准备1:OpenCV常用图片转换技巧
在进行计算机视觉模型训练前,我们经常会用到图像增强的技巧来获取更多的样本,但是有些深度学习框架中的方法对图像的变换方式可能并不满足我们的需求,所以掌握OpenCV中一些常用的图像处理技巧对我们还是有很多帮助的。
图像通道分离
我们知道每个图像是由RGB三个颜色通道构成,所以我们可以使用split函数对原图像的三个通道进行分离:
B, G, R = cv2.split(img)
进行通道分离的后,我们就可以在每个通道上独立的进行数值变换,变换完成后再来组合来生成新的图像,比如提升图像的亮度:
B,G,R = cv2.split(img)
for i in (B,G,R):
randint = random.randint(50,100)
limit = 255-randint
i[i>limit]=255
i[i<=limit]=randint+i[i<=limit]
img_merge = cv2.merge((B,G,R))
cv2.imshow("img_merge",img_merge)
key = cv2.waitKey()
if key==27:
cv2.destroyAllWindows()
图像旋转
还可以使用 warpAffine 函数根据我们的设定的角度完成图像的旋转:
M = cv2.getRotationMatrix2D((img.shape[1] / 2, img.shape[0] / 2), 30, 1)
img_rotate = cv2.warpAffine(img, M, (img.shape[1], img.shape[0]))
cv2.imshow('img_rotate', img_rotate)
key = cv2.waitKey(0)
if key == 27:
cv2.destroyAllWindows()
这里我们不对图像进行缩放,旋转角度为30度。
仿射变换
仿射变换允许图像倾斜并且可以在任意两个方向上发生伸缩。代码如下:
def random_warp(img, row, col):
height, width, channels = img.shape
random_margin = 100
x1 = random.randint(-random_margin, random_margin)
y1 = random.randint(-random_margin, random_margin)
x2 = random.randint(width - random_margin - 1, width - 1)
y2 = random.randint(-random_margin, random_margin)
x3 = random.randint(width - random_margin - 1, width - 1)
y3 = random.randint(height - random_margin - 1, height - 1)
x4 = random.randint(-random_margin, random_margin)
y4 = random.randint(height - random_margin - 1, height - 1)
dx1 = random.randint(-random_margin, random_margin)
dy1 = random.randint(-random_margin, random_margin)
dx2 = random.randint(width - random_margin - 1, width - 1)
dy2 = random.randint(-random_margin, random_margin)
dx3 = random.randint(width - random_margin - 1, width - 1)
dy3 = random.randint(height - random_margin - 1, height - 1)
dx4 = random.randint(-random_margin, random_margin)
dy4 = random.randint(height - random_margin - 1, height - 1)
pts1 = np.float32([[x1, y1], [x2, y2], [x3, y3], [x4, y4]])
pts2 = np.float32([[dx1, dy1], [dx2, dy2], [dx3, dy3], [dx4, dy4]])
M_warp = cv2.getPerspectiveTransform(pts1, pts2)
img_warp = cv2.warpPerspective(img, M_warp, (width, height))
return img_warp
img_warp = random_warp(img, img.shape[0], img.shape[1])
cv2.imshow('img_warp', img_warp)
key = cv2.waitKey(0)
if key == 27:
cv2.destroyAllWindows()
伽马修正
伽马修正提升图像的对比度,让图像看起来更加的“明亮”。代码如下:
def adjust_gamma(image, gamma=1.0):
invGamma = 1.0/gamma
table = []
for i in range(256):
table.append(((i / 255.0) ** invGamma) * 255)
table = np.array(table).astype("uint8")
return cv2.LUT(image, table)
img_gamma = adjust_gamma(img, 2)
cv2.imshow("img",img)
cv2.imshow("img_gamma",img_gamma)
key = cv2.waitKey()
if key == 27:
cv2.destroyAllWindows()
准备2:下载并安装cv2
下载轮子如下:
![]()
然后直接使用pip 命令即可:
pip install opencv_python-3.4.3-cp37-cp37m-win_amd64.whl
注意:现在OpenCV for Python 就是通过Numpy 进行绑定的。所以在使用时必须掌握一些Numpy的相关知识!图像就是一个矩阵,在OpenCV for Python 中,图像就是Numpy中的数组!
1,图像的载入,显示和保存
如果读取图像,只需要imread即可。
import cv2
# 获取图片
img_path = r'1.jpg'
img = cv2.imread(img_path)
OpenCV目前支持读取bmp,jpg,png,tiff等常用格式。
我们还可以查看图像的一些基本属性:
print(img)
print(img.dtype)
print(img.shape)
接着创建一个窗口
cv2.namedWindow("Image")
然后在窗口中显示图像
cv2.imshow('Image', img)
最后还要添加一句:
cv2.waitKey(0)
如果不添加最后一句,在IDLE中执行窗口直接无响应。在命令行中执行的话,则是一闪而过。
保存图像很简单,直接cv.imwrite即可。
cv2.imwrite(save_path, crop_img)
第一个参数是保存的路径及文件名,第二个是图像矩阵。其中,imwrite()有个可选的第三个参数,如下:
cv2.imwrite("cat.jpg", img,[int(cv2.IMWRITE_JPEG_QUALITY), 5])
第三个参数针对特定的格式: 对于JPEG,其表示的是图像的质量,用0-100的整数表示,默认为95。 注意,cv2.IMWRITE_JPEG_QUALITY类型为Long,必须转换成int。下面是以不同质量存储的两幅图:

对于PNG,第三个参数表示的是压缩级别。cv2.IMWRITE_PNG_COMPRESSION,从0到9,压缩级别越高,图像尺寸越小。默认级别为3:
cv2.imwrite("./cat.png", img, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])
cv2.imwrite("./cat2.png", img, [int(cv2.IMWRITE_PNG_COMPRESSION), 9])
保存的图像尺寸如下:

还有一种支持的图像,一般不常用。
完整的程序为:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import cv2
# 获取图片
img_path = r'1.jpg'
img = cv2.imread(img_path)
cv2.namedWindow("Image")
cv2.imshow('Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
最后释放窗口是个好习惯!,查看图片效果如下:

2,转换灰度并去噪声
我们可以得到两张图片,第一张是灰度图,第二章是去噪之后的。去噪有很多种方法,均值滤波法,高斯滤波法,中值滤波器,双边滤波器等。这里展示灰度化,高斯去噪的代码:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (9, 9),0)
下图展示效果,(这里取高斯是因为高斯去噪效果是最好的)
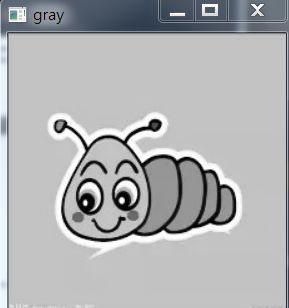
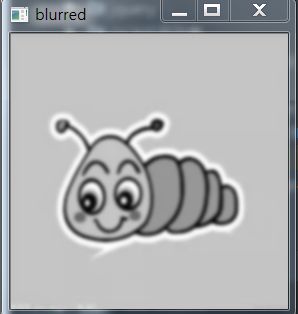
3,提取图像的梯度
用Sobel算子计算x,y方向上的梯度,之后在x方向上 minus y方向上的梯度,通过这个操作,会留下具有高水平梯度和低垂直梯度的图像区域。
代码入下:
# 提取图像的梯度
gradX = cv2.Sobel(gray, ddepth=cv2.CV_32F, dx=1, dy=0)
gradY = cv2.Sobel(gray, ddepth=cv2.CV_32F, dx=0, dy=1)
gradient = cv2.subtract(gradX, gradY)
gradient = cv2.convertScaleAbs(gradient)
此时我们会得到如下的图像:
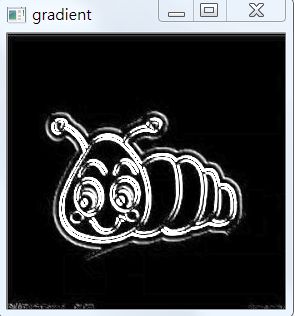
4,继续去噪声
考虑到图像的孔隙,首先使用低通滤波器平滑图像,这将有助于平滑图像中的高频噪声。低通滤波器的目的是降低图像的变化率。
如果将每个像素替换为该图像周围像素的均值,这样就可以平滑并替代那些强度变化明显的区域。
对模糊图像二值化,顾名思义就是把图像数值以某一边界分成两种数值:
blurred = cv2.GaussianBlur(gradient, (9, 9), 0)
(_, thresh) = cv2.threshold(blurred, 90, 255, cv2.THRESH_BINARY)
此时效果如下:

其实就算手动分割,我们也是需要找到一个边界,可以看出轮廓出来了,但是我们最终要的是整个轮廓,所以内部小区域就不要了。
5,图像形态学
在这里我们选取ELLIPSE核,采用CLOSE操作。
# 图像形态学
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (25, 25))
closed = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
此时,效果如下:
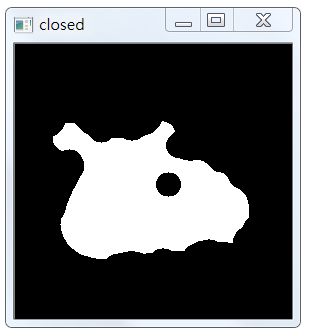
6,细节刻画
从上图我们可以发现和原图对比,发现有细节丢失,这会干扰之后的昆虫轮廓的检测,要把它们扩充,分别执行4次形态学腐蚀与膨胀,代码如下:
# 细节刻画,分别执行四次形态学腐蚀与膨胀
closed = cv2.erode(closed, None, iterations=4)
closed = cv2.dilate(closed, None, iterations=4)
效果如下:
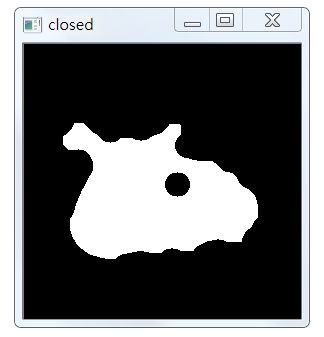
7,找出昆虫区域的轮廓,并画出
此时用 cv2.findContours() 函数如下:
(_, cnts, _) = cv2.findContours(
参数一: 二值化图像
closed.copy(),
参数二:轮廓类型
#表示只检测外轮廓
# cv2.RETR_EXTERNAL,
#建立两个等级的轮廓,上一层是边界
# cv2.RETR_CCOMP,
#检测的轮廓不建立等级关系
# cv2.RETR_LIST,
#建立一个等级树结构的轮廓
# cv2.RETR_TREE,
#存储所有的轮廓点,相邻的两个点的像素位置差不超过1
# cv2.CHAIN_APPROX_NONE,
参数三:处理近似方法
#例如一个矩形轮廓只需4个点来保存轮廓信息
# cv2.CHAIN_APPROX_SIMPLE,
# cv2.CHAIN_APPROX_TC89_L1,
# cv2.CHAIN_APPROX_TC89_KCOS
)
第一个参数是要检索的图片,必须是二值图,即黑白的(不是灰度图)。
# 这里opencv3返回的是三个参数
(_, cnts, _) = cv2.findContours(
# 参数一:二值化图像
closed.copy(),
# 参数二:轮廓类型
cv2.RETR_LIST,
cv2.CHAIN_APPROX_SIMPLE
)
c = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
rect = cv2.minAreaRect(c)
box = np.int0(cv2.boxPoints(rect))
draw_img = cv2.drawContours(img.copy(), [box], -1, (0, 0, 255), 3)
cv2.imshow("draw_img", draw_img)
此时,会得到:

8,裁剪
图像的裁剪最简单的方式就是获取图像数组的切片,如下:
img_crop = img[100:300,100:300]
cv2.imshow("img_crop", img_crop)
key = cv2.waitKey()
if key == 27:
cv2.destroyAllWindows()
当然,这里我们直接找到四个点,切出来就OK.
其实,box里保存的是绿色矩阵区域四个顶点的坐标。我们按照下图所示裁剪昆虫图像。

方法是找到四个顶点的x,y坐标的最大最小值。新图像的高等于 max(Y) - min(Y),宽等于 max(X) - min(X)。
Xs = [i[0] for i in box]
Ys = [i[1] for i in box]
x1 = min(Xs)
x2 = max(Xs)
y1 = min(Ys)
y2 = max(Ys)
hight = y2 - y1
width = x2 - x1
crop_img= img[y1:y1+hight, x1:x1+width]
cv2.imshow('crop_img', crop_img)
9,完整代码
#-*- coding: UTF-8 -*-
import cv2
import numpy as np
def get_image(path):
#获取图片
img=cv2.imread(path)
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
return img, gray
def Gaussian_Blur(gray):
# 高斯去噪
blurred = cv2.GaussianBlur(gray, (9, 9),0)
return blurred
def Sobel_gradient(blurred):
# 索比尔算子来计算x、y方向梯度
gradX = cv2.Sobel(blurred, ddepth=cv2.CV_32F, dx=1, dy=0)
gradY = cv2.Sobel(blurred, ddepth=cv2.CV_32F, dx=0, dy=1)
gradient = cv2.subtract(gradX, gradY)
gradient = cv2.convertScaleAbs(gradient)
return gradX, gradY, gradient
def Thresh_and_blur(gradient):
blurred = cv2.GaussianBlur(gradient, (9, 9),0)
(_, thresh) = cv2.threshold(blurred, 90, 255, cv2.THRESH_BINARY)
return thresh
def image_morphology(thresh):
# 建立一个椭圆核函数
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (25, 25))
# 执行图像形态学, 细节直接查文档,很简单
closed = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
closed = cv2.erode(closed, None, iterations=4)
closed = cv2.dilate(closed, None, iterations=4)
return closed
def findcnts_and_box_point(closed):
# 这里opencv3返回的是三个参数
(_, cnts, _) = cv2.findContours(closed.copy(),
cv2.RETR_LIST,
cv2.CHAIN_APPROX_SIMPLE)
c = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# compute the rotated bounding box of the largest contour
rect = cv2.minAreaRect(c)
box = np.int0(cv2.boxPoints(rect))
return box
def drawcnts_and_cut(original_img, box):
# 因为这个函数有极强的破坏性,所有需要在img.copy()上画
# draw a bounding box arounded the detected barcode and display the image
draw_img = cv2.drawContours(original_img.copy(), [box], -1, (0, 0, 255), 3)
Xs = [i[0] for i in box]
Ys = [i[1] for i in box]
x1 = min(Xs)
x2 = max(Xs)
y1 = min(Ys)
y2 = max(Ys)
hight = y2 - y1
width = x2 - x1
crop_img = original_img[y1:y1+hight, x1:x1+width]
return draw_img, crop_img
def walk():
img_path = r'C:\Users\aixin\Desktop\chongzi.png'
save_path = r'C:\Users\aixin\Desktop\chongzi_save.png'
original_img, gray = get_image(img_path)
blurred = Gaussian_Blur(gray)
gradX, gradY, gradient = Sobel_gradient(blurred)
thresh = Thresh_and_blur(gradient)
closed = image_morphology(thresh)
box = findcnts_and_box_point(closed)
draw_img, crop_img = drawcnts_and_cut(original_img,box)
# 暴力一点,把它们都显示出来看看
cv2.imshow('original_img', original_img)
cv2.imshow('blurred', blurred)
cv2.imshow('gradX', gradX)
cv2.imshow('gradY', gradY)
cv2.imshow('final', gradient)
cv2.imshow('thresh', thresh)
cv2.imshow('closed', closed)
cv2.imshow('draw_img', draw_img)
cv2.imshow('crop_img', crop_img)
cv2.waitKey(20171219)
cv2.imwrite(save_path, crop_img)
walk()
附录代码:
# 用来转化图像格式的
img = cv2.cvtColor(src,
COLOR_BGR2HSV # BGR---->HSV
COLOR_HSV2BGR # HSV---->BGR
...)
# For HSV, Hue range is [0,179], Saturation range is [0,255] and Value range is [0,255]
# 返回一个阈值,和二值化图像,第一个阈值是用来otsu方法时候用的
# 不过现在不用了,因为可以通过mahotas直接实现
T = ret = mahotas.threshold(blurred)
ret, thresh_img = cv2.threshold(src, # 一般是灰度图像
num1, # 图像阈值
num2, # 如果大于或者num1, 像素值将会变成 num2
# 最后一个二值化参数
cv2.THRESH_BINARY # 将大于阈值的灰度值设为最大灰度值,小于阈值的值设为0
cv2.THRESH_BINARY_INV # 将大于阈值的灰度值设为0,大于阈值的值设为最大灰度值
cv2.THRESH_TRUNC # 将大于阈值的灰度值设为阈值,小于阈值的值保持不变
cv2.THRESH_TOZERO # 将小于阈值的灰度值设为0,大于阈值的值保持不变
cv2.THRESH_TOZERO_INV # 将大于阈值的灰度值设为0,小于阈值的值保持不变
)
thresh = cv2.AdaptiveThreshold(src,
dst,
maxValue,
# adaptive_method
ADAPTIVE_THRESH_MEAN_C,
ADAPTIVE_THRESH_GAUSSIAN_C,
# thresholdType
THRESH_BINARY,
THRESH_BINARY_INV,
blockSize=3,
param1=5
)
# 一般是在黑色背景中找白色物体,所以原始图像背景最好是黑色
# 在执行找边缘的时候,一般是threshold 或者是canny 边缘检测后进行的。
# warning:此函数会修改原始图像、
# 返回:坐标位置(x,y),
(_, cnts, _) = cv2.findContours(mask.copy(),
# cv2.RETR_EXTERNAL, #表示只检测外轮廓
# cv2.RETR_CCOMP, #建立两个等级的轮廓,上一层是边界
cv2.RETR_LIST, #检测的轮廓不建立等级关系
# cv2.RETR_TREE, #建立一个等级树结构的轮廓
# cv2.CHAIN_APPROX_NONE, #存储所有的轮廓点,相邻的两个点的像素位置差不超过1
cv2.CHAIN_APPROX_SIMPLE, #例如一个矩形轮廓只需4个点来保存轮廓信息
# cv2.CHAIN_APPROX_TC89_L1,
# cv2.CHAIN_APPROX_TC89_KCOS
)
img = cv2.drawContours(src, cnts, whichToDraw(-1), color, line)
img = cv2.imwrite(filename, dst, # 文件路径,和目标图像文件矩阵
# 对于JPEG,其表示的是图像的质量,用0-100的整数表示,默认为95
# 注意,cv2.IMWRITE_JPEG_QUALITY类型为Long,必须转换成int
[int(cv2.IMWRITE_JPEG_QUALITY), 5]
[int(cv2.IMWRITE_JPEG_QUALITY), 95]
# 从0到9,压缩级别越高,图像尺寸越小。默认级别为3
[int(cv2.IMWRITE_PNG_COMPRESSION), 5])
[int(cv2.IMWRITE_PNG_COMPRESSION), 9])
# 如果你不知道用哪个flags,毕竟太多了哪能全记住,直接找找。
寻找某个函数或者变量
events = [i for i in dir(cv2) if 'PNG' in i]
print( events )
寻找某个变量开头的flags
flags = [i for i in dir(cv2) if i.startswith('COLOR_')]
print flags
批量读取文件名字
import os
filename_rgb = r'C:\Users\aixin\Desktop\all_my_learning\colony\20170629'
for filename in os.listdir(filename_rgb): #listdir的参数是文件夹的路径
print (filename)
参考文献:
https://mp.weixin.qq.com/s?__biz=MzUyMjE2MTE0Mw==&mid=2247485167&idx=1&sn=dd124331da063dc5adf5a9d21c97cd5f&chksm=f9d15877cea6d161c55d7cd2969a0ed8f9275e2391ad36dfda0abc77752593afedbe9351c998&scene=21#wechat_redirect
https://blog.csdn.net/sunny2038/article/category/904451
https://www.cnblogs.com/zangyu/p/5802142.html