kafka接入学习
什么是kafka?
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
kafka有哪些优点?
1.它是一种高容错的消息发布订阅系统(因为它的数据是持久化到硬盘,可以重复读取)
2.它是高效率,有很大的吞吐量
3.它的扩展性极高,是用zookeeper集群来管理Consumer和Broker节点的动态加入与退出
4.支持实时流的方式传输数据
怎么样使用kafka?
1.首先要配置一下zookeeper的集群,这里是配置一下Zookeeper.properties
#记录节点的信息已经Kafka节点和Consumer的一些值
dataDir=/data/zookeeper
# the port at which the clients will connect
#占用到的端口
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
#心跳最长时间确定节点的存活
tickTime=2000
syncLimit=2
#初始尝试最多链接5次
initLimit=5
#集群配置
server.1=192.168.196.138:2888:3888
server.2=192.168.196.140:2888:3888
server.3=192.168.196.139:2888:3888
2.然后在配置kafka的broker的节点,这边是配置Conf里面的Server.properties文件
broker.id=0 #broker的唯一标识,集群中也不能一样
port=9092 #broker用到的端口
num.network.threads=2
num.io.threads=8 #开启多少线程同时在执行IO数据持久化
socket.send.buffer.bytes=1048576 #数据接受的缓冲大小
socket.receive.buffer.bytes=1048576 #消费时发出去的缓冲大小
socket.request.max.bytes=104857600 #一个请求会接受的最大数据量
log.dirs=/tmp/kafka-logs #日志的打印目录
num.partitions=2 #Topic默认的分区数
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=60000
log.cleaner.enable=false
zookeeper.connect=localhost:2181,192.168.196.140:2181,192.168.196.139:2181 #zookeeper集群配置
zookeeper.connection.timeout.ms=1000000
host.name=192.168.196.138 #hostname
delete.topic.enable=true #配置这个参数删除Topic的时候同时也会删除数据
3.启动zookeeper集群
./bin/zookeeper-server-start.sh ./conf/zookeeper.properties4.启动kafk的Broker节点
./bin/kafka-server-start.sh ./conf/server.properties5.创建Topic
./bin/kafka-topics.sh --create --zookeeper Master:2181 --replication-factor 2 --partitions 2 --topic test-topic6.可以查看以下kafka集群中存在的Topic
./bin/kafka-topics.sh --list --zookeeper 192.168.196.138:2181./bin/kafka-topics.sh --describe --zookeeper Master:2181--topic test-topic #查看某一个分区的具体情况7.Flume数据源传输数据到Kafka
KafkaSink的代码:这边还需要把要用到的包引入到Flume底下的lib文件夹,具体的包可以在我的百度云盘下载:点击打开链接这里面解压后又一个lib里面的所有包都拷贝进去。
package org.apache.flume.plugins;
/**
* KAFKA Flume Sink (Kafka 0.8 Beta, Flume 1.5).
* User:
* Date: 2016/03/28
* Time: PM 4:32
*/
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import org.apache.commons.lang.StringUtils;
import org.apache.flume.*;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.EventHelper;
import org.apache.flume.sink.AbstractSink;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.google.common.base.Preconditions;
import com.google.common.collect.ImmutableMap;
/**
* kafka sink.
*/
public class KafkaSink extends AbstractSink implements Configurable {
/**
* 日志记录
*/
private static final Logger LOGGER = LoggerFactory.getLogger(KafkaSink.class);
/**
* 参数
*/
private Properties parameters;
/**
* 生产者
*/
private Producer producer;
/**
* The Context.上下文
*/
private Context context;
/**
* Configure void. 参数设置
*
* @param context
* the context
*/
@Override
public void configure(Context context) {
this.context = context;
ImmutableMap props = context.getParameters();
parameters = new Properties();
for (String key : props.keySet()) {
String value = props.get(key);
this.parameters.put(key, value);
}
}
/**
* Start void.
*/
@Override
public synchronized void start() {
super.start();
ProducerConfig config = new ProducerConfig(this.parameters);
this.producer = new Producer(config);
}
/**
* Process status.
*
* @return the status
* @throws EventDeliveryException
* the event delivery exception
*/
@Override
public Status process() throws EventDeliveryException {
Status status = null;
// Start transaction
Channel ch = getChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
// This try clause includes whatever Channel operations you want to do
Event event = ch.take();
String partitionKey = (String) parameters.get(KafkaFlumeConstans.PARTITION_KEY_NAME);
String encoding = StringUtils.defaultIfEmpty(
(String) this.parameters.get(KafkaFlumeConstans.ENCODING_KEY_NAME),
KafkaFlumeConstans.DEFAULT_ENCODING);
String topic = Preconditions.checkNotNull(
(String) this.parameters.get(KafkaFlumeConstans.CUSTOME_TOPIC_KEY_NAME),
"custom.topic.name is required");
String eventData = new String(event.getBody(), encoding);
KeyedMessage data;
// if partition key does'nt exist
if (StringUtils.isEmpty(partitionKey)) {
data = new KeyedMessage(topic, eventData);
} else {
data = new KeyedMessage(topic, partitionKey, eventData);
}
if (LOGGER.isInfoEnabled()) {
LOGGER.info("Send Message to Kafka : [" + eventData + "] -- [" + EventHelper.dumpEvent(event) + "]");
}
producer.send(data);
txn.commit();
status = Status.READY;
} catch (Throwable t) {
txn.rollback();
status = Status.BACKOFF;
// re-throw all Errors
if (t instanceof Error) {
throw (Error) t;
}
} finally {
txn.close();
}
return status;
}
/**
* Stop void.
*/
@Override
public void stop() {
producer.close();
}
} @Override
public int partition(Object key, int numPartitions) {
try {
int partitionNum = Integer.parseInt((String) key);
return Math.abs(Integer.parseInt((String) key) % numPartitions);
} catch (Exception e) {
return Math.abs(key.hashCode() % numPartitions);
}
}8.写kafka消费着去消费集群中所在Topic的数据.
1.Consumer所需要用到的静态配置数据
package com.test.kafka;
/**
* Created by root on 16-3-13.
*/
public class KafkaProperties {
public final static String zkConnect="192.168.196.138:2181,192.168.196.139:2181,192.168.196.140:2181";
public final static String groupId="group1";
public final static String groupId2="group2";
public final static String topic="kafkaToptic";
public final static int kafkaProduceBufferSize=64*1024;
public final static int connectionTimeOut=20000;
public final static int reconnectInterval=10000;
public final static String topic2="topic2";
public final static String topic3="topic3";
}package com.test.kafka;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/**
* Created by root on 16-3-14.
*/
public class KafkaConsumer2 extends Thread {
private final String topic;
private final ConsumerConnector consumer;
public KafkaConsumer2(String topic){
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(createConsumerConfig());
this.topic = topic;
}
private static ConsumerConfig createConsumerConfig(){
Properties props = new Properties();
props.put("zookeeper.connect",KafkaProperties.zkConnect);
props.put("group.id",KafkaProperties.groupId2);
props.put("zookeeper.session.timeout.ms","40000");
props.put("zookeeper.sync.time.ms","200");
props.put("auto.commit.interval.ms","1000");
return new ConsumerConfig(props);
}
@Override
public void run() {
Map topicCountMap = new HashMap();
topicCountMap.put(topic, new Integer(1));
Map>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream stream = consumerMap.get(topic).get(0);
ConsumerIterator it = stream.iterator();
while(it.hasNext()){
System.out.println("receiced:"+new String(it.next().message()));
try {
sleep(3000);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
} 这里还需要把用到的Kafka相关的包给引进来,直接用maven引进就可以,下次直接补充。
我的海量日志采集架构
我这边实现一个海量日志采集平台,主要是利用Flume采集服务平台的实时日志,然后对日志进行过滤复制处理,其中正则配置只选择JSON格式的日志,复制两份日志数据,一份存入HDFS,一份传入Kafka转为实时流。其中在HDFS和Kafka两条线都做了负载均衡处理。一张整体框架图还有一张详细的数据路径图
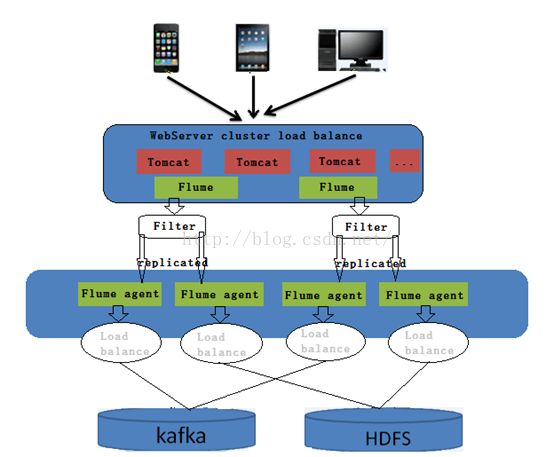

该架构的其中一条线已经在Flume的那篇博客讲述过,这边就不在重复,这边只进行Kafka这条线进行实现分析。这里上文已经知道消费者怎么进行消费,所以只需要在Flume端配置联通这个数据传输通道就能将数据稳定传输,Flume客户端启动在Flume那篇博客已经写得很清楚了。这里也不做过多介绍。
接下去写Flume接入Kafka的那个MasterClient2.conf的配置如下:
Flume配置
client2.sources = source1
client2.sinks = sink1 sink2
client2.channels = channel1
#Define a sink group which for Load balancing
client1.sinkgroups = g1
client1.sinkgroups.g1.sinks = sink1 sink2
client1.sinkgroups.g1.processor.type = load_balance
client1.sinkgroups.g1.processor.backoff = true
client1.sinkgroups.g1.processor.selector = round_robin
#Describe source
client2.sources.source1.type = avro
client2.sources.source1.channels = channel1
client2.sources.source1.port = 6666
client2.sources.source1.bind = 0.0.0.0
#Describe sink1
#client2.sinks.sink1.type = logger
client2.sinks.sink1.type = org.apache.flume.plugins.KafkaSink
client2.sinks.sink1.metadata.broker.list=192.168.196.138:9092,192.168.196.139:9092,192.168.196.140:9092
client2.sinks.sink1.zk.connect=192.168.196.138:2181,192.168.196.139:2181,192.168.196.140:2181
client2.sinks.sink1.partition.key=0
client2.sinks.sink1.partitioner.class=org.apache.flume.plugins.SinglePartition
client2.sinks.sink1.serializer.class=kafka.serializer.StringEncoder
client2.sinks.sink1.request.required.acks=1
client2.sinks.sink1.max.message.size=1000000
client2.sinks.sink1.producer.type=async
client2.sinks.sink1.custom.encoding=UTF-8
client2.sinks.sink1.custom.topic.name=kafkaToptic
#Describe sink2
#client2.sinks.sink2.type = logger
client2.sinks.sink2.type = org.apache.flume.plugins.KafkaSink
client2.sinks.sink2.metadata.broker.list=192.168.196.138:9092,192.168.196.139:9092,192.168.196.140:9092
client2.sinks.sink2.zk.connect=192.168.196.138:2181,192.168.196.139:2181,192.168.196.140:2181
client2.sinks.sink2.partition.key=0
client2.sinks.sink2.partitioner.class=org.apache.flume.plugins.SinglePartition
client2.sinks.sink2.serializer.class=kafka.serializer.StringEncoder
client2.sinks.sink2.request.required.acks=1
client2.sinks.sink2.max.message.size=1000000
client2.sinks.sink2.producer.type=async
client2.sinks.sink2.custom.encoding=UTF-8
client2.sinks.sink2.custom.topic.name=kafkaToptic
#Describe channel
client2.channels.channel1.type = memory
client2.channels.channel1.capacity = 10000
client2.channels.channel1.transactionCapacity = 1000
#bind the source/sink with channel
client2.sinks.sink1.channel = channel1
client2.sources.source1.channels = channel1