原文链接:http://tecdat.cn/?p=7303

![]()
本示例分析了使用Python和SAS 在康涅狄格州哈特福德进行的HIV预防高危药物研究的结果。这个社交网络有194个节点和273个边缘,分别代表毒品使用者和这些使用者之间的联系。
背景
SAS Viya的最新版本提供了用于探索实验问题的全套创新算法和经过验证的分析方法,但它也是基于开放式体系结构构建的。这意味着您可以将SAS Viya无缝集成到您的应用程序基础架构中,并使用任何编程语言来驱动分析模型。
先决条件
尽管您可以继续进行并简单地发出一系列REST API调用来访问数据 ,但通常使用编程语言来组织您的工作并使之可重复是更有效的。我决定使用Python,因为它在年轻的数据科学家中很流行 。
出于演示目的,我使用一个名为Jupyter的接口,该接口是一个开放的,基于Web的交互式平台,能够运行Python代码以及嵌入标记文本。
访问SAS云分析服务(CAS)
SAS Viya的核心是称为SAS Cloud Analytic Services(CAS)的分析运行时环境。为了执行操作或访问数据,需要连接会话。您可以使用二进制连接(建议使用该连接来传输大量数据),也可以通过HTTP或HTTPS通信使用REST API。
from swat import *
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors as colors # package includes utilities for color ranges
import matplotlib.cm as cmx
import networkx as nx # to render the network graph
%matplotlib inline现在已经加载了SWAT库,我们可以发出第一个命令以连接到CAS并为给定的用户创建会话。
s = CAS('http://sasviya.mycompany.com:8777', 8777, 'myuser', 'mypass')
CAS服务器将分析操作组织到操作集中。 对于此网络分析,我将使用一个名为_hyperGroup _的动作集,该动作集只有一个动作,也称为hyperGroup。
s.loadactionset('hyperGroup')
加载数据
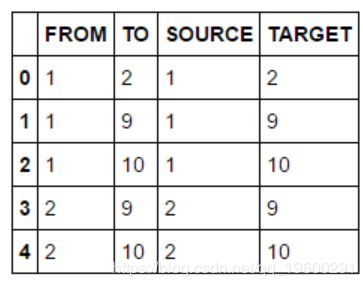
为了执行任何分析建模,我们需要数据。 将本地CSV文件上载到服务器,并将数据存储到名为_DRUG_NETWORK_的表中。该表只有两列数值类型的_FROM_和_TO_。
inputDataset = s.upload("data/drug_network.csv", casout=dict(name='DRUG_NETWORK', promote = True))
在分析建模期间,您通常必须更改数据结构,过滤或合并数据源。 这里的_put_函数将两个数字列都转换为新的字符列_SOURCE_和_TARGET_。
sasCode = 'SOURCE = put(FROM,best.); TARGET = put(TO,best.);\n'
dataset = inputDataset.datastep(sasCode,casout=dict(name='DRUG_NETWORK2', replace = True))数据探索
建立分析模型时的常见任务是首先了解您的数据。这包括简单的任务,例如检索列信息和描述性统计信息以及了解数据分布(最大值,最小值等)。下面的示例返回我先前更新的数据集的前5行。
dataset.fetch(to=5, sastypes=False, format=True) #list top 5 rows
一个简单的汇总统计数据会显示更多详细信息,包括我们数据集中273条边的总数。
dataset.summary()

图形布局
现在已经完成了前提条件,我们可以深入分析世界。首先,我们将网络可视化,以基本了解其结构和大小。我们将使用先前加载的超组动作,通过力导向算法来计算顶点的位置。Hypergroup还可以用于查找群集,计算图布局以及确定网络度量标准,例如社区和中心性。
s.hyperGroup.hyperGroup(
createOut = "NEVER", # this suppresses the creation of a table that’s usually produced, but it’s not needed here
allGraphs = True, # process all graphs even if disconnected
inputs = ["SOURCE", "TARGET"], # the source and target column indicating an edge
table = dataset, # the input data set
edges = table(name='edges',replace=True), # result table containing edge attributes
vertices = table(name='nodes',replace=True) # result table containing vertice attributes
)
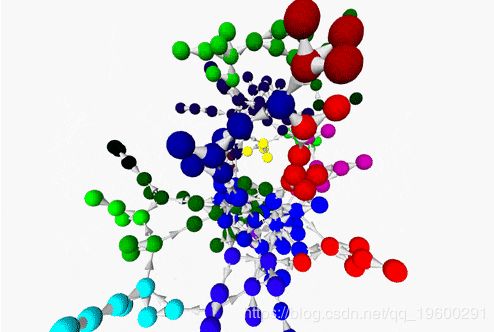
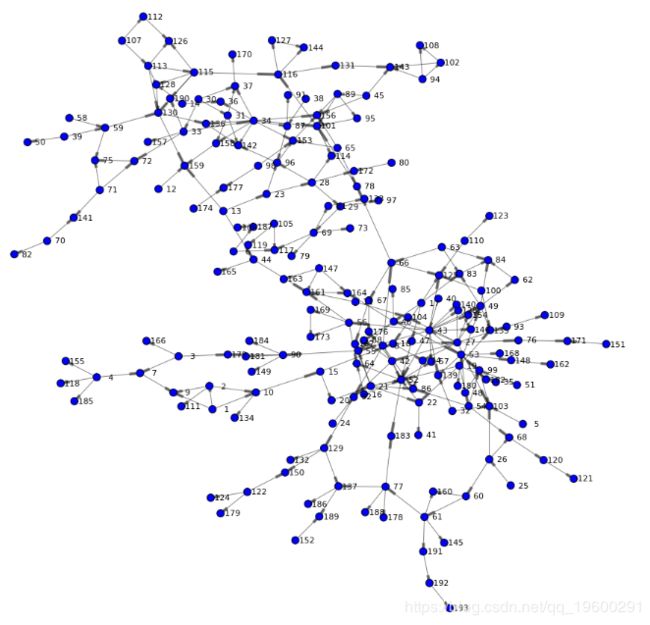
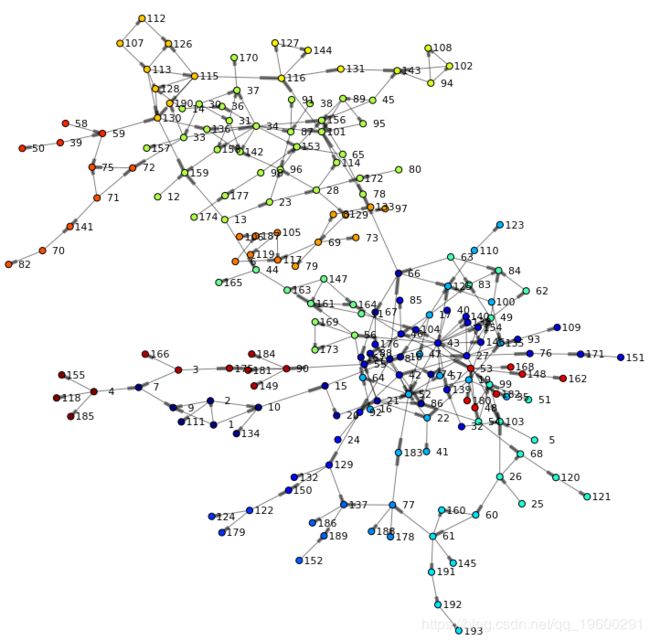
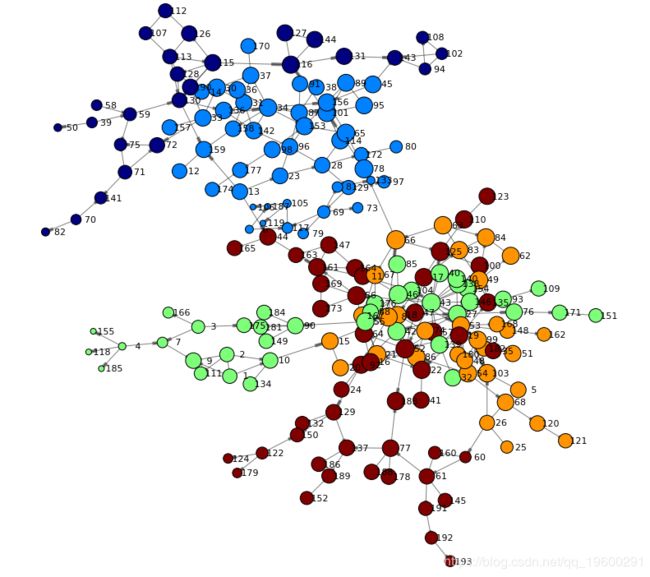
renderNetworkGraph() # a helper method to create the graph using networkx package呈现了以下网络,并提供了图形的第一视图。我们可以看到两个主要分支,并了解高密度和低密度区域。
社区检测
为了了解社交网络中用户的关系,我们将分析个人所属的社区。社区检测或聚类是将网络划分为社区,使社区子图中的链接比社区之间的链接更紧密地连接的过程。同一社区中的人们通常具有共同的属性,并表示他们之间有着密切的联系。
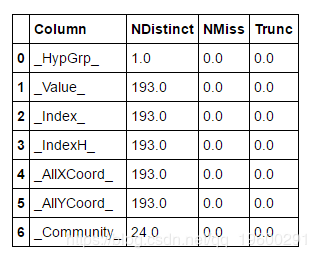
现在,更新后的节点表包含一个附加列__Community__ ,其中包含我们网络中每个节点的值。给定此数据集,我们可以执行基本统计信息,例如跨列的不同计数:
结果表显示,超群确定了我们网络中的24个社区。
让我们看一下最大的5个最大社区,并分析节点分布。
我们没有使用表格输出,而是将获取的行重定向到Python变量中。我们将使用它来生成条形图,以显示前5个最大的社区:
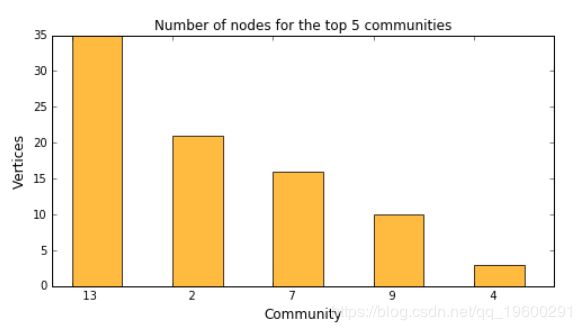
这表明最大的社区13具有35个顶点。 以下示例显示社区4中的节点:
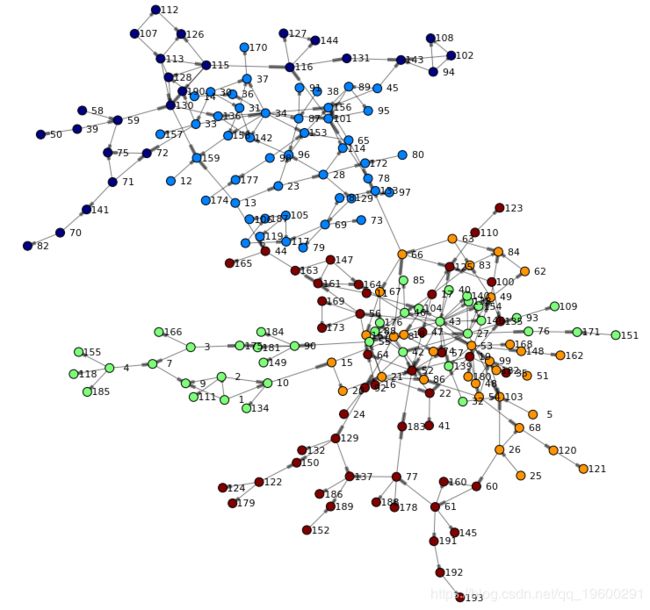
最后,让我们再次渲染网络–这次在为节点着色时考虑了社区:
通常,需要根据您的网络规模和期望的结果来调整社区的数量。您可以控制超组如何将小型社区合并为大型社区。社区可以合并:
- 随机进入邻近社区
- 进入顶点数量最少的相邻社区
- 以最大数量的顶点
- 进入已经具有_nCommunities_顶点的社区
下面将通过指定_nCommunities_参数将社区总数减少到5 。
集中性分析
分析中心性有助于确定谁在网络中很重要。重要人物将被很好地联系起来,因此对网络中的其他个人具有很高的影响力。就我们针对吸毒者的社交网络而言,这将表明潜在的病毒传播和个人的相关风险行为。
每个度量标准都表示为节点数据集中的输出列。
让我们使用集中度度量之一作为节点大小再次渲染网络。
子集网络分支
从我们的网络来看,社区2中的用户似乎扮演着重要角色。这由社区的整体中心地位,也由该社区中大多数个人的高beetweenness值表明。以下代码过滤并渲染了社区2的网络,仅使我们对该子网络有了更好的可视化。
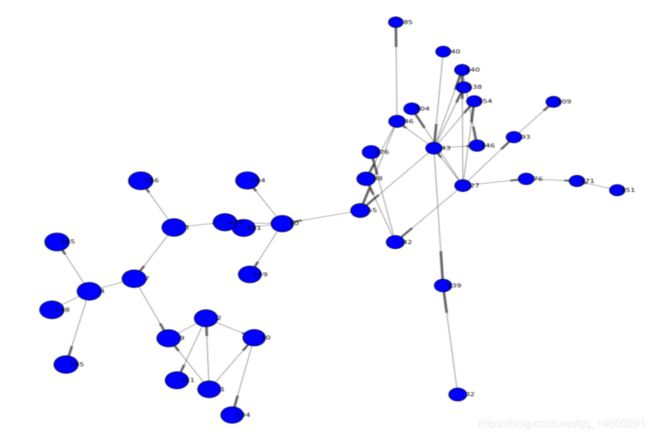
上面的示例使用了标准的二维 导向图布局。在更复杂的情况下,可能还需要在分析网络结构时考虑使用其他维度。