1.概述
今天来看一下jraft的日志复制,其实读源码并不一定需要完全理解其逻辑,更重要的是对于需求的实现方式。如果能深刻领悟,应用的自己的工作中,是非常有意义的。
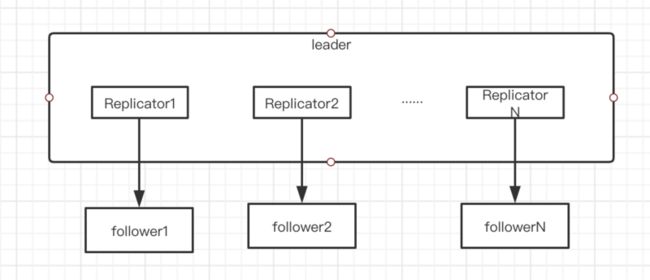
2.日志同步架构
其实主要依赖Replicator、LogManager、LogStorage这三个实现。
- Replicator,leader发送日志和心跳的功能就是在此实现。每个leader>>都会有一个ReplicatorGroup,用来管理所有followers
- LogManager用于处理日志,主要就是消费复制或者apply的日志,将其写入磁盘。
- LogStorage主要就是日志的底层存储工作。给予RocksDB。
3.源码分析
我们先从Replicator开始。首先何时创建:
当节点成为leader后,会启动所有follower和learner的replicator。其实是通过addReplicator方法实现的。
for (final PeerId peer : this.conf.listPeers()) {
if (peer.equals(this.serverId)) {
continue;
}
LOG.debug("Node {} add a replicator, term={}, peer={}.", getNodeId(), this.currTerm, peer);
if (!this.replicatorGroup.addReplicator(peer)) {
LOG.error("Fail to add a replicator, peer={}.", peer);
}
}
// Start learner's replicators
for (final PeerId peer : this.conf.listLearners()) {
LOG.debug("Node {} add a learner replicator, term={}, peer={}.", getNodeId(), this.currTerm, peer);
if (!this.replicatorGroup.addReplicator(peer, ReplicatorType.Learner)) {
LOG.error("Fail to add a learner replicator, peer={}.", peer);
}
}addReplicator方法
1.从failureReplicators中移除需要add的peer,这个肯定是要执行的。可能存在failureReplicators不存在当前peer的case。
2.复制一份集群配置,然后调用Replicator.start 方法。
3.成功的话,将返回的ThreadId 加入到replicatorMap,失败加入到failureReplicators。
Replicator是真正去完成工作的实现,ReplicatorGroup则是用来管理Replicator的实现类。
我们在编码中也可以这么做,理清楚每个点的意义,以及应该出现的地方,这么我们写出来的代码也是非常易于理解,并且鲁棒的。比如把所有Replicator共有的或者共同依赖对象可以放在ReplicatorGroup。
Replicator#start方法
1.初始化Replicator对象。
2.调用connect方法和对应节点建立连接。
3.创建ThreadId,其实是一个对Replicator对象的不可重入锁。只有获取到锁的情况Replicator才可用。其实就是维护Replicator的竞态条件。全局锁。我理解不可重入的原因就是同一线程不同操作的时候需要保证Replicator的安全。
4.执行监听回调,业务方可以实现对应监听器。
5.打开超时心跳,因为这个心跳是可动态调整的,所以并没有直接使用定时器。每次通过定时任务启动。这个方法会在每次心跳返回的时候再次调用。
final long dueTime = startMs + this.options.getDynamicHeartBeatTimeoutMs();
try {
this.heartbeatTimer = this.timerManager.schedule(() -> onTimeout(this.id), dueTime - Utils.nowMs(),
TimeUnit.MILLISECONDS);
} catch (final Exception e) {
LOG.error("Fail to schedule heartbeat timer", e);
onTimeout(this.id);
}onTimeout触发之后会发送一条心跳信息。如果这个心跳没有返回。那么leader不会一直发送心跳。
6.发送一条探测消息(sendEmptyEntries方法)。
到这里我们基本了解了Replicator的启动流程,其实就是初始化,启动心跳,发送探针消息。其实就是用来询问当前follower的复制偏移。
sendEmptyEntries方法
这个方法如果为false,代表是探测消息,如果是true代表是心跳。
什么时候发送探测消息?
- 节点刚成为leader(start)
- 发送日志超时的时候,会发送探测消息。
- 如果响应超时,如果jraft打开pipeline,会有一个pendingResponses阈值。如果响应队列数据大于这个值会调用该方法,并不会在响应超时的时候,无限loop。
- 收到无效的日志请求。
- 发送日志请求不成功
探测消息的发送逻辑
this.statInfo.runningState = RunningState.APPENDING_ENTRIES;
this.statInfo.firstLogIndex = this.nextIndex;
this.statInfo.lastLogIndex = this.nextIndex - 1;
this.appendEntriesCounter++;
this.state = State.Probe;
final int stateVersion = this.version;
final int seq = getAndIncrementReqSeq();其实就是用来探测各种异常情况,或者探测当前节点的nextIndex。
发送心跳的逻辑
这里注意其实jraft会有两种心跳。一种就是在读leader的时候会用到。后面会说。另一种就是保活心跳
if (isHeartbeat) {
// Sending a heartbeat request
this.heartbeatCounter++;
RpcResponseClosure heartbeatDone;
// Prefer passed-in closure.
if (heartBeatClosure != null) {
heartbeatDone = heartBeatClosure;
} else {
heartbeatDone = new RpcResponseClosureAdapter() {
@Override
public void run(final Status status) {
onHeartbeatReturned(Replicator.this.id, status, request, getResponse(), monotonicSendTimeMs);
}
};
}
this.heartbeatInFly = this.rpcService.appendEntries(this.options.getPeerId().getEndpoint(), request,
this.options.getElectionTimeoutMs() / 2, heartbeatDone);
} 其实follower处理心跳的逻辑比较简单。
1.根据请求的任期,进行对应的操作(更新leader或通知leader跟高的任期)
2.如果日志对不上,会返回false。并本地最后一条日志索引号。
3.如果都ok返回成功。
心跳消息的回调。RpcResponseClosureAdapter的run逻辑
1.如果不ok,也就是请求失败,启动下一轮心跳定时器。调用监听回调方法通知失败。更新Replicator的状态为probe
2.如果当前节点term失效,执行stepDown,也就是心跳响应,返回了更高的term
3.如果日志不匹配。发送探测请求。启动下一轮心跳定时器。
4.更新lastRpcSendTimestamp。
这里可以看出来,如果当前leader失效,就不会再启动心跳定时器。
上面分析了心跳和探针消息。如何处理探针消息?
我们接下来直接分析服务端如何处理AppendEntriesRequest请求。
AppendEntriesRequestProcessor#processRequest0
if (node.getRaftOptions().isReplicatorPipeline()) {
final String groupId = request.getGroupId();
final String peerId = request.getPeerId();
final int reqSequence = getAndIncrementSequence(groupId, peerId, done.getRpcCtx().getConnection());
final Message response = service.handleAppendEntriesRequest(request, new SequenceRpcRequestClosure(done,
reqSequence, groupId, peerId));
if (response != null) {
sendSequenceResponse(groupId, peerId, reqSequence, done.getRpcCtx(), response);
}
return null;
} else {
return service.handleAppendEntriesRequest(request, done);
}如果开启Pipeline,则会走前面if逻辑,对于Pipeline优化后面说。这里说一下,处理日志的是一个单线程的过程。因为没有io。通过队列异步解藕。
handleAppendEntriesRequest方法
这个方法,用于处理日志请求,心跳请求和探测请求。
因为不同的请求,都有一部分逻辑是公用的,也就是检测当前leader的合法性。
1.如果不可用,直接返回无效
2.如果请求中term小于当前term,说明leader失效。
3.检查更新当前节点的term。更新lastLeaderTimestamp
4.如果正在安装快照,那么拒绝接受该请求,返回busy。
5.如果last日志索引不一致。返回false,并返回当前lastLogIndex。
6.如果是心跳请求,或者探测请求,更新LastCommitIndex。返回相应信息。
探测请求其实就是所有follower的日志都必须跟随当前leader,如果超前,那么会多次探测,直到和leader一致。
this.ballotBox.setLastCommittedIndex(
Math.min(request.getCommittedIndex(), prevLogIndex));7.如果是日志消息,根据请求解析日志,这里每条日志都有一个EntryMeta,用于记录对应日志的元数据信息。解析完成后,如需校验则进行校验。
8.调用logManager的appendEntries 方法添加日志。并且注册了回调FollowerStableClosure 。
其实logManager成功append之后,回调会响应leader。后面会分析logManager的append。
我们再来看一下是如何处理响应消息的。
onRpcReturned方法
这个方法主要就是发送探针日志、发送正常日志、发送安装快照之后的回调。
其实首先就是对消息的预处理,比如pipeline的实现。利用了优先队列存储已响应的请求。保证消息的有序。只会按照发送顺序处理响应。如果顺序错乱则会无视所有已发送的请求。
1.如果消息版本不正确,则忽略。
2.构造响应,加入到优先队列,如果阻塞的响应过多。
3.迭代队列,如果seq不匹配,直接返回。因为raft是需要顺序处理所有响应的。
如果消息错乱那么会重置当前发送状态
void resetInflights() {
this.version++;
this.inflights.clear();
this.pendingResponses.clear();
final int rs = Math.max(this.reqSeq, this.requiredNextSeq);
this.reqSeq = this.requiredNextSeq = rs;
releaseReader();
}并在一定时间后重新发送探测消息。
4.如果有正常的消息处理,根据类型执行对应的操作。我们这里主要看处理日志消息的方法
onAppendEntriesReturned方法
这个方法才是真正处理消息的回调方法。上面的方法只是实现了消息的预处理。预处理失败就不会执行这个方法
1.如果请求不OK,则会阻塞一段时间后再测探测,而不是一直执行失败的请求。这个是物理链路问题
2.如果success为false,说明失败,清空发送请求的队列。更新nextIndex ,发送探测消息。这个是raft状态问题导致的失败。
3.如果成功,如果是探测消息,那么会更新r.state。
如果是日志消息成功,那么会调用commitAt方法更新提交偏移。
更新r.nextIndex。
if (entriesSize > 0) {
if (r.options.getReplicatorType().isFollower()) {
// Only commit index when the response is from follower.
r.options.getBallotBox().commitAt(r.nextIndex, r.nextIndex + entriesSize - 1, r.options.getPeerId());
}
} else {
// The request is probe request, change the state into Replicate.
r.state = State.Replicate;
}
r.nextIndex += entriesSize;
r.hasSucceeded = true;
r.notifyOnCaughtUp(RaftError.SUCCESS.getNumber(), false);
// dummy_id is unlock in _send_entries
if (r.timeoutNowIndex > 0 && r.timeoutNowIndex < r.nextIndex) {
r.sendTimeoutNow(false, false);
}commitAt方法。
final long startAt = Math.max(this.pendingIndex, firstLogIndex);
Ballot.PosHint hint = new Ballot.PosHint();
for (long logIndex = startAt; logIndex <= lastLogIndex; logIndex++) {
final Ballot bl = this.pendingMetaQueue.get((int) (logIndex - this.pendingIndex));
hint = bl.grant(peer, hint);
if (bl.isGranted()) {
lastCommittedIndex = logIndex;
}
}
if (lastCommittedIndex == 0) {
return true;
}
this.pendingMetaQueue.removeFromFirst((int) (lastCommittedIndex - this.pendingIndex) + 1);
this.pendingIndex = lastCommittedIndex + 1;
this.lastCommittedIndex = lastCommittedIndex;
} finally {
this.stampedLock.unlockWrite(stamp);
}
this.waiter.onCommitted(lastCommittedIndex);核心代码如上,其中pendingIndex为上一次阻塞的偏移。他为lastCommittedIndex + 1。没有真正commit的ballot都会在pendingMetaQueue中存在,每次响应成功都会调用bl.grant方法。最后根据bl.isGranted结果断定是否更新
lastCommittedIndex。
最后调用this.waiter.onCommitted执行状态机提交操作。
LogManager#appendEntries
这个方法对于follower来说主要是处理leader同步过来的日志,其中done则是成功后响应leader。
对于leader,则是用来接受客户端的Task请求。这个done则是成功后,更新提交。
public void appendEntries(final List entries,
final StableClosure done) 如果是配置日志,增加到configManager ,将日志增加到对应的disruptor 队列。
while (true) {
if (tryOfferEvent(done, translator)) {
break;
} else {
retryTimes++;
if (retryTimes > APPEND_LOG_RETRY_TIMES) {
reportError(RaftError.EBUSY.getNumber(), "LogManager is busy, disk queue overload.");
return;
}
ThreadHelper.onSpinWait();
}
}
doUnlock = false;
if (!wakeupAllWaiter(this.writeLock)) {
notifyLastLogIndexListeners();
}这里有个wakeupAllWaiter方法,如果当前节点状态为leader,这个方法其实就是通知leader继续发送日志。
因为上面说到过,如果探测消息成功,会去调用send发送日志给follower,但是如果此时没有日志,那么就会注册一个waiter。当有日志产生的时候,则会触发waiter去发送日志。这里就是出发的过程。
disruptor 的回调方法StableClosureEventHandler。
这个方法其实会调用AppendBatcher的flush方法,当然他还有一些其他的逻辑,我们不是很关注。
Flush其实就是将日志持久化到磁盘,然后回调对应日志的回调,follower的回调就是响应leader。
底层存储依赖rocksdb。
到这里,日志复制已经基本上已经全部分析完毕。
Pipeline优化
jraft不仅可以批量发送,并且实现了流式发送,对于并发管道,会存在消息乱序现象, 因为消息在网络链路耗时是不一定的。但是因为raft的性质乱序消息还是需要通过重传实现。所以jraft的实现pipeline的时候才用了单线程、单连接的模型。

- 在Replicator端,采用uniqueKey,保证单连接发送。
- 在processor的逻辑是采用单线程池解决。主要体现在PeerExecutorSelector 的select方法。
通过Inflight实现了流式发送,记录的发送顺序。
对于日志请求发送,会记录到一个先进先出的队列,这也就是需要保证raft的有序性。如果乱序,raft就不会保证算法的正确性。所以每次响应到来之后,都会按请求顺序处理响应消息。一旦顺序出现错乱,就会清空队列,重新执行发送逻辑。这样也就能做到忽略无效的响应的目的。
4.总结
1.jraft实现了批量和pipeline进行了日志发送的优化。这一点也体现了他的高性能。
2.jraft的日志复制是通过探针消息驱动的(无论是消息失败还是逻辑错乱,都会丢弃之前发送的所有请求,然后重置状态,发送探针消息),只要出现问题,都会有探针消息。每次探针正确返回,都会触发sendEntries。
为什么这样说呢,上面我们知道探测消息和快照以及正常日志消息,都会回调onRpcReturned。这个方法如果响应正常,会调用r.sendEntries() 方法。用来驱动消息的发送。如果此时没有日志要发送,则会注册一个waiter监听,当有新日志产生的时候会触发waiter去继续发送。
3.虽然单线程收发日志,但是在处理的时候都是cpu密集型任务。将io任务解藕出来,并不会有io瓶颈。
吐槽:jraft对于Replicator的加锁也是挺不容易。感觉在每个方法执行的时候都要谨慎的判断是否在锁中等。因为多种状态逻辑。导致他们需要传递锁对象,在不同的时候注意释放锁。
文章参考: