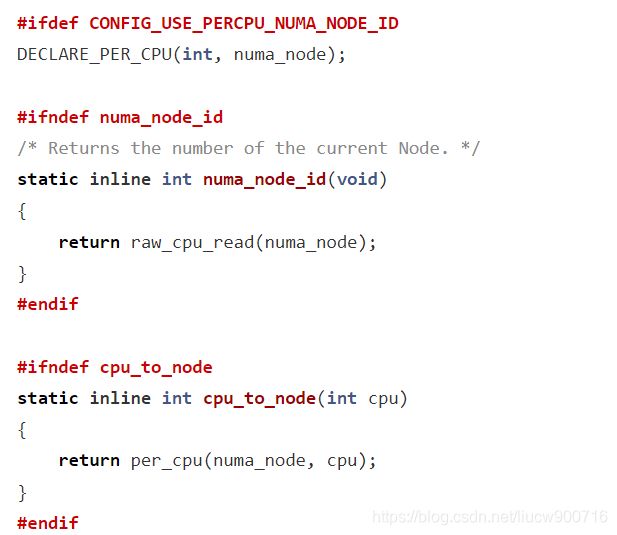
DECLARE_PER_CPU宏定义了一个处理器私有的数据段numa_node,其类型为int型,该数据段保存了处理器对应的NUMA内存节点编号,per_cpu()函数读取了指定的处理器的指定私有数据段。
WORK_CPU_UNBOUND选项表示没有指定处理器,这种情况下优先选择当前正在执行的处理器,通过函数raw_smp_processor_id()可以返回当前正在执行的处理器的ID。如果工作项没有绑定处理器,则还需要调用wq_select_unbound_cpu()函数检查当前处理器是否可行,否则会选择其他允许的处理器。
接下来函数__queue_work()调用函数get_work_pool()来找到之前工作项所在的pool_workqueue实例,如果这个pool_workqueue实例存在且与__queue_work()函数之前找到的pool_workqueue实例不同,那么有可能该工作还在原来的工作者线程中运行,为了保证了同一项工作不会同时在不同的工作队列中被执行,选择原来执行该工作项的工作者线程当前所在的pool_workqueue实例。在下一期我们将看到,如果同一个工作队列中有两项相同的工作,并且一项工作正在执行,那么另一项相同的工作将被延迟到正在执行的工作之后执行。这两个机制共同保证了不会有两个相同的工作同时在不同的线程中被执行,从而工作项的处理函数不一定要求是可重入函数。
函数find_worker_executing_work()在pool_workqueue中找到正在执行工作项的工作者,它从pool_workqueue的busy_hash表中根据工作项的地址寻找正在执行该工作项的工作者,同时工作者的工作处理函数也要和工作项匹配。find_worker_executing_work()函数的源码在workqueue.c文件中可以找到:
/**
* find_worker_executing_work - find worker which is executing a work
* @pool: pool of interest
* @work: work to find worker for
*/
static struct worker *find_worker_executing_work(struct worker_pool *pool,
struct work_struct *work)
{
struct worker *worker;
hash_for_each_possible(pool->busy_hash, worker, hentry,
(unsigned long)work)
if (worker->current_work == work &&
worker->current_func == work->func)
return worker;
return NULL;
}
二、结语
本期我们介绍了ARM Linux内核中添加工作项的关键函数,下一期我们继续介绍其他关键函数。
参考文献
- 《Linux内核深度解析》,余华兵著,2019