
作者:徐亚松 原文:http://www.xuyasong.com/?p=1921
监控系统的历史悠久,是一个很成熟的方向,而 Prometheus 作为新生代的开源监控系统,慢慢成为了云原生体系的事实标准,也证明了其设计很受欢迎。
本文主要分享在 Prometheus 实践中遇到的一些问题和思考,如果你对 K8S 监控体系或 Prometheus 的设计还不太了解,可以先看下容器监控系列。
几点原则:
- 监控是基础设施,目的是为了解决问题,不要只朝着大而全去做,尤其是不必要的指标采集,浪费人力和存储资源(To B商业产品例外)。
- 需要处理的告警才发出来,发出来的告警必须得到处理。
- 简单的架构就是最好的架构,业务系统都挂了,监控也不能挂。Google Sre 里面也说避免使用 Magic 系统,例如机器学习报警阈值、自动修复之类。这一点见仁见智吧,感觉很多公司都在搞智能 AI 运维。
一、版本的选择
Prometheus 当前最新版本为 2.16,Prometheus 还在不断迭代,因此尽量用最新版,1.X版本就不用考虑了。
2.16 版本上有一套实验 UI,可以查看 TSDB 的状态,包括Top 10的 Label、Metric.

二、Prometheus 的局限
- Prometheus 是基于 Metric 的监控,不适用于日志(Logs)、事件(Event)、调用链(Tracing)。
- Prometheus 默认是 Pull 模型,合理规划你的网络,尽量不要转发。
- 对于集群化和水平扩展,官方和社区都没有银弹,需要合理选择 Federate、Cortex、Thanos等方案。
- 监控系统一般情况下可用性大于一致性,容忍部分副本数据丢失,保证查询请求成功。这个后面说 Thanos 去重的时候会提到。
- Prometheus 不一定保证数据准确,这里的不准确一是指 rate、histogram_quantile 等函数会做统计和推断,产生一些反直觉的结果,这个后面会详细展开。二来查询范围过长要做降采样,势必会造成数据精度丢失,不过这是时序数据的特点,也是不同于日志系统的地方。
三、K8S 集群中常用的 exporter
Prometheus 属于 CNCF 项目,拥有完整的开源生态,与 Zabbix 这种传统 agent 监控不同,它提供了丰富的 exporter 来满足你的各种需求。你可以在这里看到官方、非官方的 exporter。如果还是没满足你的需求,你还可以自己编写 exporter,简单方便、自由开放,这是优点。
但是过于开放就会带来选型、试错成本。之前只需要在 zabbix agent里面几行配置就能完成的事,现在你会需要很多 exporter 搭配才能完成。还要对所有 exporter 维护、监控。尤其是升级 exporter 版本时,很痛苦。非官方exporter 还会有不少 bug。这是使用上的不足,当然也是 Prometheus 的设计原则。
K8S 生态的组件都会提供/metric接口以提供自监控,这里列下我们正在使用的:
- cadvisor: 集成在 Kubelet 中。
- kubelet: 10255为非认证端口,10250为认证端口。
- apiserver: 6443端口,关心请求数、延迟等。
- scheduler: 10251端口。
- controller-manager: 10252端口。
- etcd: 如etcd 写入读取延迟、存储容量等。
- docker: 需要开启 experimental 实验特性,配置 metrics-addr,如容器创建耗时等指标。
- kube-proxy: 默认 127 暴露,10249端口。外部采集时可以修改为 0.0.0.0 监听,会暴露:写入 iptables 规则的耗时等指标。
- kube-state-metrics: K8S 官方项目,采集pod、deployment等资源的元信息。
- node-exporter: Prometheus 官方项目,采集机器指标如 CPU、内存、磁盘。
- blackbox_exporter: Prometheus 官方项目,网络探测,dns、ping、http监控
- process-exporter: 采集进程指标
- nvidia exporter: 我们有 gpu 任务,需要 gpu 数据监控
- node-problem-detector: 即 npd,准确的说不是 exporter,但也会监测机器状态,上报节点异常打 taint
- 应用层 exporter: mysql、nginx、mq等,看业务需求。
还有各种场景下的自定义 exporter,如日志提取后面会再做介绍。
四、K8S 核心组件监控与 Grafana 面板
k8s 集群运行中需要关注核心组件的状态、性能。如 kubelet、apiserver 等,基于上面提到的 exporter 的指标,可以在 Grafana 中绘制如下图表:

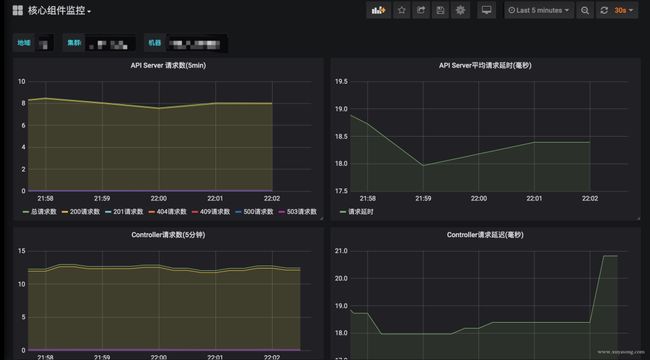
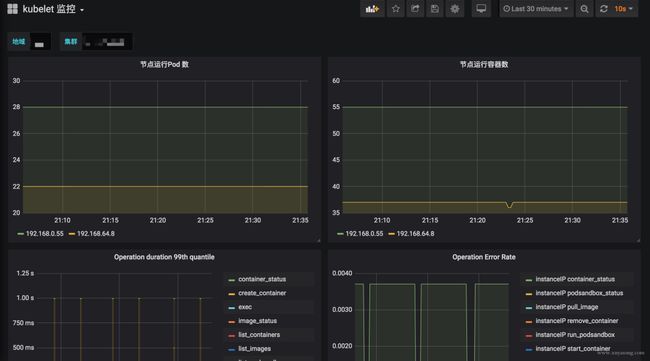
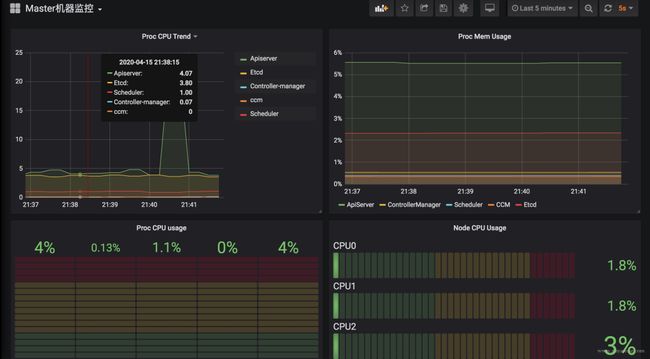
模板可以参考dashboards-for-kubernetes-administrators,根据运行情况不断调整报警阈值。
这里提一下 Grafana 虽然支持了 templates 能力,可以很方便地做多级下拉框选择,但是不支持templates 模式下配置报警规则,相关issue
官方对这个功能解释了一堆,可最新版本仍然没有支持。借用 issue 的一句话吐槽下:
It would be grate to add templates support in alerts. Otherwise the feature looks useless a bit.五、采集组件 All IN One
Prometheus 体系中 Exporter 都是独立的,每个组件各司其职,如机器资源用 Node-Exporter,Gpu 有Nvidia Exporter等等。但是 Exporter 越多,运维压力越大,尤其是对 Agent做资源控制、版本升级。我们尝试对一些Exporter进行组合,方案有二:
- 通过主进程拉起N个 Exporter 进程,仍然可以跟着社区版本做更新、bug fix。
- 用Telegraf来支持各种类型的 Input,N 合 1。
另外,Node-Exporter 不支持进程监控,可以加一个Process-Exporter,也可以用上边提到的Telegraf,使用 procstat 的 input来采集进程指标。
六、合理选择黄金指标
采集的指标有很多,我们应该关注哪些?Google 在“Sre Handbook”中提出了“四个黄金信号”:延迟、流量、错误数、饱和度。实际操作中可以使用 Use 或 Red 方法作为指导,Use 用于资源,Red 用于服务。
- Use 方法:Utilization、Saturation、Errors。如 Cadvisor 数据
- Red 方法:Rate、Errors、Duration。如 Apiserver 性能指标
Prometheus 采集中常见的服务分三种:
- 在线服务:如 Web 服务、数据库等,一般关心请求速率,延迟和错误率即 RED 方法
- 离线服务:如日志处理、消息队列等,一般关注队列数量、进行中的数量,处理速度以及发生的错误即 Use 方法
- 批处理任务:和离线任务很像,但是离线任务是长期运行的,批处理任务是按计划运行的,如持续集成就是批处理任务,对应 K8S 中的 job 或 cronjob, 一般关注所花的时间、错误数等,因为运行周期短,很可能还没采集到就运行结束了,所以一般使用 Pushgateway,改拉为推。
对 Use 和 Red 的实际示例可以参考容器监控实践—K8S常用指标分析这篇文章。
七、K8S 1.16中 Cadvisor 的指标兼容问题
在 K8S 1.16版本,Cadvisor 的指标去掉了 pod_Name 和 container_name 的 label,替换为了pod 和 container。如果你之前用这两个 label 做查询或者 Grafana 绘图,需要更改下 Sql 了。因为我们一直支持多个 K8S 版本,就通过 relabel配置继续保留了原来的**_name。
metric_relabel_configs: - source_labels: [container\]
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
regex: (.+)
target_label: pod_name
replacement: $1
action: replace注意要用 metric_relabel_configs,不是 relabel_configs,采集后做的replace。
八、Prometheus 采集外部 K8S 集群、多集群
Prometheus 如果部署在K8S集群内采集是很方便的,用官方给的Yaml就可以,但我们因为权限和网络需要部署在集群外,二进制运行,采集多个 K8S 集群。
以 Pod 方式运行在集群内是不需要证书的(In-Cluster 模式),但集群外需要声明 token之类的证书,并替换address,即使用 Apiserver Proxy采集,以 Cadvisor采集为例,Job 配置为:
- job_name: cluster-cadvisor
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xx:6443
role: node
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
action: labelmap
- separator: ;
regex: (.*)
target_label: __address__
replacement: xx:6443
action: replace
- source_labels: [__meta_kubernetes_node_name]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
action: replace
metric_relabel_configs:
- source_labels: [container]
separator: ;
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
separator: ;
regex: (.+)
target_label: pod_name
replacement: $1
action: replacebearer_token_file 需要提前生成,这个参考官方文档即可。记得 base64 解码。
对于 cadvisor 来说,__metrics_path__可以转换为/api/v1/nodes/{1}/proxy/metrics/cadvisor,代表Apiserver proxy 到 Kubelet,如果网络能通,其实也可以直接把 Kubelet 的10255作为 target,可以直接写为:{1}:10255/metrics/cadvisor,代表直接请求Kubelet,规模大的时候还减轻了 Apiserver 的压力,即服务发现使用 Apiserver,采集不走 Apiserver
因为 cadvisor 是暴露主机端口,配置相对简单,如果是 kube-state-metric 这种 Deployment,以 endpoint 形式暴露,写法应该是:
- job_name: cluster-service-endpoints
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xxx:6443
role: endpoints
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
separator: ;
regex: (https?)
target_label: __scheme__
replacement: $1
action: replace
- separator: ;
regex: (.*)
target_label: __address__
replacement: xxx:6443
action: replace
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
action: replace
- separator: ;
regex: __meta_kubernetes_service_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
target_label: kubernetes_namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: kubernetes_name
replacement: $1
action: replace对于 endpoint 类型,需要转换__metrics_path__为/api/v1/namespaces/{1}/services/{2}:${3}/proxy/metrics,需要替换 namespace、svc 名称端口等,这里的写法只适合接口为/metrics的exporter,如果你的 exporter 不是/metrics接口,需要替换这个路径。或者像我们一样统一约束都使用这个地址。
这里的__meta_kubernetes_service_annotation_prometheus_io_port来源就是 exporter 部署时写的那个 annotation,大多数文章中只提到prometheus.io/scrape: ‘true’,但也可以定义端口、路径、协议。以方便在采集时做替换处理。
其他的一些 relabel 如kubernetes_namespace 是为了保留原始信息,方便做 promql 查询时的筛选条件。
如果是多集群,同样的配置多写几遍就可以了,一般一个集群可以配置三类job:
- role:node 的,包括 cadvisor、 node-exporter、kubelet 的 summary、kube-proxy、docker 等指标
- role:endpoint 的,包括 kube-state-metric 以及其他自定义 Exporter
- 普通采集:包括Etcd、Apiserver 性能指标、进程指标等。
九、GPU 指标的获取
nvidia-smi可以查看机器上的 GPU 资源,而Cadvisor 其实暴露了Metric来表示容器使用 GPU 情况,
container_accelerator_duty_cycle
container_accelerator_memory_total_bytes
container_accelerator_memory_used_bytes如果要更详细的 GPU 数据,可以安装dcgm exporter,不过K8S 1.13 才能支持。
十、更改 Prometheus 的显示时区
Prometheus 为避免时区混乱,在所有组件中专门使用 Unix Time 和 Utc 进行显示。不支持在配置文件中设置时区,也不能读取本机 /etc/timezone 时区。
其实这个限制是不影响使用的:
- 如果做可视化,Grafana是可以做时区转换的。
- 如果是调接口,拿到了数据中的时间戳,你想怎么处理都可以。
- 如果因为 Prometheus 自带的 UI 不是本地时间,看着不舒服,2.16 版本的新版 Web UI已经引入了Local Timezone 的选项,区别见下图。
- 如果你仍然想改 Prometheus 代码来适应自己的时区,可以参考这篇文章。
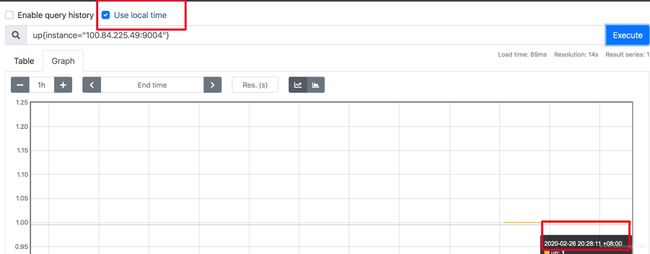
关于 timezone 的讨论,可以看这个issue。
十一、如何采集 LB 后面的 RS 的 Metric
假如你有一个负载均衡 LB,但网络上 Prometheus 只能访问到 LB 本身,访问不到后面的 RS,应该如何采集 RS 暴露的 Metric?
- RS 的服务加 Sidecar Proxy,或者本机增加 Proxy 组件,保证 Prometheus 能访问到。
- LB 增加 /backend1 和 /backend2请求转发到两个单独的后端,再由 Prometheus 访问 LB 采集。
十二、Prometheus 大内存问题
随着规模变大,Prometheus 需要的 CPU 和内存都会升高,内存一般先达到瓶颈,这个时候要么加内存,要么集群分片减少单机指标。这里我们先讨论单机版 Prometheus 的内存问题。
原因:
- Prometheus 的内存消耗主要是因为每隔2小时做一个 Block 数据落盘,落盘之前所有数据都在内存里面,因此和采集量有关。
- 加载历史数据时,是从磁盘到内存的,查询范围越大,内存越大。
这里面有一定的优化空间。
- 一些不合理的查询条件也会加大内存,如 Group 或大范围 Rate。
我的指标需要多少内存:
- 作者给了一个计算器,设置指标量、采集间隔之类的,计算 Prometheus 需要的理论内存值:计算公式
以我们的一个 Prometheus Server为例,本地只保留 2 小时数据,95 万 Series,大概占用的内存如下:


有什么优化方案:
- Sample 数量超过了 200 万,就不要单实例了,做下分片,然后通过 Victoriametrics,Thanos,Trickster 等方案合并数据。
- 评估哪些 Metric 和 Label 占用较多,去掉没用的指标。
2.14 以上可以看 Tsdb 状态
- 查询时尽量避免大范围查询,注意时间范围和 Step 的比例,慎用 Group。
- 如果需要关联查询,先想想能不能通过 Relabel 的方式给原始数据多加个 Label,一条Sql 能查出来的何必用Join,时序数据库不是关系数据库。
Prometheus 内存占用分析:
- 通过 pprof分析:
- 1.X 版本的内存:
相关 issue:
- https://groups.google.com/for...:date/prometheus-users/q4oiVGU6Bxo/uifpXVw3CwAJ
- https://github.com/prometheus...
- https://github.com/prometheus...
十三、Prometheus 容量规划
容量规划除了上边说的内存,还有磁盘存储规划,这和你的 Prometheus 的架构方案有关。
- 如果是单机Prometheus,计算本地磁盘使用量。
- 如果是 Remote-Write,和已有的 Tsdb 共用即可。
- 如果是 Thanos 方案,本地磁盘可以忽略(2H),计算对象存储的大小就行。
Prometheus 每2小时将已缓冲在内存中的数据压缩到磁盘上的块中。包括Chunks、Indexes、Tombstones、Metadata,这些占用了一部分存储空间。一般情况下,Prometheus 中存储的每一个样本大概占用1-2字节大小(1.7Byte)。可以通过Promql来查看每个样本平均占用多少空间:
rate(prometheus_tsdb_compaction_chunk_size_bytes_sum[1h])/ rate(prometheus_tsdb_compaction_chunk_samples_sum[1h]){instance="0.0.0.0:8890", job="prometheus"} 1.252747585939941如果大致估算本地磁盘大小,可以通过以下公式:
磁盘大小=保留时间*每秒获取样本数*样本大小保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果想减少本地磁盘的容量需求,只能通过减少每秒获取样本数(ingested_samples_per_second)的方式。
查看当前每秒获取的样本数:
rate(prometheus_tsdb_head_samples_appended_total[1h])有两种手段,一是减少时间序列的数量,二是增加采集样本的时间间隔。考虑到 Prometheus 会对时间序列进行压缩,因此减少时间序列的数量效果更明显。
举例说明:
采集频率 30s,机器数量1000,Metric种类6000,1000600026024 约 200 亿,30G 左右磁盘。
只采集需要的指标,如 match[], 或者统计下最常使用的指标,性能最差的指标。
以上磁盘容量并没有把 wal 文件算进去,wal 文件(Raw Data)在 Prometheus 官方文档中说明至少会保存3个 Write-Ahead Log Files,每一个最大为128M(实际运行发现数量会更多)。
因为我们使用了 Thanos 的方案,所以本地磁盘只保留2H 热数据。Wal 每2小时生成一份Block文件,Block文件每2小时上传对象存储,本地磁盘基本没有压力。
关于 Prometheus 存储机制,可以看这篇。
十四、对 Apiserver 的性能影响
如果你的 Prometheus 使用了 kubernetes_sd_config 做服务发现,请求一般会经过集群的 Apiserver,随着规模的变大,需要评估下对 Apiserver性能的影响,尤其是Proxy失败的时候,会导致CPU 升高。当然了,如果单K8S集群规模太大,一般都是拆分集群,不过随时监测下 Apiserver 的进程变化还是有必要的。
在监控Cadvisor、Docker、Kube-Proxy 的 Metric 时,我们一开始选择从 Apiserver Proxy 到节点的对应端口,统一设置比较方便,但后来还是改为了直接拉取节点,Apiserver 仅做服务发现。
十五、Rate 的计算逻辑
Prometheus 中的 Counter 类型主要是为了 Rate 而存在的,即计算速率,单纯的 Counter 计数意义不大,因为 Counter 一旦重置,总计数就没有意义了。
Rate 会自动处理 Counter 重置的问题,Counter 一般都是一直变大的,例如一个 Exporter 启动,然后崩溃了。本来以每秒大约10的速率递增,但仅运行了半个小时,则速率(x_total [1h])将返回大约每秒5的结果。另外,Counter 的任何减少也会被视为 Counter 重置。例如,如果时间序列的值为[5,10,4,6],则将其视为[5,10,14,16]。
Rate 值很少是精确的。由于针对不同目标的抓取发生在不同的时间,因此随着时间的流逝会发生抖动,query_range 计算时很少会与抓取时间完美匹配,并且抓取有可能失败。面对这样的挑战,Rate 的设计必须是健壮的。
Rate 并非想要捕获每个增量,因为有时候增量会丢失,例如实例在抓取间隔中挂掉。如果 Counter 的变化速度很慢,例如每小时仅增加几次,则可能会导致【假象】。比如出现一个 Counter 时间序列,值为100,Rate 就不知道这些增量是现在的值,还是目标已经运行了好几年并且才刚刚开始返回。
建议将 Rate 计算的范围向量的时间至少设为抓取间隔的四倍。这将确保即使抓取速度缓慢,且发生了一次抓取故障,您也始终可以使用两个样本。此类问题在实践中经常出现,因此保持这种弹性非常重要。例如,对于1分钟的抓取间隔,您可以使用4分钟的 Rate 计算,但是通常将其四舍五入为5分钟。
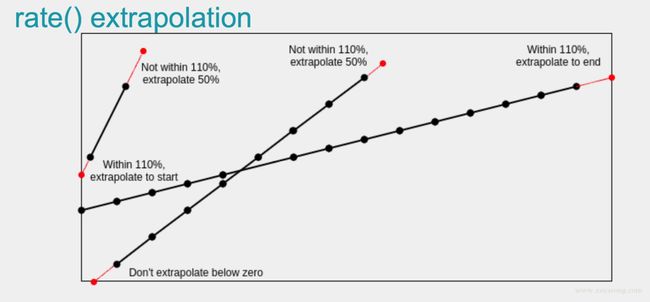
如果 Rate 的时间区间内有数据缺失,他会基于趋势进行推测,比如:
如有错误或其它问题,欢迎小伙伴留言评论、指正。如有帮助,欢迎点赞+转发分享。
欢迎大家关注民工哥的公众号:民工哥技术之路