flume读取binlog与kafka整合
一、现将kafka调通
查看zookeeper的topic
cd /usr/software/zookeeper/zookeeper/bin
./zkCli.sh start
ls /brokers/topics
先来说一下,删除kafka无用topic
./kafka-run-class.sh kafka.admin.DeleteTopicCommand --zookeeper localhost:2181 --topic test
如果按照上述走是可以看到消息的消费的。
启动kafka
bin/kafka-server-start.sh config/server.properties
创建话题
./kafka-create-topic.sh -partition 1 -replica 1 -zookeeper centos1:2181 -topic test
看一下话题
./kafka-list-topic.sh -zookeeper centos1:2181
开启producer话题
./kafka-console-producer.sh -broker-list centos1:9092 -topic test
开启consumer
./kafka-console-consumer.sh -zookeeper centos1:2181 -topic test

二、再将flume调通
bin/flume-ng agent -c conf -f conf/flume-conf.properties -n sync &
-c:表示配置文件的目录,在此我们配置了flume-env.sh,也在conf目录下;
-f:指定配置文件,这个配置文件必须在全局选项的--conf参数定义的目录下,就是说这个配置文件要在前面配置的conf目录下面;
-n:表示要启动的agent的名称,也就是我们flume.properties配置文件里面,配置项的前缀,这里我们配的前缀是【sync】;
结果遇到报错:
[root@centos1 flume]# Info: Sourcing environment configuration script /usr/software/flume/conf/flume-env.sh
Info: Including Hive libraries found via () for Hive access
+ exec /opt/jdk1.8.0_181/bin/java -Xms100m -Xmx200m -Dcom.sun.management.jmxremote -cp '/usr/software/flume/conf:/usr/local/flume/lib/*:/lib/*' -Djava.library.path= org.apache.flume.node.Application -f conf/flume-conf.properties -n sync
错误: 找不到或无法加载主类 org.apache.flume.node.Application
flume启动Could not find or load main class org.apache.flume.node.Application
修改flume的文件夹名称后,启动flume可能会失败,错误信息如下:
Error: Could not find or load main class org.apache.flume.node.Application
这个是因为环境变量的问题。 export看一下是不是有个FLUME_HOME的环境变量指向原来的文件夹,
如果是的话:
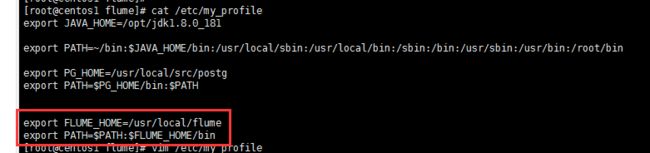
果然是环境变量配置错了,然后修改过后
source /etc/profile

此时我们向mysql表中开始插入数据发现consumer的客户端中,没有消费记录。有以下截图为准。

原因是日志报错。我们可以看一下flume日志。
flume的日志文件配置不用我说了吧。
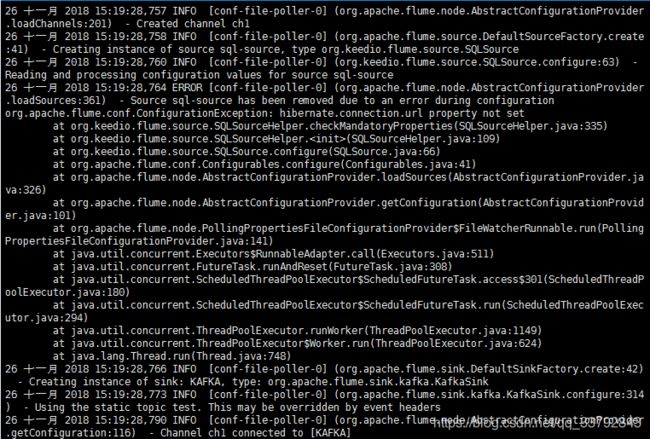
原因是缺少hibernate的配置项,看一下配置文件,果然。

所以现在需要修改,参考文档修改吧。
我们先来看看配置文件的写法
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
# For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
a1.sources.src-1.hibernate.connection.url = jdbc:mysql://centos1:3306/hr
# Hibernate Database connection properties
a1.sources.src-1.hibernate.connection.user = root
a1.sources.src-1.hibernate.connection.password =
a1.sources.src-1.hibernate.connection.autocommit = true
a1.sources.src-1.table = ef_arap
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=10000
a1.sources.src-1.status.file.path = /usr/software/flume/logs
a1.sources.src-1.status.file.name = sqlSource.status
# Custom query
a1.sources.src-1.columns.to.select = *
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
##############################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = test
a1.sinks.k1.brokerList = centos1:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel = c1
a1.sinks.k1.channel = ch-1
a1.sources.src-1.channels=ch-1
然后我们首先jps杀死以前的flume进程。
紧接着我们启动。
./bin/flume-ng agent -c conf -f conf/flume-conf.properties -n a1 &
现在可以看到日志是成功的。
可以看到consumer端已经收到了。
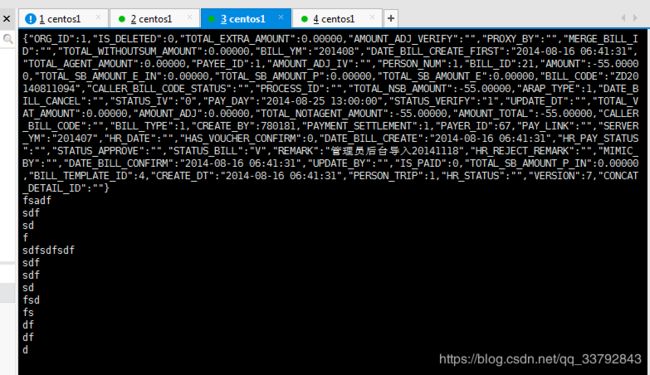
超级激动啊!但是很快日志就有报错了。

我们看一下到底是什么报错吧。
又有报错。
Cannot commit transaction. Byte capacity allocated to store event body 640000.0reached. Please increase heap space/byte capacity allocated to the channel as the sinks may not be keeping up with the sources
这个错误应该是调优的问题了。
没有问题了。
参考文章:
kafka
https://www.cnblogs.com/xiaodf/p/6093261.html#4
flume
https://blog.csdn.net/qaz1qaz1qaz2/article/details/52825459