基于深度学习的文本数据特征提取方法之Glove和FastText
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Dipanjan (DJ) Sarkar
编译:ronghuaiyang
今天接着昨天的内容,给大家介绍Glove模型和FastText模型,以及得到的词向量如何应用在机器学习任务里。
(书接上回)
GloVe模型
GloVe模型指的是全局向量模型,是一种无监督学习模型,可以获得类似于Word2Vec的dense词向量。然而,技术是不同的,训练是在一个聚合的全局词-词共现矩阵上做的,可以得到具有有意义的子结构的向量空间。这个方法是斯坦福大学的Pennington等人发明的。
我们不会在这里从头开始详细介绍模型的实现。我们在这里会保持简单,并试图理解GloVe模型背后的基本概念。我们已经讨论了基于计数的矩阵分解的方法,如LSA以及预测的方法,如Word2Vec。文章称,目前,这两个方法都存在明显的缺陷。像LSA这样的方法可以有效地利用统计信息,但在单词类比任务上,比如我们如何发现语义相似的单词,它们的表现相对较差。像skip-gram这样的方法可能在类比任务上做得更好,但是它们在全局水平上没有很好地利用语料库的统计数据。
GloVe模型的基本方法是首先创建一个由(单词,上下文)对组成的巨大单词上下文共现矩阵,这样的话,该矩阵中的每个元素表示的是这个单词与上下文一起出现的频率(可以是单词序列)。接下来的想法是应用矩阵分解来逼近这个矩阵,如下图所示。
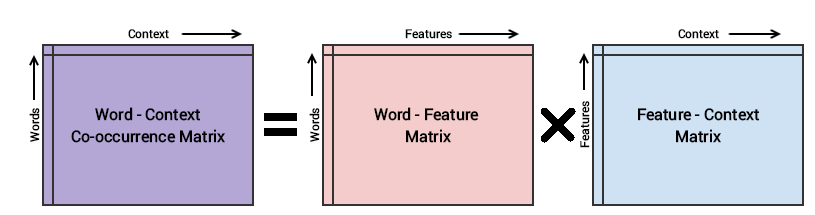
考虑Word-Context (WC)矩阵、Word-Feature (WF)矩阵和Feature-Context (FC)矩阵,我们尝试对WC = WF x FC进行因式分解,将WF和FC相乘,重构WC。为此,我们使用一些随机权重初始化WF和FC,并尝试将它们相乘以得到WC'(WC的近似形式),并度量它与WC的距离。我们多次使用随机梯度下降(SGD)来降低误差。最后,单词特征矩阵(WF)为每个单词提供单词嵌入,其中F可以预先设置为特定数量的维度。需要记住的非常重要的一点是,Word2Vec和GloVe模型的工作原理非常相似。这两种方法的目的都是建立一个向量空间,在这个空间中,每个单词的位置都受到其相邻单词的上下文和语义的影响。Word2Vec以单词共现对的本地个别示例开始,GloVe以语料库中所有单词的全局聚合共现统计数据开始。
将Glove特征应用于机器学习任务
让我们尝试使用基于GloVe的嵌入式技术来完成文档聚类任务。非常流行的spacy框架具有利用基于不同语言模型来得到GloVe嵌入。你还可以获得预先训练好的词向量,并根据需要使用gensim或spacy加载它们。我们将首先安装spacy并使用en_vectors_web_lg模型,该模型由训练在Common Crawl上的300维单词向量组成。
# Use the following command to install spaCy
> pip install -U spacy
OR
> conda install -c conda-forge spacy
# Download the following language model and store it in disk
https://github.com/explosion/spacy-models/releases/tag/en_vectors_web_lg-2.0.0
# Link the same to spacy
> python -m spacy link ./spacymodels/en_vectors_web_lg-2.0.0/en_vectors_web_lg en_vecs
Linking successful
./spacymodels/en_vectors_web_lg-2.0.0/en_vectors_web_lg --> ./Anaconda3/lib/site-packages/spacy/data/en_vecs
You can now load the model via spacy.load('en_vecs')
在spacy中也有自动安装模型的方法。现在,我们将使用spacy加载语言模型。
import spacy
nlp = spacy.load('en_vecs')
total_vectors = len(nlp.vocab.vectors)
print('Total word vectors:', total_vectors)
Total word vectors: 1070971
这验证了一切都在正常工作。现在让我们在玩具语料库中获取每个单词的GloVe嵌入。
unique_words = list(set([word for sublist in [doc.split() for doc in norm_corpus] for word in sublist]))
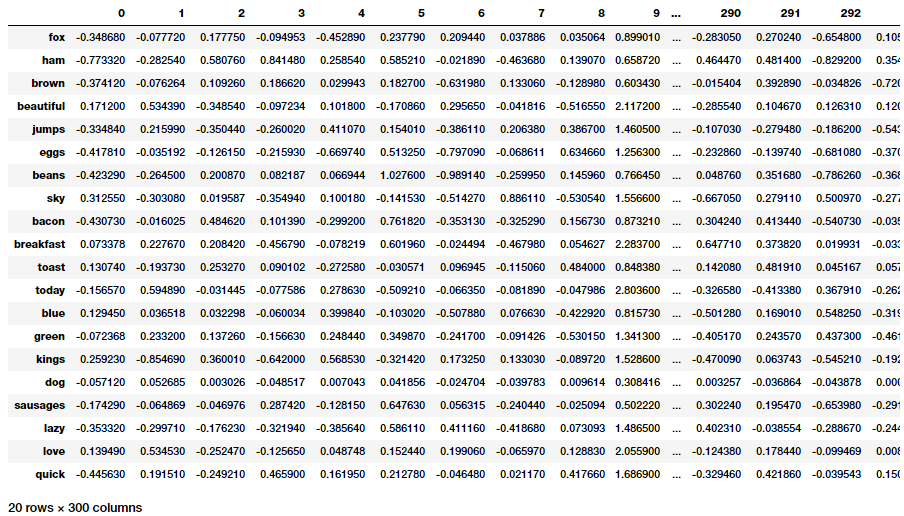
word_glove_vectors = np.array([nlp(word).vector for word in unique_words])
pd.DataFrame(word_glove_vectors, index=unique_words)
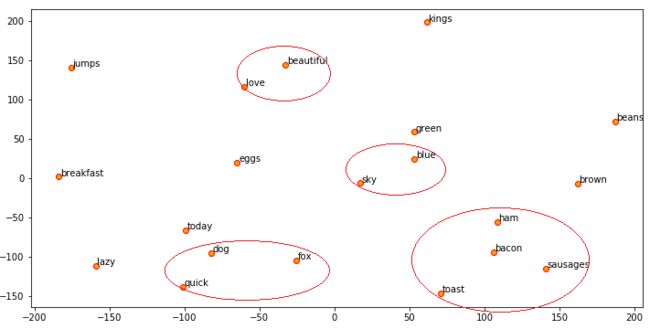
现在我们可以使用t-SNE来可视化这些嵌入,类似于我们使用Word2Vec嵌入所做的。
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=0, n_iter=5000, perplexity=3)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(word_glove_vectors)
labels = unique_words
plt.figure(figsize=(12, 6))
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')
spacy的美妙之处在于,它将自动提供每个文档中单词的平均嵌入,而无需像我们在Word2Vec中那样实现函数。我们将利用相同的方法为语料库获取文档特征,并使用k-means聚类来对文档进行聚类。
doc_glove_vectors = np.array([nlp(str(doc)).vector for doc in norm_corpus])
km = KMeans(n_clusters=3, random_state=0)
km.fit_transform(doc_glove_vectors)
cluster_labels = km.labels_
cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel'])
pd.concat([corpus_df, cluster_labels], axis=1)

我们看到一致的聚类,类似于我们从Word2Vec模型中得到的结果,这很好!GloVe模型声称在很多情况下都比Word2Vec模型表现得更好,如下图所示。
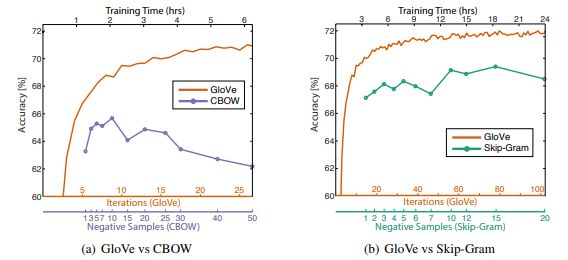
上述实验是通过在Wikipedia 2014 + Gigaword 5上训练300维向量,使用相同的40万个单词词汇表和一个大小为10的对称上下文窗口来完成的。
FastText模型
FastText模型于2016年首次由Facebook引入,作为普通Word2Vec模型的扩展和改进。基于Mikolov等人的原始论文' Subword Information Word Vectors with Subword Information',这是一本很好的读物,可以深入了解这个模型是如何工作的。总的来说,FastText是一个学习单词表示的框架,还可以执行健壮、快速和准确的文本分类。该框架由Facebook在GitHub上开源,拥有以下内容。
最新最先进的英文词向量。
在Wikipedia和crawl-vectors上训练了157种语言的词向量。
用于语言识别和各种受监督的任务的模型。
虽然我并没有从零开始实现这个模型,但是根据我的研究论文,以下是我对这个模型是如何工作的了解。一般来说,像Word2Vec模型这样的预测模型通常将每个单词视为一个不同的实体(例如where),并为单词生成dense的嵌入。然而,这是一个严重的限制,语言有大量的词汇和许多罕见的词,可能不会出现在很多不同的语料库。Word2Vec模型通常忽略每个单词的形态学结构,而将单词视为单个实体。FastText模型认为每个单词都是由n个字符组成的包。这在论文中也称为子词模型。
我们在单词的开头和结尾添加了特殊的边界符号<和>。这使我们能够从其他字符序列中区分前缀和后缀。我们还将单词w本身包含在它的n-gram集合中,以学习每个单词的表示(加上其字符的n-gram)。以单词where和n=3 (tri-grams)为例,它将由这些字符n-grams来表示:
在实际应用中,本文建议提取n≥ 3和n≤ 6。这是一种非常简单的方法,可以考虑不同的n-gram集合,例如取所有前缀和后缀。我们通常将向量表示(嵌入)与单词的每个n-gram关联起来。因此,我们可以用一个单词的n-gram的向量表示的和或者这些n-gram的嵌入的平均值来表示这个单词。因此,由于利用基于字符的单个单词的n-gram的这种效果,罕见单词获得良好表示的几率更高,因为它们基于字符的n-gram应该出现在语料库的其他单词中。
将FastText特征应用于机器学习任务
gensim包封装了很好的接口,为我们提供了gensim.models.fasttext下可用的FastText模型的接口。让我们再次把这个应用到我们的圣经语料库上,看看我们感兴趣的单词和它们最相似的单词。
from gensim.models.fasttext import FastText
wpt = nltk.WordPunctTokenizer()
tokenized_corpus = [wpt.tokenize(document) for document in norm_bible]
# Set values for various parameters
feature_size = 100 # Word vector dimensionality
window_context = 50 # Context window size
min_word_count = 5 # Minimum word count
sample = 1e-3 # Downsample setting for frequent words
# sg decides whether to use the skip-gram model (1) or CBOW (0)
ft_model = FastText(tokenized_corpus, size=feature_size, window=window_context,
min_count=min_word_count,sample=sample, sg=1, iter=50)
# view similar words based on gensim's FastText model
similar_words = {search_term: [item[0] for item in ft_model.wv.most_similar([search_term], topn=5)]
for search_term in ['god', 'jesus', 'noah', 'egypt', 'john', 'gospel', 'moses','famine']}
similar_words

可以在我们的Word2Vec模型的结果中看到许多相似之处,其中每个感兴趣的单词都有相关的相似单词。你注意到有什么有趣的关联和相似之处吗?

注意:运行此模型的计算开销较大,而且与skip-gram模型相比,通常需要更多的时间,因为它考虑了每个单词的n-gram。如果使用GPU或好的CPU进行训练,可以更好地工作。我在AWS的p2上训练过这个。例如,我花了大约10分钟,而在一个普通的系统上需要花2-3个小时。
现在让我们使用Principal Component Analysis (PCA)将单词嵌入维数减少到二维,然后将其可视化。
from sklearn.decomposition import PCA
words = sum([[k] + v for k, v in similar_words.items()], [])
wvs = ft_model.wv[words]
pca = PCA(n_components=2)
np.set_printoptions(suppress=True)
P = pca.fit_transform(wvs)
labels = words
plt.figure(figsize=(18, 10))
plt.scatter(P[:, 0], P[:, 1], c='lightgreen', edgecolors='g')
for label, x, y in zip(labels, P[:, 0], P[:, 1]):
plt.annotate(label, xy=(x+0.06, y+0.03), xytext=(0, 0), textcoords='offset points')
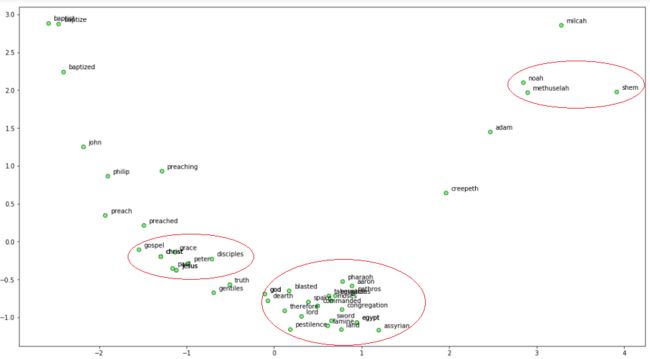
我们可以看到很多有趣的模式!诺亚、他的儿子闪和祖父玛土撒拉是非常接近的。我们还看到上帝与摩西和埃及有联系,埃及在那里忍受了圣经中的瘟疫,包括饥荒和瘟疫。此外,耶稣和他的一些门徒关系密切。
要访问任何单词embeddings,你可以使用以下的代码用单词为模型建立索引。
ft_model.wv['jesus']
array([-0.23493268, 0.14237943, 0.35635167, 0.34680951,
0.09342121,..., -0.15021783, -0.08518736, -0.28278247,
-0.19060139], dtype=float32)
有了这些嵌入,我们可以执行一些有趣的自然语言任务。其中之一是找出不同单词(实体)之间的相似性。
print(ft_model.wv.similarity(w1='god', w2='satan'))
print(ft_model.wv.similarity(w1='god', w2='jesus'))
Output
------
0.333260876685
0.698824900473
根据我们的圣经语料库中的文本,我们可以看到“上帝”与“耶稣”联系更紧密,而不是“撒旦”。
考虑到单词嵌入的存在,我们甚至可以从一堆单词中找出一些奇怪的单词,如下所示。
st1 = "god jesus satan john"
print('Odd one out for [',st1, ']:',
ft_model.wv.doesnt_match(st1.split()))
st2 = "john peter james judas"
print('Odd one out for [',st2, ']:',
ft_model.wv.doesnt_match(st2.split()))
Output
------
Odd one out for [ god jesus satan john ]: satan
Odd one out for [ john peter james judas ]: judas
总结
这些示例应该让你对利用深度学习语言模型从文本数据中提取特征,以及解决诸如单词语义、上下文和数据稀疏等问题的新策略有一个很好的了解。

英文原文:https://towardsdatascience.com/understanding-feature-engineering-part-4-deep-learning-methods-for-text-data-96c44370bbfa

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!