Bank Credit_个人贷款违约预测
# 本次case主题:个人贷款违约预测模型
# 本案例使用一套真实的数据集演示贷款违约预测模型开发的全流程。这个流程就是数据挖掘项目的分析思路的直接体现,如下:
# 一、数据介绍
# 本案例所用数据来自一家银行的个人金融业务数据集,可以作为银行场景下进行个人客户业务分析和数据挖掘的示例。
# 这份数据中涉及5300个银行客户的100万笔交易,而且涉及700份贷款信息与近900张信用卡的数据。通过分析这份数据可以获取与银行服务相关的业务知识。
# 例如,对于提供增值服务的银行客户经理来说,希望明确哪些客户有更多的业务需求,而风险管理的业务人员可以及早发现贷款的潜在损失。
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from os import path
d = path.dirname(r"D:\2018_BigData\Python\Python_book\19Case\19_1Bankcredit")
# (1)账户表(Accounts):每条记录描述了一个账户(account_id)的静态信息,共4500条记录,如表所示。
accounts=pd.read_csv("D:/2018_BigData/Python/Python_book/19Case/19_1Bankcredit/accounts.csv",encoding="ANSI")
accounts.head(3)
# account_id —— 账户号,主键
# district_id —— 开户分行地区号,外键
# frequency —— 结算频度(月、周,交易之后马上)
# date —— 开户日期
| account_id | district_id | frequency | date | |
|---|---|---|---|---|
| 0 | 576 | 55 | 月结 | 1993-01-01 |
| 1 | 3818 | 74 | 月结 | 1993-01-01 |
| 2 | 704 | 55 | 月结 | 1993-01-01 |
# (2)顾客信息表(Clients):每条记录描述了一个客户(client_id)的特征信息,共5369条记录,如表所示。
clients=pd.read_csv("D:/2018_BigData/Python/Python_book/19Case/19_1Bankcredit/clients.csv",encoding="ANSI")
clients.head(3)
# client_id —— 客户号,主键
# sex —— 性别
# birth_date —— 出生日期
# district_id —— 地区号(客户所属地区),外键
| client_id | sex | birth_date | district_id | |
|---|---|---|---|---|
| 0 | 1 | 女 | 1970-12-13 | 18 |
| 1 | 2 | 男 | 1945-02-04 | 1 |
| 2 | 3 | 女 | 1940-10-09 | 1 |
# (3)权限分配表(Disp):每条记录描述了客户(client_id)和账户(account_id)之间的关系,以及客户操作账户的权限,共5369条记录,如表所示。
disp=pd.read_csv("D:/2018_BigData/Python/Python_book/19Case/19_1Bankcredit/disp.csv",encoding="ANSI")
disp.head(3)
# disp_id ——权限设置号,主键
# client_id —— 顾客号,外键
# account_id —— 账户号,外键
# type —— 权限类型,分为“所有者”和“用户”,只用“所有者”身份可以进行增值业务操作和贷款
| disp_id | client_id | account_id | type | |
|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 所有者 |
| 1 | 2 | 2 | 2 | 所有者 |
| 2 | 3 | 3 | 2 | 用户 |
# (4)支付订单表(Orders):每条记录代表一个支付命令,共6471条记录,如表所示。
order=pd.read_csv("D:/2018_BigData/Python/Python_book/19Case/19_1Bankcredit/order.csv",encoding="ANSI")
order.head(3)
# order_id ——订单号,主键
# account_id —— 发起订单的账户号,外键
# bank_to —— 收款银行,每家银行用两个字母来代表,用于脱敏信息
# account_to —— 收款客户号
# amount —— 金额,单位是“元”
# k_symbol —— 支付方式
| order_id | account_id | bank_to | account_to | amount | k_symbol | |
|---|---|---|---|---|---|---|
| 0 | 29405 | 3 | CD | 24485939 | 327.0 | NaN |
| 1 | 29413 | 8 | IJ | 93210345 | 6712.0 | NaN |
| 2 | 29430 | 24 | QR | 46086388 | 7641.0 | NaN |
# (5)交易表(Trans):每条记录代表每个账户(account_id)上的一条交易,共1056320条记录,如表所示。
trans=pd.read_csv("D:/2018_BigData/Python/Python_book/19Case/19_1Bankcredit/trans.csv",encoding="ANSI")
trans.head(3)
# trans_id ——交易序号,主键
# account_id —— 发起交易的账户号,外键
# date —— 交易日期
# type —— 借贷类型
# operation —— 交易类型
# amount —— 金额
# balance —— 账户余额
# k_symbol —— 交易特征
# bank —— 对方银行
# account ——对方账户号
| trans_id | account_id | date | type | operation | amount | balance | k_symbol | bank | account | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 695247 | 2378 | 1993-01-01 | 贷 | 信贷资金 | $700 | $700 | NaN | NaN | NaN |
| 1 | 171812 | 576 | 1993-01-01 | 贷 | 信贷资金 | $900 | $900 | NaN | NaN | NaN |
| 2 | 207264 | 704 | 1993-01-01 | 贷 | 信贷资金 | $1,000 | $1,000 | NaN | NaN | NaN |
# (6)贷款表(Loans):每条记录代表某个账户(account_id)上的一条贷款信息,共682条记录,如表所示。
loans=pd.read_csv("D:/2018_BigData/Python/Python_book/19Case/19_1Bankcredit/loans.csv",encoding="ANSI")
loans.head(3)
# loan_id ——贷款号,主键
# account_id —— 账户号,外键
# date —— 发放贷款日期
# amount —— 贷款金额,单位是“元”
# duration —— 贷款期限
# payments —— 每月归还额,单位是“元”
# status —— 还款状态(A表示合同终止,没问题;B表示合同终止,贷款没有支付;C表示合同处于执行期,至今正常;D表示合同处于执行期,为欠债状态。)
| loan_id | account_id | date | amount | duration | payments | status | |
|---|---|---|---|---|---|---|---|
| 0 | 5314 | 1787 | 1993-07-05 | 96396 | 12 | 8033 | B |
| 1 | 5316 | 1801 | 1993-07-11 | 165960 | 36 | 4610 | A |
| 2 | 6863 | 9188 | 1993-07-28 | 127080 | 60 | 2118 | A |
# (7)信用卡(Cards):每条记录描述了一个顾客号的信用卡信息,共892条记录,如表所示。
card=pd.read_csv("D:/2018_BigData/Python/Python_book/19Case/19_1Bankcredit/card.csv",encoding="ANSI")
card.head(3)
# card_id ——信用卡ID,主键
# disp_id —— 账户权限号,外键
# issued —— 发卡日期
# type —— 卡类型
| card_id | disp_id | issued | type | |
|---|---|---|---|---|
| 0 | 1005 | 9285 | 1993-11-07 | 普通卡 |
| 1 | 104 | 588 | 1994-01-19 | 普通卡 |
| 2 | 747 | 4915 | 1994-02-05 | 普通卡 |
# (8)人口地区统计表(District):每条记录描述了一个地区的人口统计学信息,共77条记录,如表所示。
district=pd.read_csv("D:/2018_BigData/Python/Python_book/19Case/19_1Bankcredit/district.csv",encoding="ANSI")
district.head(3)
# A1 = district_id 地区号,主键
# GDP GDP总量
# A4 居住人口
# A10 城镇人口比例
# A11 平均工资
# A12 1995年失业率
# A13 1996年失业率
# A14 1000人中有多少企业家
# A15 1995犯罪率(千人)
# a16 1996犯罪率(千人)
| A1 | GDP | A4 | A10 | A11 | A12 | A13 | A14 | A15 | a16 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 283894 | 1204953 | 100.0 | 12541 | 0.29 | 0.43 | 167 | 35.6 | 41.1 |
| 1 | 2 | 11655 | 88884 | 46.7 | 8507 | 1.67 | 1.85 | 132 | 12.1 | 15.0 |
| 2 | 3 | 13146 | 75232 | 41.7 | 8980 | 1.95 | 2.21 | 111 | 18.8 | 18.7 |
# 实际业务中的一个人可以拥有多个账户号(account_id),一个账户号(account_id)可以对应多个顾客(client_id),
# 即多个顾客共享一个账户号(account_id),但是每个账户号(account_id)的所有者(即最高权限者)只能是一个人。
# 账户号(account_id)与客户号(client_id)的对应关系,在表“Disposition”中进行展示;
# 表“Credit card”表述了银行提供给顾客(client_id)的服务,每个客户可以申请一张信用卡;
# 贷款为基于账户的服务,一个账户(account_id)在一个时点最多只能有一笔贷款。
# 总体思路
# “status(还款状态)”是主要指标,用于构造被预测变量(Y).
# 违约用1标识 如果Status=B
# 没有违约用0标识 如果Status=A
# 尚未结束用.标识 如果Status=C OR D
# 预测变量(X)需要从一下五个维度考虑:
# 1、贷款账户所关联客户的基本人口信息,包括:年龄、性别、教育等,主要表clients;
# 2、贷款账户所关联客户的基本社会属性(社会经济状态,SES),包括:收入、职业、居住社区的信息(人均收入、犯罪率等),district;
# 3、贷款账户所关联客户的交易行为数据,包括:产品订购情况order,交易情况trans,信用卡使用情况card;
# 4、贷款账户之间关联交易情况,交易情况trans。
# 构造X变量(以下格式不够明朗,此处仅做分析提示作用。如需直观,可复制粘贴进Excel表查看。)
# 变量说明 变量名 源数据变量 时间要求 构造方法说明
# 年龄 AGE Clients.birth_date 无 当前日期减去生日(理想状态是取贷款发放时年龄,但是可以忽略)
# 性别 Sex Clients.SEX 无 无
# …
# 居住社区平均工资 Pay_areamean District.A11 无 无(理想状态是取贷款发放时数值,但是可以忽略)
# 居住社区平均犯罪率 CRIME_areamean District.A15,District.A16 无 AVG(District.A15,District.A16)
# 居住社区犯罪率变化 CRIME_areaG District.A15,District.A16 无 (District.A16/District.A15-1)
# …
# 信用卡类型 CREDITCARD_type Cards.type 贷款发放时卡的类型 无
# …
# 从他行收款次数 t1 Trans.operation 贷款发放前3年间发生的实际次数 COUNT(Trans.operation="从他行收款")
# …
# 贷款发放时账户余额 balance trans.balance 贷款发放时账户余额 无
# 贷款金额 Loan_amount Loans.amount 无 无
# 贷款金额占账户余额比例 per_amount Loan_amount,balance 无 Loan_amount/balance
# 二、业务分析
# 在贷款审批方面,可以通过构建量化模型对客户的信用等级进行一定的区分。
# 在信贷资金管理方面,得知了每个账户的违约概率后,可以预估未来的坏账比例,及时做好资金安排;
# 也可以对违约可能性较高的客户更加频繁地“关怀”,及时发现问题,以避免损失。
# 在这个量化模型中,被解释变量为二分类变量,因此需要构建一个排序类分类模型。而排序类分类模型中最常使用的算法是逻辑回归。
# 三、数据理解
# 建模分析中,获取预测变量是最为艰难的,需要根据建模的主题进行变量的提取。其中第一步称为维度分析,即采集的数据涉及哪些大的方面,例如:
# “指标”分解成“属性”、“状态”、“行为”三个维度,然后这三个维度继续细分,如下:
# (1)属性:①性别?,②年龄?,……
# (2)状态:①资产总量?,②居住地区的失业率?,……
# (3)行为:①支出太大?,②……
# 有商业智能(BI)经验的人初次接触维度分析这个概念,会联想起联机分析处理(OLAP),这两个概念有相通之处。
# 后者是为业务分析服务的,因此,将信息归结到公司各级部门这个粒度上,例如某支行、分行或总行的某业务的数量。
# 数据挖掘的维度分析会更为广泛,其将数据按照研究对象进行信息提取。
# 比如,如果需要研究的是个人客户的消费行为,则需要将数据以客户粒度进行归结。
# 这样问题就来了,银行保存的客户数据非常多,如何去整理这些数据以获取合适的信息?单独从内部获取数据是否可以满足分析的需求?
# 为了回答这些问题,需要进行深入研究,以明确研究需要的客户信息。
# 不同的分析主题需要的客户信息是不同的,以下提供了一个信息获取的框架,在实际操作中可以按照以下4个方面进行考虑。
# (1)属性表征信息:
# 在分析个人客户时,又称人口统计信息。主要涉及最基本的性别、出生日期、年龄、教育程度、地域等信息。
# 【获取方式】办理业务时客户自报。
# 【相关度】低——偶尔表现出相关性,没有因果关系。
# 【运用场景】了解市场结构,其他方法的补充。
# 这类指标对客户的预测行为并不具有因果关系,只是根据历史数据统计可得到一些规律。
# 比如,随着客户年龄的提高,会对房贷、消费贷款、教育储蓄、个人理财等产品依次产生需求,但是年龄并不是对产品有需求的根本原因,其实婚龄才是其原因。只不过婚龄和年龄在同时期人群中是高度相关的。
# 同理,性别和某种业务表现的高相关性,很多也来自于外部世界对性别类型的一种行为期望。
# 对于银行、汽车4S店这类需要客户临柜填写表格的公司而言,是可以获取这方面的“真实”信息的,而对于电商而言,是难以获取“真实”信息的。
# 但是电商的分析人员也不必气馁,其实“真实”这个概念是有很多内涵的,根据电商数据虽然不能知道客户人口学上的“真实”年龄,但是根据其消费行为完全可以刻画出其消费心理上的“真实”年龄,而后者在预测客户需求和行为方面更有效。
# (2)行为信息:
# 根据客户的业务收集到的信息。比如:产品类型、购买频次、购买数量等。
# 【获取方式】客户办理业务、购买产品和接触渠道的记录。
# 【相关度】中——可以表现出相关性,但难以表现出因果关系。
# 【运用场景】产品定位,定价决策,交叉销售。
# 对于银行而言,行为数据仅限于业务数据,而电信公司可以获取的行为数据更加广泛,不仅可以获取通话行为、上网行为等业务信息,还可以获取周末出行、业务生活等个人行为信息。
# 获取的客户行为信息越多,对客户的了解越深入。在这方面,各类企业都具有很大的深挖潜力。
# 由于行为数据均为详细记录,数据庞大,而建模数据是一个样本只能有一条记录,因此需要对行为数据依照RFM方法进行行为信息的提取,比如过去一年的账户余额就是按照“M”计算得到的,这类变量成为一级衍生变量。
# 这还不够,比如,要看账户余额是否有增大趋势,就要计算过去一年每月的平均账户余额,然后计算前后两月平均账户余额增长率的均值,这个变量就称为二级衍生变量。
# 行为信息的提取可以按照RFM方法做到三级甚至四级衍生变量。
# (3)状态信息:
# 指客户的社会经济状态和社会网络关系信息。
# 【获取方式】办理业务时通过客户自报、访谈或在业务内容中获取。
# 【相关度】较高——表现出较强的相关性和一定的因果关系。
# 【运用场景】客户提升,价值深挖
# 了解了客户的社会关系,就了解了外界对该客户的期望,进而推断出其需求。通过深入分析,甚至可以推断出客户未来的需求,达到比客户更了解客户的状态。
# 在这方面,有些企业走在了前面,比如,电信企业通过通话和短信行为确定客户的交友圈,通过信号地理信息定位在客户的工作、生活和休闲区域,以此推测其工作类型和社交网络类型等。
# 有些企业刚刚起步,只是通过客户住址大致确定一下客户居住小区的档次,以确定其社会经济地位。
# 这类信息是值得每个以客户为中心的企业花时间和精力去深挖的。
# (4)利益信息:
# 利用客服、微信公众号、微博、论坛等刘妍信息,便捷地获取客户的态度、评价信息和诉求。比如,看重服务质量而对价格不敏感。
# 【获取方式】客户访谈、调研和社会化信息。
# 【相关度】高——直接的因果关系。
# 【运用场景】新产品开发等。
# 以上构建变量的准则是放之四海而皆准的,而具体到违约预测这个主题,还需要更有针对性的分析。
# 以往的研究认为,影响违约的主要因素有还款能力不足和还款意愿不足两个方面。还款意愿不足有可能是欲望大于能力、生活状态不稳定。
# 以上是概念分析,之后就需要量化,比如使用“资产余额的变异系数”作为生活状态不稳定的代理指标。
# 在建模过程中,有预测价值的变量基本都是衍生变量,比如:
# 一级衍生,比如最近一年每月的资产余额均值来自于交易数据中每月的账户余额。
# 二级衍生,比如年度资产余额的波动率来自于每月的资产余额均值。
# 三级衍生,比如资产余额的变异系数来自于资产余额的波动率除以资产余额均值。
# 大数据元年之前,在数据科学领域有一个不成文的规定:如果一个模型中二级以上的衍生变量不达到80%及以上的比例,是不好意思提交成果的。
# 老牌数据分析强公司(比如美国的第一资本)基本上是以每人每月20-50个衍生变量的速度积累十年才拥有所谓的万级别的衍生变量。
# 四、数据整理
# 以上介绍了维度分析要注意的主要方面,下面将根据维度分析的框架创建建模用变量。
# 不过我们不要期望可以创建全部四个维度的变量,一般创建前三个维度足矣。
# 首先生成被解释变量。
# 在贷款(Loans)表中还款状态(status)变量记录的客户的贷款偿还情况,
# 其中A代表合同终止且正常还款,B代表合同终止但是未还款,C代表合同未结束且正常还款,D代表合同未结束但是已经拖欠贷款了。
# 我们以此构造一个客户行为信用评级模型,以预测其他客户贷款违约的概率。
# 1、数据提取中的取数窗口
# 我们分析的变量按照时间变化情况可以分为动态变量和静态变量。属性变量(比如性别、是否90后)一般是静态变量;行为、状态和利益变量均属于动态变量。
# 动态变量还可以分为时点变量和区间变量。
# 状态变量(比如当前账户余额、是否破产)和利益变量(对某产品的诉求)均属于时点变量;行为变量(存款频次、平均账户余额的增长率)为区间变量。
# 模型框架:根据客户基本信息、业务信息、状态信息,来预估履约期内贷款客户未来一段时间内发生违约的可能。
# 在建模过程中,需要按照以下取数窗口提取变量:
# (1)放贷前一年--放款日,属观察窗口。其区间变量:比如平均账户余额、平均账户余额的增长率。
# (2)放款日--贷款结束,属预测窗口。其被解释变量:是否拖欠贷款。
# 注:放款日可以是静态变量,也可以是时点变量(取数位置为放贷日的前若干天中任意一个时点)。
# 其中有两个重要的时间窗口——观察窗口和预测窗口。
# 观察窗口是预测和收集供分析的自变量的时间段;
# 预测窗口是观测因变量变化的时间段,如果在这个时间段中出现显性状态(比如出现贷款拖欠)则将被解释变量设置为“1”,如果始终没有出现,则被解释变量设置为“0”。
# 取数窗口期的长短和模型易用性是一对矛盾体:
# 窗口期越短,缺失值越少,可分析的样本就越多、越便于使用。但是区间变量中单个变量的观测期越短,数据越不稳定,这样难以获得稳健的参数。
# 但是取数窗口越长,新的客户就会因为变量缺失而无法纳入研究样本。
# 因此取数窗口的长短是需要根据建模面临的任务灵活调整的
# 本案例中的观测窗口定为一年。
# 同样,观测窗口可长可短,取决于构建什么样的模型,以及目标变量是什么。
# 比如营销响应模型,预测窗口取三天至一周就够了;而信用卡信用违约模型,须要观测一年的时间。
# 通常,越长的预测窗口样本量越少;而预测窗口过短则会导致有些样本的被解释变量的最终状态还没有表现出来。
# 本次案例并非按照标准的信用评级模型取数窗口设置,如需深入学习,请参考《信用风险评分卡研究:基于SAS的开发与实施》
# 2、导入数据
# 利用pandas导入可用于建模的样本数据,利用Loans表生成被解释的变量。
import pandas as pd
import numpy as np
import os
os.chdir("D:/2018_BigData/Python/Python_book/19Case/19_1Bankcredit")
os.getcwd()
'D:\\2018_BigData\\Python\\Python_book\\19Case\\19_1Bankcredit'
# 导入数据,生成被解释变量
loanfile=os.listdir()
createVar=locals()
for i in loanfile:
if i.endswith("csv"):
createVar[i.split(".")[0]] = pd.read_csv(i,encoding="gbk")
print(i.split(".")[0])
accounts
card
clients
disp
district
loans
order
trans
# 以下代码创建被解释变量。
bad_good = {"B":1,"D":1,"A":0,"C":2}
loans["bad_good"] = loans.status.map(bad_good) # 活用map函数,学住:根据某列的值,对应生成新一列。
loans.head()
| loan_id | account_id | date | amount | duration | payments | status | bad_good | |
|---|---|---|---|---|---|---|---|---|
| 0 | 5314 | 1787 | 1993-07-05 | 96396 | 12 | 8033 | B | 1 |
| 1 | 5316 | 1801 | 1993-07-11 | 165960 | 36 | 4610 | A | 0 |
| 2 | 6863 | 9188 | 1993-07-28 | 127080 | 60 | 2118 | A | 0 |
| 3 | 5325 | 1843 | 1993-08-03 | 105804 | 36 | 2939 | A | 0 |
| 4 | 7240 | 11013 | 1993-09-06 | 274740 | 60 | 4579 | A | 0 |
# 3、表征信息
# 将所有维度的信息归结到贷款表(LOANS)上,每个贷款账户只有一条记录。寻找有预测能力的指标。
# 首先是寻找客户表征信息,如性别、年龄。
# 客户的人口信息保存在客户信息表(CLIENTS)中,但是该表是以客户为主键的,需要和权限分配表(DISP)相连接才可以获得账号级别的信息。
print(disp.columns)
print(clients.columns)
print(loans.columns)
Index(['disp_id', 'client_id', 'account_id', 'type'], dtype='object')
Index(['client_id', 'sex', 'birth_date', 'district_id'], dtype='object')
Index(['loan_id', 'account_id', 'date', 'amount', 'duration', 'payments',
'status', 'bad_good'],
dtype='object')
data2 = pd.merge(loans,disp,on="account_id",how="left")
data2 = pd.merge(data2,clients,on="client_id",how="left")
data2.head()
| loan_id | account_id | date | amount | duration | payments | status | bad_good | disp_id | client_id | type | sex | birth_date | district_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5314 | 1787 | 1993-07-05 | 96396 | 12 | 8033 | B | 1 | 2166 | 2166 | 所有者 | 女 | 1947-07-22 | 30 |
| 1 | 5316 | 1801 | 1993-07-11 | 165960 | 36 | 4610 | A | 0 | 2181 | 2181 | 所有者 | 男 | 1968-07-22 | 46 |
| 2 | 6863 | 9188 | 1993-07-28 | 127080 | 60 | 2118 | A | 0 | 11006 | 11314 | 所有者 | 男 | 1936-06-02 | 45 |
| 3 | 5325 | 1843 | 1993-08-03 | 105804 | 36 | 2939 | A | 0 | 2235 | 2235 | 所有者 | 女 | 1940-04-20 | 14 |
| 4 | 7240 | 11013 | 1993-09-06 | 274740 | 60 | 4579 | A | 0 | 13231 | 13539 | 所有者 | 男 | 1978-09-07 | 63 |
# 4、状态信息
# 提取借款人居住地情况,如居住地失业率等变量。与district表进行连接。
print(district.columns)
Index(['A1', 'GDP', 'A4', 'A10', 'A11', 'A12', 'A13', 'A14', 'A15', 'a16'], dtype='object')
data3 = pd.merge(data2,district,left_on="district_id",right_on="A1",how="left")
data3.head(2)
| loan_id | account_id | date | amount | duration | payments | status | bad_good | disp_id | client_id | ... | A1 | GDP | A4 | A10 | A11 | A12 | A13 | A14 | A15 | a16 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5314 | 1787 | 1993-07-05 | 96396 | 12 | 8033 | B | 1 | 2166 | 2166 | ... | 30 | 16979 | 94812 | 81.8 | 9650 | 3.38 | 3.67 | 100 | 15.7 | 14.8 |
| 1 | 5316 | 1801 | 1993-07-11 | 165960 | 36 | 4610 | A | 0 | 2181 | 2181 | ... | 46 | 14111 | 112709 | 73.5 | 8369 | 1.79 | 2.31 | 117 | 12.7 | 11.6 |
2 rows × 24 columns
# 5、行为信息
# 根据客户的账户变动的行为信息,考察借款人还款能力,如账户平均余额、余额的标准差、变异系数、平均入账和平均支出的比例、贷存比等。
# 首先将贷款表和交易标按照account_id内连接。
print(trans.columns)
Index(['trans_id', 'account_id', 'date', 'type', 'operation', 'amount',
'balance', 'k_symbol', 'bank', 'account'],
dtype='object')
data_4temp1 = pd.merge(loans[["account_id","date"]],
trans[["account_id","type","amount","balance","date"]],
on = "account_id")
data_4temp1.columns = ["account_id","date","type","amount","balance","t_date"]
data_4temp1 = data_4temp1.sort_values(by=["account_id","t_date"])
data_4temp1.head(3)
| account_id | date | type | amount | balance | t_date | |
|---|---|---|---|---|---|---|
| 10020 | 2 | 1994-01-05 | 贷 | $1,100 | $1,100 | 1993-02-26 |
| 10021 | 2 | 1994-01-05 | 贷 | $20236 | $21336 | 1993-03-12 |
| 10022 | 2 | 1994-01-05 | 贷 | $3,700 | $25036 | 1993-03-28 |
# 然后将来自贷款表和交易表中的两个字符串类型的日期变量转换为日期,为窗口取数做准备。
data_4temp1["date"] = pd.to_datetime(data_4temp1["date"])
data_4temp1["t_date"] = pd.to_datetime(data_4temp1["t_date"])
# 账户余额和交易余额为字符变量,有千分位符,需要进行数据清洗,并转换为数值类型。
data_4temp1["balance2"]=data_4temp1["balance"].map(lambda x: int("".join(x[1:].split(","))))
data_4temp1["amount2"]=data_4temp1["amount"].map(lambda x: int("".join(x[1:].split(","))))
data_4temp1.head(3)
| account_id | date | type | amount | balance | t_date | balance2 | amount2 | |
|---|---|---|---|---|---|---|---|---|
| 10020 | 2 | 1994-01-05 | 贷 | $1,100 | $1,100 | 1993-02-26 | 1100 | 1100 |
| 10021 | 2 | 1994-01-05 | 贷 | $20236 | $21336 | 1993-03-12 | 21336 | 20236 |
| 10022 | 2 | 1994-01-05 | 贷 | $3,700 | $25036 | 1993-03-28 | 25036 | 3700 |
# 以下这条语句实现了窗口取数,只保留了贷款日期前365天至贷款前1天内的交易数据。
import datetime
# data_4temp2 = data_4temp1[
# data_4temp1.date>date_4temp1.t_date][
# data_4temp1.date
# 报错NameError: name 'date_4temp1' is not defined
# 换一种方式:
# data_4temp2 = data_4temp1.loc[data_4temp1["date"].isin([date_4temp1["t_date"],date_4temp1["t_date"]+datetime.timedelta(days=365)])
# 报另一个错:SyntaxError: unexpected EOF while parsing
# 换另一种方式,同时把第一行的data_4temp1复制替换掉后两行的data_4temp1,成功。
# data_4temp2 = data_4temp1[
# data_4temp1["date"]>data_4temp1["t_date"]][
# data_4temp1["date"]
# 一开始可能只是后两行的data_4temp1格式细节输入错误,复制粘贴改回,重新运行,成功。
data_4temp2 = data_4temp1[
data_4temp1.date>data_4temp1.t_date][
data_4temp1.date<data_4temp1.t_date+datetime.timedelta(days=365)]
data_4temp2.head()
| account_id | date | type | amount | balance | t_date | balance2 | amount2 | |
|---|---|---|---|---|---|---|---|---|
| 10020 | 2 | 1994-01-05 | 贷 | $1,100 | $1,100 | 1993-02-26 | 1100 | 1100 |
| 10021 | 2 | 1994-01-05 | 贷 | $20236 | $21336 | 1993-03-12 | 21336 | 20236 |
| 10022 | 2 | 1994-01-05 | 贷 | $3,700 | $25036 | 1993-03-28 | 25036 | 3700 |
| 10023 | 2 | 1994-01-05 | 贷 | $14 | $25050 | 1993-03-31 | 25050 | 14 |
| 10024 | 2 | 1994-01-05 | 贷 | $20236 | $45286 | 1993-04-12 | 45286 | 20236 |
# 以下语句计算了每个贷款账户贷款前一年的:
# 平均账户余额(代表财富水平)、账户余额的标准差(代表财富稳定情况)和变异系数(代表财富稳定的另一个指标)。
data_4temp3 = data_4temp2.groupby("account_id")["balance2"].agg([("avg_balance","mean"),("stdev_balance","std")])
data_4temp3["cv_balance"] = data_4temp3[["avg_balance","stdev_balance"]].apply(lambda x: x[1]/x[0],axis=1)
data_4temp3.head(3)
| avg_balance | stdev_balance | cv_balance | |
|---|---|---|---|
| account_id | |||
| 2 | 32590.759259 | 12061.802206 | 0.370099 |
| 19 | 25871.223684 | 15057.521648 | 0.582018 |
| 25 | 56916.984496 | 21058.667949 | 0.369989 |
# 以下语句计算平均入账和平均支出的比例。
# 首先以上一步时间窗口取数得到的数据集为基础,对每个账户的“借-贷”类型进行交易金额汇总。
type_dict = {"借":"out","贷":"income"}
data_4temp2["type1"]=data_4temp2.type.map(type_dict)
data_4temp4=data_4temp2.groupby(["account_id","type1"])[["amount2"]].sum()
data_4temp4.head(3)
| amount2 | ||
|---|---|---|
| account_id | type1 | |
| 2 | income | 276514 |
| out | 153020 | |
| 19 | income | 254255 |
data_4temp4=data_4temp4.reset_index()
data_4temp4.head(3)
| account_id | type1 | amount2 | |
|---|---|---|---|
| 0 | 2 | income | 276514 |
| 1 | 2 | out | 153020 |
| 2 | 19 | income | 254255 |
# 对于上一步汇总后的数据,每个账号会有两条记录,需要对其进行拆分列操作,将每个账户的两条观测转换为每个账户一条观测。
# 以下语句中使用pd.pivot_table函数进行堆叠列。
data_4temp5 = pd.pivot_table(data_4temp4, values = "amount2", index = "account_id", columns = "type1")
data_4temp5.fillna(0,inplace = True)
data_4temp5["r_out_in"] = data_temp5[["out","income"]].apply(lambda x: x[0]/x[1],axis=1)
data_4temp5.head(3)
| type1 | income | out | r_out_in |
|---|---|---|---|
| account_id | |||
| 2 | 276514.0 | 153020.0 | 0.553390 |
| 19 | 254255.0 | 198020.0 | 0.778824 |
| 25 | 726479.0 | 629108.0 | 0.865969 |
# 以下语句将分别计算的平均账户余额、账户余额的标准差、变异系数、平均入账和平均支出的比例等变量与之前的data3数据合并。
data4 = pd.merge(data3,data_4temp3,left_on="account_id",right_index=True,how="left")
data4 = pd.merge(data4,data_4temp5,left_on="account_id",right_index=True,how="left")
data4.head(3)
| loan_id | account_id | date | amount | duration | payments | status | bad_good | disp_id | client_id | ... | A13 | A14 | A15 | a16 | avg_balance | stdev_balance | cv_balance | income | out | r_out_in | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5314 | 1787 | 1993-07-05 | 96396 | 12 | 8033 | B | 1 | 2166 | 2166 | ... | 3.67 | 100 | 15.7 | 14.8 | 12250.000000 | 8330.866301 | 0.680071 | 20100.0 | 0.0 | 0.000000 |
| 1 | 5316 | 1801 | 1993-07-11 | 165960 | 36 | 4610 | A | 0 | 2181 | 2181 | ... | 2.31 | 117 | 12.7 | 11.6 | 43975.810811 | 25468.748605 | 0.579154 | 243576.0 | 164004.0 | 0.673318 |
| 2 | 6863 | 9188 | 1993-07-28 | 127080 | 60 | 2118 | A | 0 | 11006 | 11314 | ... | 2.89 | 132 | 13.3 | 13.6 | 30061.041667 | 11520.127013 | 0.383224 | 75146.0 | 54873.0 | 0.730219 |
3 rows × 30 columns
# 最后计算贷存比、贷收比。
data4["r_lb"] = data4[["amount","avg_balance"]].apply(lambda x: x[0]/x[1],axis=1)
data4["r_lincome"] = data4[["amount","income"]].apply(lambda x: x[0]/x[1],axis=1)
# 五、建立分析模型
# 这部分是从信息中获取知识的过程。数据挖掘方法分为分类和描述两大类,其中该预测账户的违约情况属于分类模型。使用逻辑回归为刚才创建的模型建模。
# (1)提取状态为C的样本用于预测。其他样本随机采样,简历训练集与测试集。
data_model = data4[data4.status != "C"]
for_predict = data4[data4.status == "C"]
train = data_model.sample(frac=0.7,random_state=1235).copy()
test = data_model[~data_model.index.isin(train.index)].copy()
print("训练集样本量:%i\n 测试集样本量:%i"%(len(train),len(test)))
训练集样本量:234
测试集样本量:100
# (2)使用向前逐步法进行逻辑回归建模。
# 首先定义向前法函数
# 向前法
# 此自定义函数参照书本提供的代码,但是依据Python的风格,应该有相应的内置函数?晚点再找。
import statsmodels.api as sm
import statsmodels.formula.api as smf
def forward_select(data, response):
import statsmodels.api as sm
import statsmodels.formula.api as smf
remaining = set(data.columns)
remaining.remove(response)
selected = []
current_score, best_new_score = float('inf'), float('inf')
while remaining:
aic_with_candidates=[]
for candidate in remaining:
formula = "{} ~ {}".format(
response,' + '.join(selected + [candidate]))
aic = smf.glm(
formula=formula, data=data,
family=sm.families.Binomial(sm.families.links.logit)
).fit().aic
aic_with_candidates.append((aic, candidate))
aic_with_candidates.sort(reverse=True)
best_new_score, best_candidate=aic_with_candidates.pop()
if current_score > best_new_score:
remaining.remove(best_candidate)
selected.append(best_candidate)
current_score = best_new_score
print ('aic is {},continuing!'.format(current_score))
else:
print ('forward selection over!')
break
formula = "{} ~ {} ".format(response,' + '.join(selected))
print('final formula is {}'.format(formula))
model = smf.glm(
formula=formula, data=data,
family=sm.families.Binomial(sm.families.links.logit)
).fit()
return(model)
data4.columns # 用于下一条语句快速取列名
Index(['loan_id', 'account_id', 'date', 'amount', 'duration', 'payments',
'status', 'bad_good', 'disp_id', 'client_id', 'type', 'sex',
'birth_date', 'district_id', 'A1', 'GDP', 'A4', 'A10', 'A11', 'A12',
'A13', 'A14', 'A15', 'a16', 'avg_balance', 'stdev_balance',
'cv_balance', 'income', 'out', 'r_out_in', 'r_lb', 'r_lincome'],
dtype='object')
# 使用向前逐步法进行逻辑回归建模。
candidates = ["bad_good",'A1', 'GDP', 'A4', 'A10', 'A11', 'A12','amount', 'duration','A13', 'A14', 'A15', 'a16', 'avg_balance', 'stdev_balance',
'cv_balance', 'income', 'out', 'r_out_in', 'r_lb', 'r_lincome']
data_for_select = train[candidates]
lg_ml = forward_select(data=data_for_select,response="bad_good")
lg_ml.summary().tables[1]
aic is 177.8135076281174,continuing!
forward selection over!
final formula is bad_good ~ r_lb
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -3.3598 | 0.390 | -8.614 | 0.000 | -4.124 | -2.595 |
| r_lb | 0.5791 | 0.088 | 6.559 | 0.000 | 0.406 | 0.752 |
# 通过以上语句得到相关结果。
# 上表列出了逻辑回归的模型参数。
# 其中申请贷款前一年的贷存比(r_lb)与违约正相关。
# (3)模型效果评估。
# 以下使用测试数据进行模型效果评估。此处调用了 scikit-learn 的评估模块绘制 ROC 曲线。
import sklearn.metrics as metrics
import matplotlib.pyplot as plt
fpr, tpr, th = metrics.roc_curve(test.bad_good, lg_ml.predict(test))
plt.figure(figsize=[6,6])
plt.plot(fpr, tpr, "b--")
plt.title("ROC curve")
plt.show()
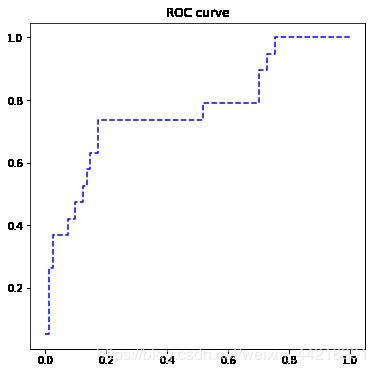
print('AUC = %.4f' %metrics.auc(fpr, tpr))
AUC = 0.7667
# 可以看到模型的ROC曲线离左上角比较远,其曲线下面积(AUC)为0.7667,这说明模型的排序能力还有待提高。不过也可以先暂且用用。
# 六、模型运用
# 在这个案例中,贷款状态为C的账户是尚没有出现违约且合同未到期的客户。这些贷款客户中有些人的违约可能性较高,需要业务人员重点关注。
# 一旦发现问题时,可以及时处理,挽回损失。
# 可以通过以下语句得到每款贷款的违约概率。
for_predict["prob"] = lg_ml.predict(for_predict)
for_predict[["account_id","prob"]].head()
| account_id | prob | |
|---|---|---|
| 27 | 1071 | 0.477101 |
| 36 | 5313 | 0.734056 |
| 47 | 10079 | 0.157970 |
| 48 | 10079 | 0.157970 |
| 49 | 5385 | 0.404954 |
# 输出结果如上表。
# 这里需要强调的是,此处的概率仅是代表违约可能性的相对值,并不代表其真实违约概率。
# 比如预测概率为0.73的违约可能性高于几成,这已经足够了,因为业务人员知道哪些客户为重点关注的即可。
建模分析尾声,直接截图。
# 七、流程回顾
# 本案例中,我们遵照数据挖掘项目通用的流程——CRISP-DM进行建模。最后回顾一下本案例的建模流程。
# (1)业务分析:需要构建一个分类模型预测每个客户的违约概率,其实是对客户的信用进行一个排序。分类模型有很多种,其中逻辑回归是最常用到的。
# (2)数据解读:从业务需求出发,了解、熟悉现有的数据结构、数据质量等信息。主要寻找对客户违约成本、还款意愿、还款能力(资产规模和稳定性)有代表意义的变量。
# (3)数据准备:结合数据的内在价值与业务分析,提取各类有价值的信息,构建被解释变量和解释变量。
# (4)模型构建与评价:该步骤按照SEMMA标准算法,分为数据采样、变量分布探索、修改变量、构建逻辑回归、评价模型的优劣。
# (5)模型监控:当模型上线后,对模型的表现进行长期监控,主要检验模型预测准确性与数据的稳定性。
# 在实际的工作中,上面提供的流程第1~3步并不一定一次性做好,很多时候这部分需要反复验证、反复解读。
# 因为我们往往需要多次分析审核,所以可以较好地理解拿到的数据,并且能够识别出数据中的异常或错误的内容。
# 而此部分若纳入了错误的数据,则会导致后面的步骤,如建模等工作完全没有意义。
# 最后说明:本次案例来源于书籍《Python数据科学·技术详解与商业实践》第19章《商业数据挖掘案例》。在此感谢。
# 同时抛出一个疑问:
# 本次实践中,在“使用向前逐步法进行逻辑回归建模”这一步,得到结果(逻辑回归的模型参数)仅有:
# “申请贷款前一年的贷存比(r_lb)”与违约正相关。
# 而在《Python数据科学》一书中,得到的模型参数结果有多个:
# 申请贷款前一年的贷存比(r_lb)、存款余额的标准差(stdev_balace)、贷款期限(duration)与违约正相关;
# 存款余额的均值(avg_balance)、贷款者当地1000人中共有多少企业家(A14)与违约负相关。
# 书中所得回归模型系数正负号均符合我们的预期,而且均显著。
# 另外,ROC curve和 AUC 的模型评估中,书中也是达到了0.9435的高拟合度,而本次实践只有0.7667.
# 那,虽然用了random随机函数来分解训练集,结果也不至于相差这么大。是什么原因呢?
# 如果有大神路过解答一二,就感激不尽了。。
# 读者如果有兴趣,也可以思考研究一下。